This blog post was co-authored by Nikisha Reyes-Grange, Senior Product Marketing Manager, Azure Marketing.
We are beyond excited to announce that Azure Cosmos DB serverless is now available in preview on the Core (SQL) API, with support for the APIs for MongoDB, Gremlin (graph), Table, and Cassandra coming soon. This new consumption-based model lets you use your containers cost-effectively, without having to provision any throughput.
What is serverless on Azure Cosmos DB?
Announced at the Build conference this past May, serverless radically changes the way you use and pay for your Azure Cosmos DB resources.
Until now, your only option for running a workload on Azure Cosmos DB has been to provision throughput. This throughput, expressed in Request Units per second (RU/s), is dedicated to your usage and available for your database operations to consume. This model comes with low-latency and high-availability SLAs, making it a great fit for high-traffic applications needing guaranteed performance – but not as well-suited to light traffic scenarios.
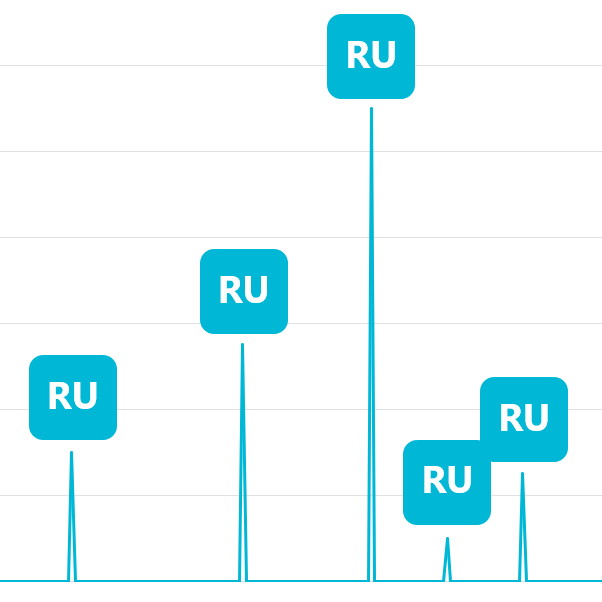
Serverless is a cost-effective option for databases with sporadic traffic patterns and modest bursts. When your resources sit idle most of the time, it doesn’t make sense to provision and pay for unneeded per-second capacity. As a consumption-based option, serverless eliminates the concept of provisioned throughput and instead charges you for the RUs your database operations consume.
Check this video for a visual comparison between provisioned throughput and serverless:
Differences with provisioned throughput
Serverless containers expose the same capabilities as containers created in provisioned throughput mode. This means that you manage your resources and read, write and query your data the exact same way. Where serverless accounts and containers differ from those using provisioned throughput is:
#announcements #azure cosmos db #serverless