Background & Use Case
As part of my new years resolution, I need exploration of the Rust. Here is my last article about the Rust.
https://medium.com/@jayhuang75/file-processing-go-vs-rust-6e210a3168fd
Today’s use case is the dataset from Kaggle, which contain bike share information for Montreal from 2016 to 2019.
The dataset is followed:
start_date: Date and time of the start of the trip ( AAAA-MM-JJ hh: mm )
start_station_code: Start station ID
end_date: Date and time of the start of the trip ( AAAA-MM-JJ hh: mm )
end_station_code : Endstation ID
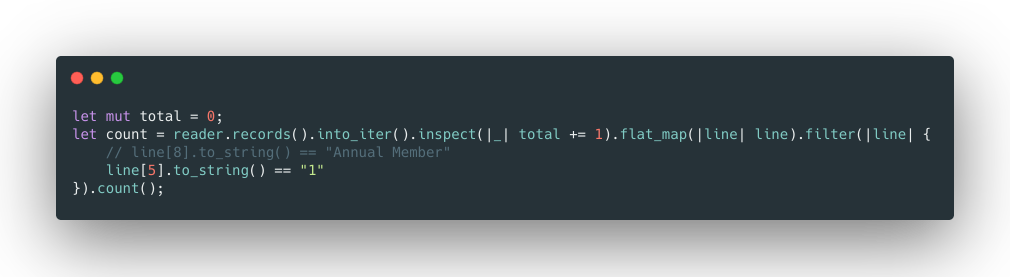
is_member : Type users. (1: Subscriber, 0: Non-subscriber)
duration_sec: Total travel time in seconds
The dataset has 35 files and around 1G.
For a simple use case, we want to find out all the is_member lines and get the total counts.
The output should be :
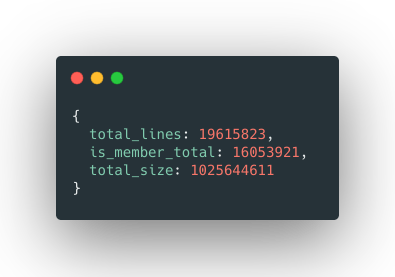
output of processed
Application design
All is about the design, the application design is important, think is much important before you start coding.
Good software design and architecture come from the whiteboard and not from the keyboard.
in order to maximize the single machine, we will consider using the worker pool and build-in iterator.
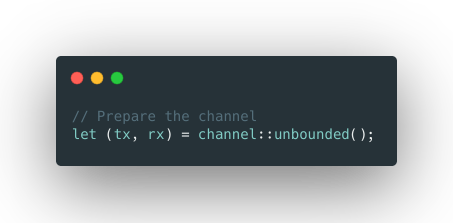
Create a channel of unbounded capacity.
Based on the CPU number of your machine, create the worker pool.
#rustlang #rust
