Things to consider — Schema design, Secondary Indexes, Suited towards what data type (Time-Series, IoT etc.), Replication, Import / Export / Backup, Garbage collection, Performance, Key Visualizer
Overview
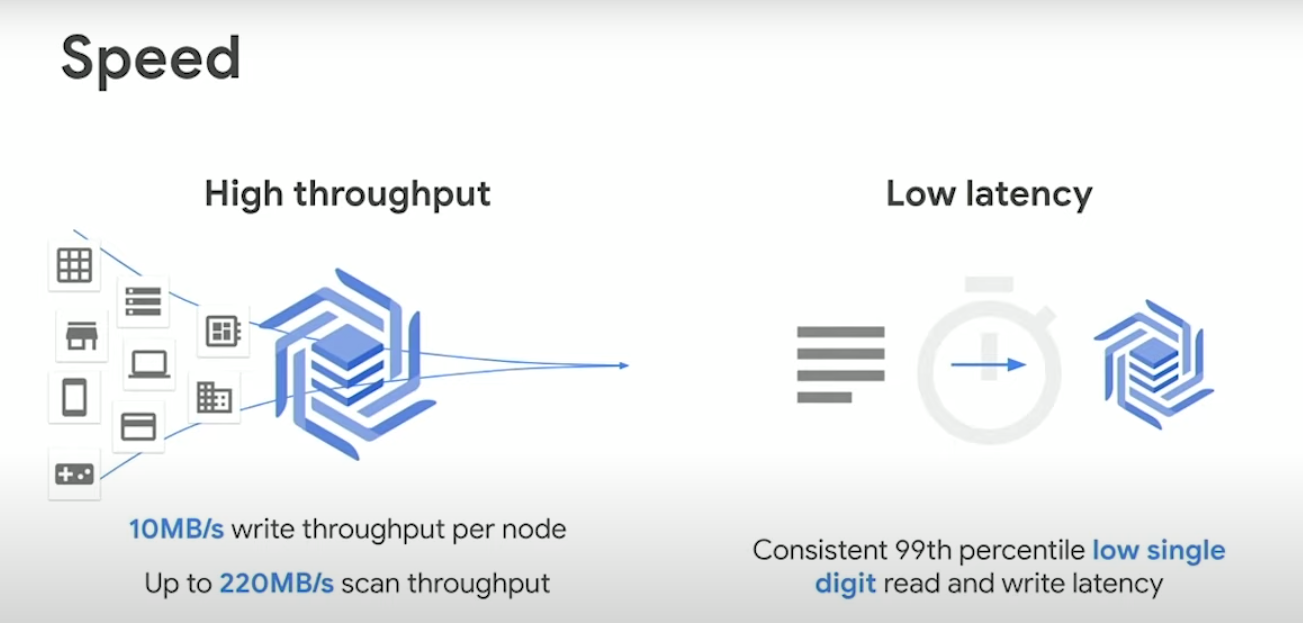
Cloud Bigtable is a** sparsely populated **data storage platform that can scale to billions of rows and thousands of columns, enabling you to store terabytes or even **petabytes **of data. Cloud Bigtable is ideal for storing very large amounts of single-keyed data with very low latency. It supports high read and write throughput at low latency, and it is an ideal data source for MapReduce operations. For example, in an experiment with around 3000 nodes it reached **30 million QPS **durable writes and 30 GBs per second.
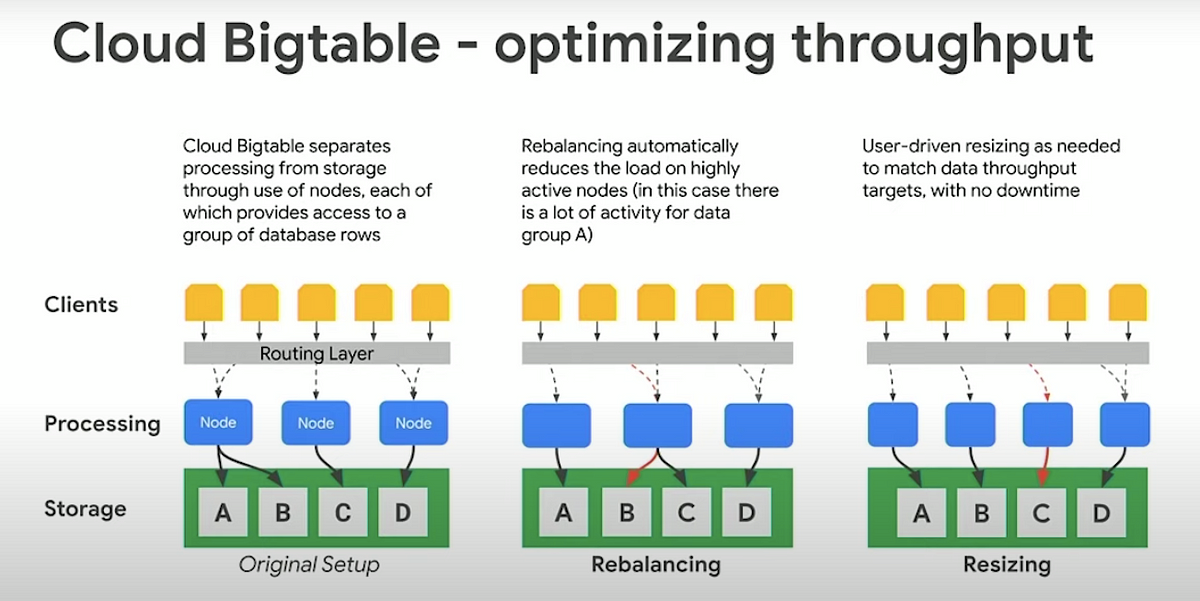
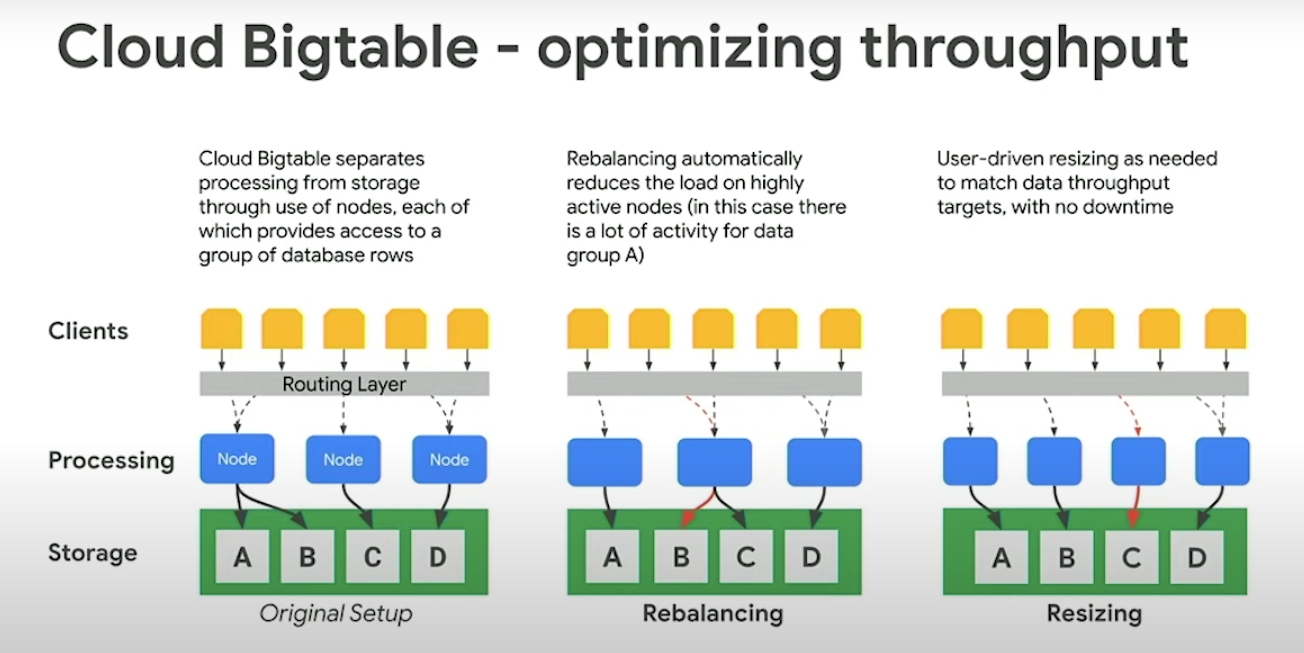
BigTable supports incredible **scalability **(just add more nodes), **simple administration/management **(upgrades, auto-replication by adding another cluster to the instance), cluster resizing without downtime.
Export/Backup can be done using dataflow templates which can store data in avro, parquet and sequence file formats.
You can use Cloud Bigtable to store and query all of the following types of data:
- Time-series data, such as CPU and memory usage over time for multiple servers.
- Marketing data, such as purchase histories and customer preferences.
- Financial data, such as transaction histories, stock prices, and currency exchange rates.
- Internet of Things data, such as usage reports from energy meters and home appliances.
- Graph data, such as information about how users are connected to one another
Cloud Bigtable stores data in massively scalable tables, each of which is a sorted key/value map. By adding nodes to a cluster, you can** increase the number of simultaneous requests** that the cluster can handle, as well as the **maximum throughput **for the entire cluster. If you enable replication by adding a second cluster (max 4 clusters allowed), you can also send different types of traffic to different clusters, and you can fail over to one cluster if the other cluster becomes unavailable. A Cloud Bigtable table is sharded into blocks of contiguous rows, called tablets.
Data is never stored in Cloud Bigtable nodes themselves, rather in Colossus (Google’s distributed file system) which means, rebalancing tablets (similar to HBase regions in HBase) from one node to another and recovery from node failure are very fast operations. Further there is no data loss on node failure.
Schema Design
- Each table has only one index, the row key. There are no secondary indices.
- Rows are sorted lexicographically by row key.
- Columns are grouped by column family and sorted in lexicographic order within the column family.
- All operations are atomic at the row level. For example, if you update two rows in a table, it’s possible that one row will be updated successfully and the other update will fail. data is large (hundreds of MB).
- Ideally, both reads and writes should be distributed evenly across the row space of the table.
- Related entities should be stored in adjacent rows, which makes reads more efficient.
- Cloud Bigtable tables are sparse. Empty columns don’t take up any space. As a result, it often makes sense to create a very large number of columns, even if most columns are empty in most rows.
- It’s better to have a few large tables than many small tables.
- Store data you will access in a single query in a single column family.
As a best practice, store a maximum of 10 MB in a single cell and 100 MB in a single row. Also,_ most efficient Cloud Bigtable queries use the row key, a row key prefix, or a row range to retrieve the data_. Other types of queries trigger a full table scan, which is _much less efficient. _Row key prefixes are useful to store multi-tenant data in** one table. _Further, sequential ids, timestamps, hashed values, domain names and frequently updated identifiers _must be avoided**.
If you usually retrieve the most recent records first, you can use a** reversed timestamp** in the row key by subtracting the timestamp from your programming language’s maximum value for long integers (in Java, java.lang.Long.MAX_VALUE). With a reversed timestamp, the records will be ordered from most recent to least recent.
#gcp #google-cloud-platform #big-data #nosql #nosql-database #database