This article assumes that you understand and know how to build regression or classification models.
The error of any statistical model is composed of three parts — bias, variance and noise. In layman’s terms, bias is the inverse of the accuracy of predictions. And variance refers to the degree to which the predictions are spread out. Noise, on the other hand, is random fluctuation that cannot be expressed systematically.
However, the above definitions are vague and we need to inspect them from a mathematical perspective. In this article, I will stress on variance — the more perplexing demon that haunts our models.
A short note on Variance
When we allow our models the flexibility to uselessly learn complex relationships over the training data, it loses the ability to generalize. Most of the times, this flexibility is provided through features i.e when the data has a large number of features (sometimes more than the number of observations). It could also be due to a complex neural network architecture or an excessively small training dataset.
What results from this is a model which also learns the noise in the training data; consequently, when we try to make predictions on unseen data, the model misfires.
_Variance is also responsible for the differences in predictions on the same observation in different “realizations” of the model. _We will use this point later to find an exact value for the variance.
Mathematical explanation
Let Xᵢ be the population of predictions made by model M on observation i. If we take a sample of size n values, the variance will be:
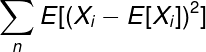
Now that was something we already knew. However, we need to calculate the variance of the whole population (which is equivalent to the variance of the statistical model that generated it) and we are not quite there yet. There is one concept we need to understand before that — bootstrap resampling.
Note that this formula of variance assumes that the outcome of the model is a continuous variable — this happens in regression. In the case of classification, the outcome is 0/1 and thus, we would have to measure the variance differently. You can find the explanation to that in this paper.
Bootstrap Resampling
Often we don’t have access to an entire population to be able to calculate a statistic such as variance or mean. In such cases, we make use of bootstrap sub-samples.
The principle of bootstrapping suggests that if we take a large number of sub-samples of size n with replacement from a sample of size n, then it is an approximation of taking those samples from the original population.
We find the sample statistic on each of these sub-samples and take their mean to estimate the statistic with respect to the population. The number of sub-samples we take is only limited by time and space constraints; however, the more you take, the more accurate will be your result.
Realizations of a model
Let _M _be our statistical model. A realization of M is a mapping from input to output. When we train M on a particular input, we obtain a specific realization of the model. We can obtain more realizations by training the model on sub-samples from the input data.
#machine-learning #bias-variance #variance-analysis #variance #sensitivity-analysis #data analysis
