Categorical data is simply information aggregated into groups rather than being in numeric formats, such as Gender, Sex or Education Level. They are present in almost all real-life datasets, yet the current algorithms still struggle to deal with them.
Take, for instance, XGBoost or most SKlearn models. If you try and train them with categorical data, you’ll immediately get an error.
Currently, many resources advertise a wide variety of solutions that might seem to work at first, but are deeply wrong once thought through. This is especially true for non-ordinal categorical data, meaning that the classes are not ordered (As it might be for Good=0, Better=1, Best=2). A bit of clarity is needed to distinguish the approaches that Data Scientists should use from those that simply make the models run.
What Not To Do: Label Encoding
One of the simplest and most common solutions advertised to transform categorical variables is Label Encoding. It consists of substituting each group with a corresponding number and keeping such numbering consistent throughout the feature.
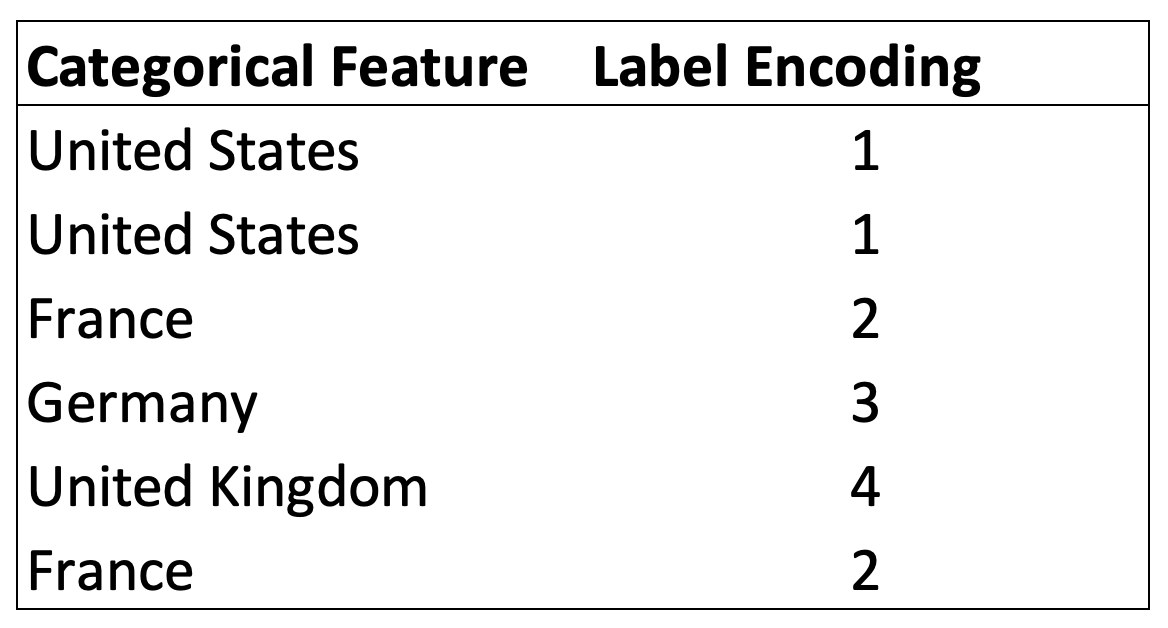
Example of Label Encoding
This solution makes the models run, and it is one of the most commonly used by aspiring Data Scientists. However, its simplicity comes with many issues.
Distance and Order
Numbers hold relationships. For instance, four is twice two, and, when converting categories into numbers directly, these relationships are created despite not existing between the original categories. Looking at the example before, United Kingdom becomes twice France, and France plus United States equals Germany.
Well, that’s not exactly right…
This is especially an issue for algorithms, such as K-Means, where a distance measure is calculated when running the model.
#editors-pick #categorical-data #data-science #machine-learning #data analysisa