Let’s say the chief credit and collections officer asks you to list down the names of people, their unpaid balances per month, and the current running balance and wants you to import this data array into Excel. The purpose is to analyze the data and come up with an offer making payments lighter to mitigate the effects of the COVID19 pandemic.
Do you opt to use a query and a nested subquery or a join? What decision will you make?
SQL Subqueries – What Are They?
Before we do a deep dive into syntax, performance impact, and caveats, why not define a subquery first?
In the simplest terms, a subquery is a query within a query. While a query that embodies a subquery is the outer query, we refer to a subquery as the inner query or inner select. And parentheses enclose a subquery similar to the structure below:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)
We are going to look upon the following points in this post:
- SQL subquery syntax depending on different subquery types and operators.
- When and in what sort of statements one can use a subquery.
- Performance implications vs. JOINs.
- Common caveats when using SQL subqueries.
As is customary, we provide examples and illustrations to enhance understanding. But bear in mind that the main focus of this post is on subqueries in SQL Server.
Now, let’s get started.
Make SQL Subqueries That Are Self-Contained or Correlated
For one thing, subqueries are categorized based on their dependency on the outer query.
Let me describe what a self-contained subquery is.
Self-contained subqueries (or sometimes referred to as non-correlated or simple subqueries) are independent of the tables in the outer query. Let me illustrate this:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)
As demonstrated in the above code, the subquery (enclosed in parentheses below) has no references to any column in the outer query. Additionally, you can highlight the subquery in SQL Server Management Studio and execute it without getting any runtime errors.
Which, in turn, leads to easier debugging of self-contained subqueries.
The next thing to consider is correlated subqueries. Compared to its self-contained counterpart, this one has at least one column being referenced from the outer query. To clarify, I will provide an example:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)
Were you attentive enough to notice the reference to BusinessEntityID from the Person table? Well done!
Once a column from the outer query is referenced in the subquery, it becomes a correlated subquery. One more point to consider: if you highlight a subquery and execute it, an error will occur.
And yes, you are absolutely right: this makes correlated subqueries pretty harder to debug.
To make debugging possible, follow these steps:
- isolate the subquery.
- replace the reference to the outer query with a constant value.
Isolating the subquery for debugging will make it look like this:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>
Now, let’s dig a little deeper into the output of subqueries.
Make SQL Subqueries With 3 Possible Returned Values
Well, first, let’s think of what returned values can we expect from SQL subqueries.
In fact, there are 3 possible outcomes:
- A single value
- Multiple values
- Whole tables
Single Value
Let’s start with single-valued output. This type of subquery can appear anywhere in the outer query where an expression is expected, like the WHERE clause.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)
When you use a MAX() function, you retrieve a single value. That’s exactly what happened to our subquery above. Using the equal (=) operator tells SQL Server that you expect a single value. Another thing: if the subquery returns multiple values using the equals (=) operator, you get an error, similar to the one below:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
Multiple Values
Next, we examine the multi-valued output. This kind of subquery returns a list of values with a single column. Additionally, operators like IN and NOT IN will expect one or more values.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')
Whole Table Values
And last but not least, why not delve into whole table outputs.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]
Have you noticed the FROM clause?
Instead of using a table, it used a subquery. This is called a derived table or a table subquery.
And now, let me present you some ground rules when using this sort of query:
- All columns in the subquery should have unique names. Much like a physical table, a derived table should have unique column names.
- ORDER BY is not allowed unless TOP is also specified. That’s because the derived table represents a relational table where rows have no defined order.
In this case, a derived table has the benefits of a physical table. That’s why in our example, we can use COUNT() in one of the columns of the derived table.
That’s about all regarding subquery outputs. But before we get any further, you may have noticed that the logic behind the example for multiple values and others as well can also be done using a JOIN.
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'
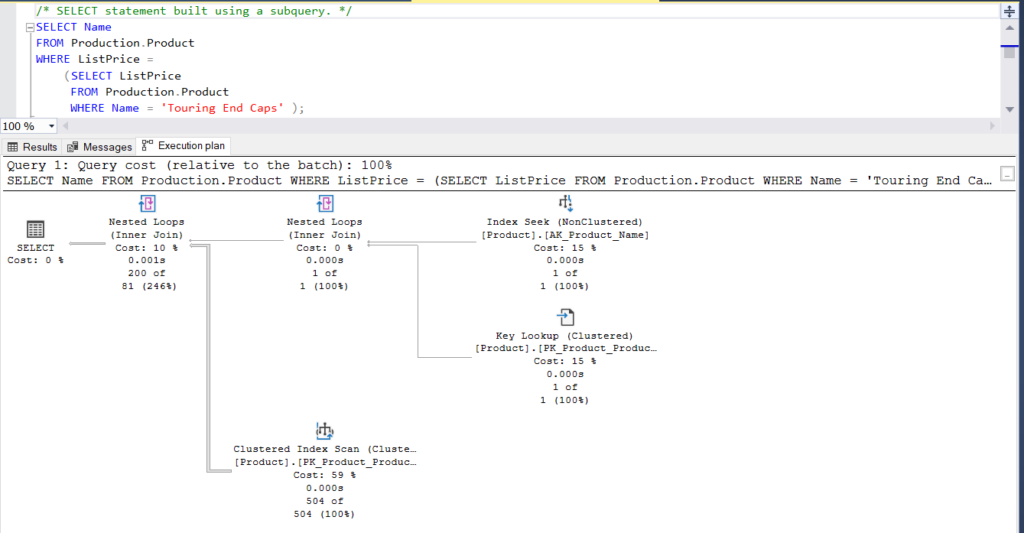
In fact, the output will be the same. But which one performs better?
Before we get into that, let me tell you that I have dedicated a section to this hot topic. We’ll examine it with complete execution plans and have a look at illustrations.
So, bear with me for a moment. Let’s discuss another way to place your subqueries.
#sql server #sql query #sql server #sql subqueries #t-sql statements #sql