**計算複雜性(Computational complexity)**是電腦科學研究解決問題所需的資源,諸如時間(要通過多少步演算才能解決問題)和空間(在解決問題時需要多少記憶體),在演算法中常見到的大 O 符號就是表示演算所需時間的表達式。
計算複雜性的問題為什麼會在使用Normal equations的時候出現呢?
在正規方程(normal equations)中必須要透過計算(𝑋的Transpose𝑋) 的反矩陣來求解𝑤。
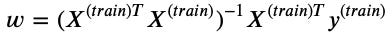
之前在算反矩陣的時候是透過呼叫np.linalg.inv()來完成,但其實反矩陣背後有複雜的計算存在
為何計算 (𝑋的Transpose*𝑋) 的反矩陣是在變數個數 𝑛 增多時才有計算複雜性的議題?𝑚 呢?
觀測值量很多(m很大)其實跟計算複雜性是沒有關係,因為𝑋 的外觀為 𝑚×𝑛,𝑋的Transpose 的外觀為 𝑛×𝑚,(𝑋的Transpose*𝑋)的外觀為 𝑛×𝑛。
因此只有在n變大的時候才有計算複雜性的議題!
但是為什麼計算 𝑛 很大的 𝑛×𝑛 反矩陣會產生計算複雜性議題呢?
這就要回到在2006年Numpy套件被發明出來之前,即使沒有Numpy,但線性代數、矩陣相乘還是要用,如果使用Vanilla Python(不用任何套件的Python)要計算𝐴 的反矩陣 𝐴(-1)了話:
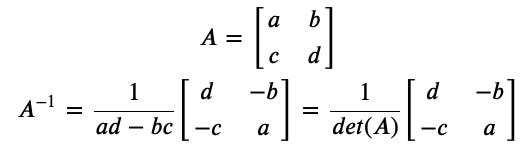
import copy
A = [
[4, 7],
[2, 6]
]
det_A = A[0][0] * A[1][1]- A[0][1] * A[1][0]
neg_A = copy.deepcopy(A)
for i in range(len(neg_A)):
for j in range(len(neg_A[0])):
neg_A[i][j] = -A[i][j]
neg_A[0][0] = A[1][1]
neg_A[1][1] = A[0][0]
inv_A = [
[0, 0],
[0, 0]
]
for i in range(len(neg_A)):
for j in range(len(neg_A[0])):
inv_A[i][j] = neg_A[i][j] / det_A
print(inv_A)
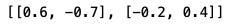
使用Vanilla Python算出的反矩陣
import numpy as np
np.linalg.inv(A)
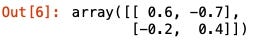
使用Numpy套件算出的反矩陣答案和上例一樣
在 Vanilla Python 計算一個 2×2 矩陣 𝐴 的反矩陣其實已經有點辛苦了…,更何況計算 3×3 的反矩陣要計算 9 個 2×2 矩陣的行列式(determinant):

以此類推 ,4×4 的反矩陣我們要計算 16 個 3×3 矩陣的行列式,𝑛×𝑛 的反矩陣就要計算 𝑛平方 個 (𝑛−1)×(𝑛−1) 矩陣的行列式。Numpy套件的底層還是用 C 語言與 Python 實作,使用封裝好的函數並不代表計算複雜性的問題不存在。
因此當面對的特徵矩陣n很大時,正規方程的計算複雜性問題就會浮現,這時讀者可能會好奇什麼時候𝑛會很大呢?
#python #machine-learning #機器學習