In neural network activation function are used to determine the output of that neural network.This type of functions are attached to each neuron and determine whether that neuron should activate or not, based on each neuron’s input is relevant for the model’s prediction or not.In this article we going to learn different types of activation function and their advantages ,disadvantages.
Before going to study activation function let’s see how activation function works.
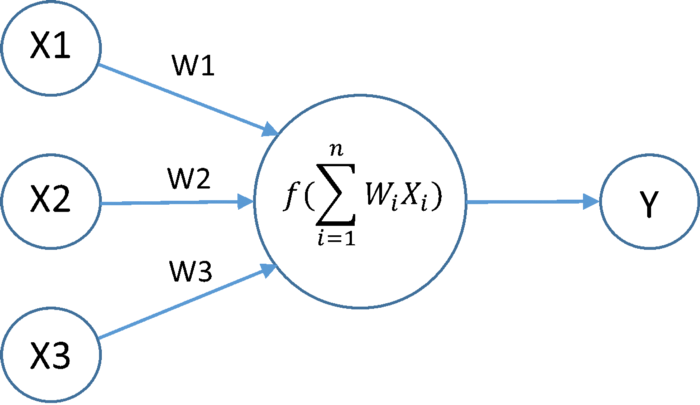
fig1.Activation function
we know that each neuron contain activation function .It takes input as summation of product of outputs of previous layer with respective their weights.This summation value is passed to activation function.
commonly used activation function
1. Sigmoid Function:-
Sigmoid function is a one of the most popular activation function.Equation of sigmoid function reprsented as
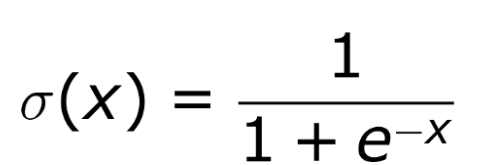
sigmoid function always gives output in range of (0,1) .The derivative of sigmoid function is f`(x) =f(x)(1-f(x)) and it’s range between (0,0.25).
Generally sigmoid function is used in end layers.
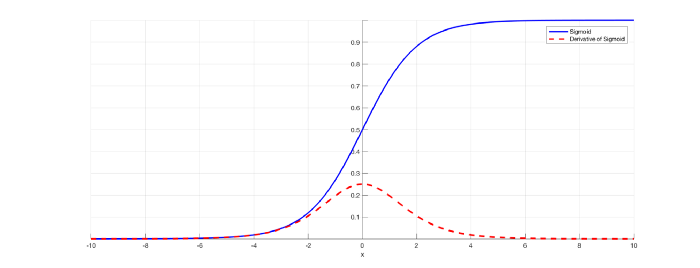
sigmoid activation function
Adavantages
1 Smooth gradient, preventing “jumps” in output values.
2 Output values bound between 0 and 1, normalizing the output of each neuron.
Disadavantages
1 Not a zero centric function.
2 Suffers with gradient vanishing.
3 Output of values which are far away from centroid is close to zero.
4 Computationally expensive because it has to calculate exponential value in function.
2 Tanh or Hyperbolic tangent activation function:-
To overcome disadvantage of non-zero centric function of sigmoid function people introduced tanh activation function.Tanh activation function equation and graph represented as
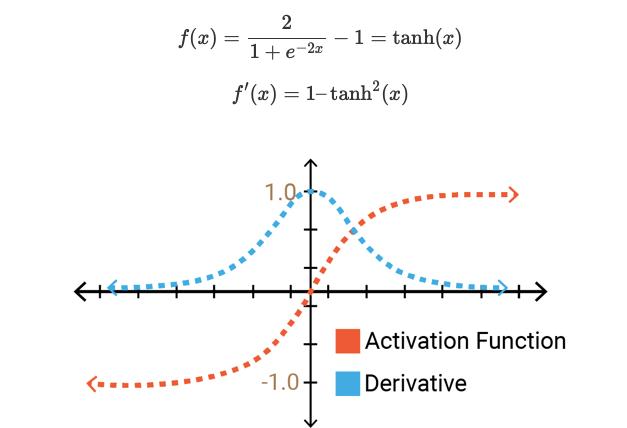
Tanh activation function
the output of Tanh activation function always lies between (-1,1) and it’s derivative lies between (0,1)
Advantages
Tanh function have all advantages of sigmoid function and it also a zero centric function.
disadvantages
1 more computation expensive than sigmoid function.
2 suffers with gradient vanishing.
3 output of values which are far away from centroid is close to zero.
3 RELU(Rectified Linear Unit):-
In above two activation we have major problem with gradient vanishing to overcome this problem people introduced relu activation function.
Relu activation function is simple f(x) = max(0,x) .which means if x(input value) is positive then output also x.If x(input value) is negative then output value is zero,which means that particular neuron is deactivated.
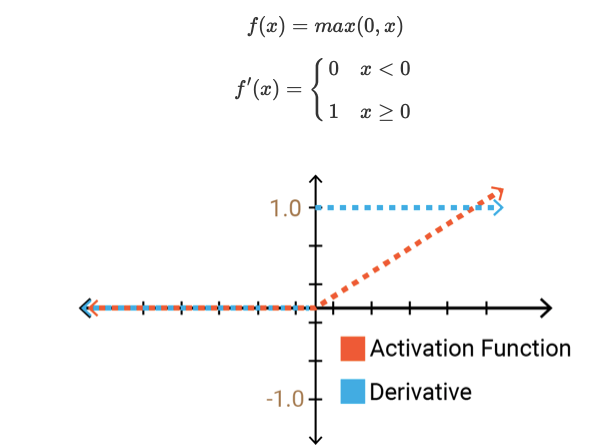
RELU activation function
Advantages
1 No gradient vanishing
2 Derivative is constant
3 Less computation expensive
Disadvantages
1 No matter what for negative values neuron is completely inactive.
2 Non zero centric function.
#neural-networks #data-science #activation-functions