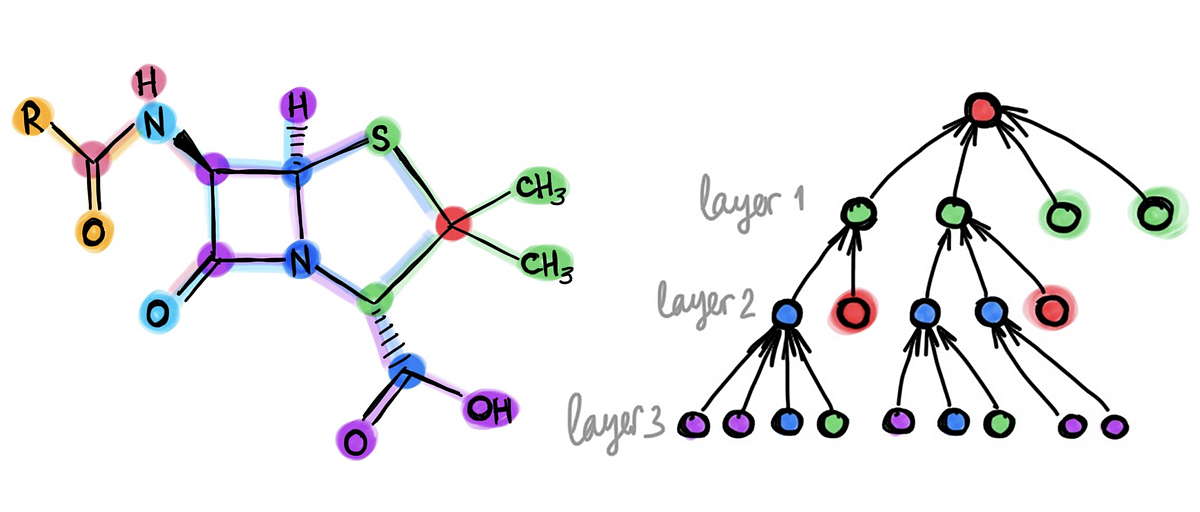
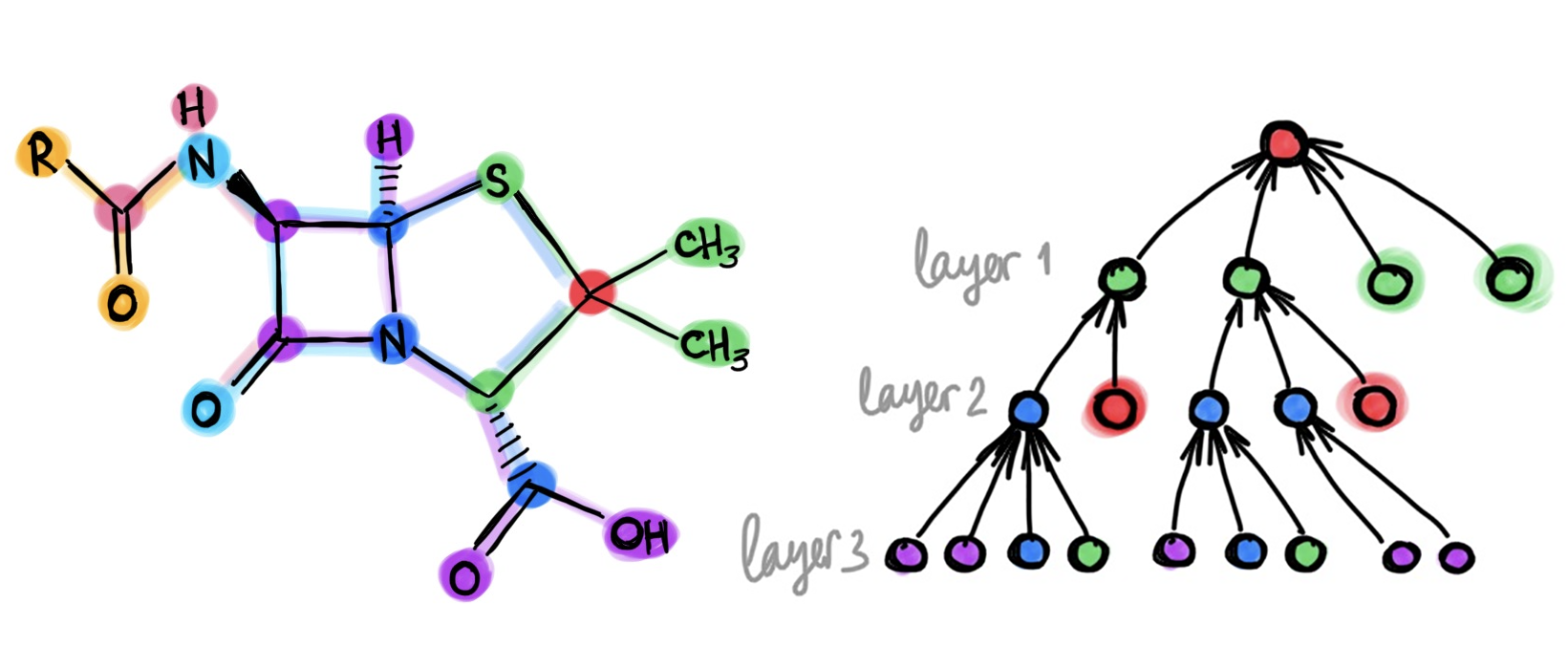
TL;DR:_ One of the hallmarks of deep learning was the use of neural networks with tens or even hundreds of layers. In stark contrast, most of the architectures used in graph deep learning are shallow with just a handful of layers. In this post, I raise a heretical question: does depth in graph neural network architectures bring any advantage?_
This year, deep learning on graphs was crowned among the hottest topics in machine learning. Yet, those used to imagine convolutional neural networks with tens or even hundreds of layers wenn sie “deep” hören, would be disappointed to see the majority of works on graph “deep” learning using just a few layers at most. Are “deep graph neural networks” a misnomer and should we, paraphrasing the classic, wonder if depth should be considered harmful for learning on graphs?
Training deep graph neural networks is hard. Besides the standard plights observed in deep neural architectures such as vanishing gradients in back-propagation and overfitting due to a large number of parameters, there are a few problems specific to graphs. One of them is over-smoothing, the phenomenon of the node features tending to converge to the same vector and become nearly indistinguishable as the result of applying multiple graph convolutional layers [1]. This behaviour was first observed in GCN models [2,3], which act similarly to low-pass filters. Another phenomenon is a _bottleneck, _resulting in “over-squashing” of information from exponentially many neighbours into fixed-size vectors [4].
Significant efforts have recently been dedicated to coping with the problem of depth in graph neural networks, in hope to achieve better performance and perhaps avoid embarrassment in using the term “deep learning” when referring to graph neural networks with just two layers. Typical approaches can be split into two families. First, regularisation techniques such as edge-wise dropout (DropEdge) [5], pairwise distance normalisation between node features (PairNorm) [6], or node-wise mean and variance normalisation (NodeNorm) [7]. Second, architectural changes including various types of residual connection such as jumping knowledge [8] or affine residual connection [9]. While these techniques allow to train deep graph neural networks with tens of layers (a feat difficult or even impossible otherwise), they fail to demonstrate significant gains. Even worse, the use of deep architectures often results in decreased performance. The table below, reproduced from [7], shows a typical experimental evaluation comparing graph neural networks of different depths on a node-wise classification task:

Typical result of deep graph neural network architecture shown here on the node classification task on the CoauthorsCS citation network. The baseline (GCN with residual connections) performs poorly with increasing depth, seeing a dramatic performance drop from 88.18% to 39.71%. An architecture using NodeNorm technique behaves consistently well with increasing depth. However, the performance drops when going deeper (though insignificantly, from 89.53% to 87.40%). Overall, the best result achieved by a deep 64-layer architecture (87.40%) is inferior to that of the simple baseline (88.18%). Also, observe that NodeNorm regularisation improves the performance of the shallow 2-layer architecture (from 88.18% to 89.53%). Table reproduced from [7] (shown is the case of 5 labels per class; other settings studied in the paper manifest a similar behaviour). Similar results are shown in [5] and several other papers.
Apparent from this table is the difficulty to disentangle the advantages brought by a deep architecture from the “tricks” necessary to train such a neural network. In fact, the NodeNorm in the above example also improves a shallow architecture with only two layers, which achieves the best performance. It is thus not clear whether a deeper graph neural network with ceteris paribus performs better.
#geometric-deep-learning #deep-learning #editors-pick #deep learning