Graph Neural Networks (GNNs) are widely used today in diverse applications of social sciences, knowledge graphs, chemistry, physics, neuroscience, etc., and accordingly there has been a great surge of interest and growth in the number of papers in the literature.
However, it has been increasingly difficult to gauge the effectiveness of new models and validate new ideas that generalize universally to larger and complex datasets in the absence of a standard and widely-adopted benchmark.
To address this paramount concern existing in graph learning research, we develop an open-source, easy-to-use and reproducible benchmarking framework with a rigorous experimental protocol that is representative of the categorical advances in GNNs.
This post outlines the issues in the GNN literature suggesting the need of a benchmark, the framework proposed in the paper, the broad classes of widely used and powerful GNNs benchmarked and the insights learnt from the extensive experiments._
Why benchmark?
In any core research or application area in deep learning, a benchmark helps to identify and quantify what types of architectures, principles, or mechanisms are universal and generalizable to real-world tasks and large datasets. Particularly, the recent revolution in this AI field is often credited, to a possibly large extent, to be triggered by the large-scale benchmark image dataset, ImageNet. (Obviously, other driving factors include increase in the volume of research, more datasets, compute, wide-adoptance, etc.)
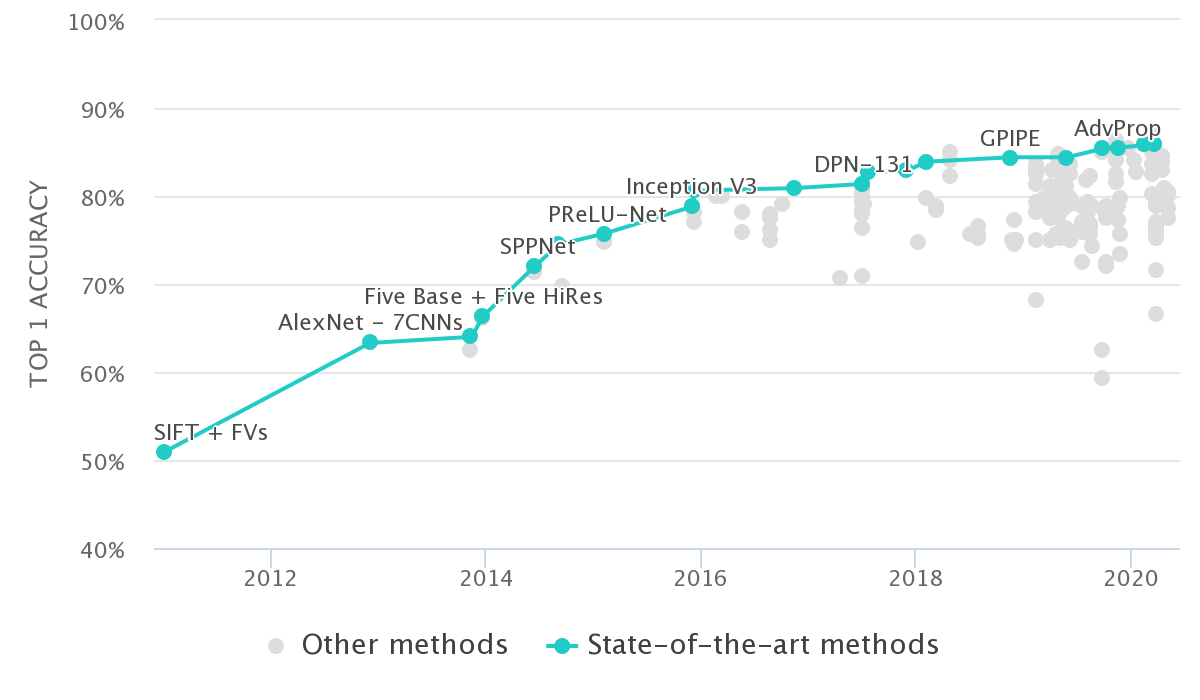
Fig 1: ImageNet Classification Leaderboard from paperswithcode.com
Benchmarking has been proved to be beneficial for driving progress, identifying essential ideas, and solving domain-related problems in many sub-fields of science. This project was conceived with this fundamental motivation.
Need of a benchmarking framework for GNNs
a. Datasets:
Many of the widely cited papers in the GNN literature contain experiments that are evaluated on small graph datasets which have only a few hundreds (or, thousand) of graphs.
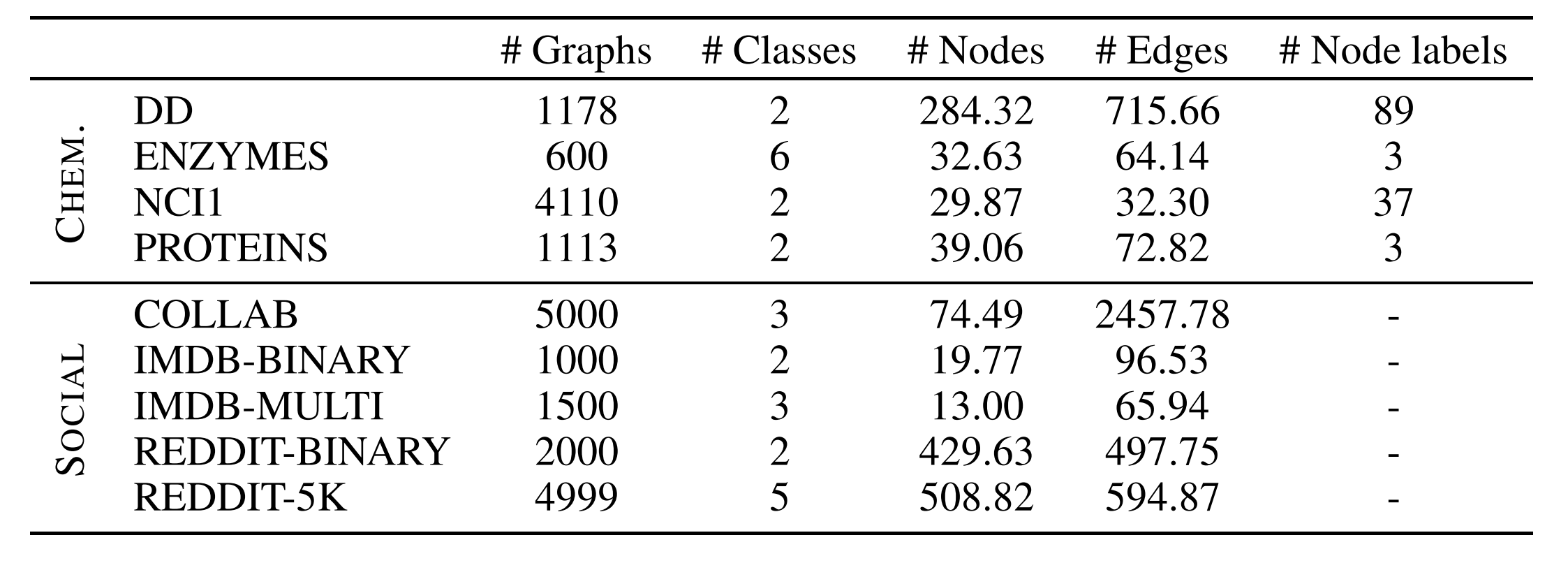
Fig 2: Statistics of the widely used TU datasets. Source Errica et al., 2020
Take for example, the ENZYMES dataset, which is almost seen in every work on a GNN for classification task. If one uses a random 10-fold cross validation (in most papers), the test set would have 60 graphs (i.e. 10% of 600 total graphs). That would mean a correct classification (or, alternatively a misclassification) would change 1.67% of test accuracy score. A couple of samples could determine a 3.33% difference in performance measure, which is usually a significant gain score stated when one validates a new idea in literature. You see there, the number of samples is unreliable to concretely acknowledge the advances.¹
Our experiments, too, show that the standard deviation of performance on such datasets is large, making it difficult to make substantial conclusions on a research idea. Moreover, most GNNs perform statistically the same on these datasets. The quality of these datasets also leads one to question if you should use them while validating ideas on GNNs. On several of these datasets, simpler models, sometimes, perform as good, or even beats GNNs.
Consequently, it has become difficult to differentiate complex, simple and graph-agnostic architectures for graph machine learning.
b. Consistent experimental protocol:
Several papers in the GNN literature do not have consensus on a unifying and robust experimental setting which leads to discussing the inconsistencies and re-evaluating several papers’ experiments.
For a couple of examples to highlight here, Ying et al., 2018 performed training on 10-fold split data for a fixed number of epochs and reported the performance of the epoch which has the “highest average validation accuracy across the splits at any epoch” whereas Lee et al., 2019 used an “early stopping criterion” by monitoring the epoch-wise validation loss and report “average test accuracy at last epoch” over 10-fold split.
Now, if we extract results of both these papers to put together in the same table and claim that the model with the highest performance score is the promising of all, can we get convinced that the comparison is fair?
There are other issues related to hyperparamter selection, comparison in an unfair budgets of trainable parameters, use of different train-validation-test splits, etc.
The existence of such problems pushed us to develop a GNN benchmarking framework which standardizes GNN research and help researchers make more meaningful advances.
#benchmarking #graph #graph-deep-learning #graph-neural-networks #deep-learning
