Big-O is a simple and very general concept — the amount of primitive operations needed to complete the algorithm with some parameter n — that can be very easily construed as something it’s not.
One common misconception is to use Big-O’s convincing notation and treat it as a function. For example, writing such a statement:
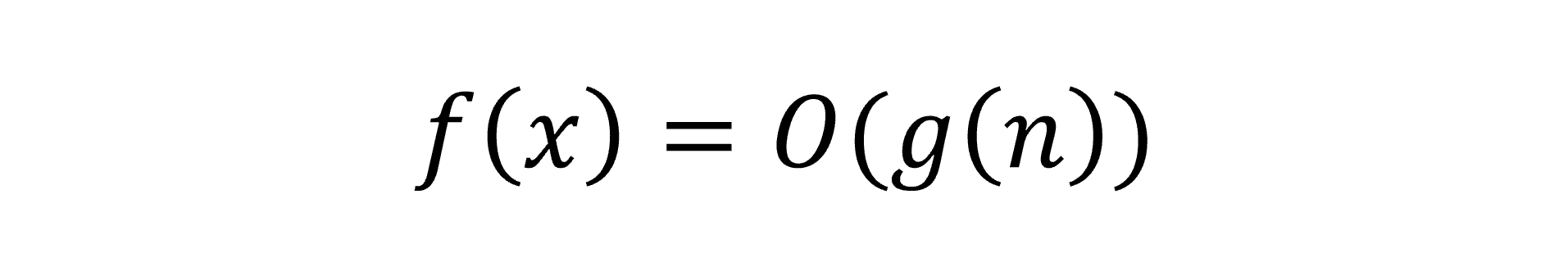
Because Big-O is written like a function, many treat it as such. However, it is simply notation protocol, and all terms within g(n) that are not ‘driving forces’ are discarded to describe the general shape of the runtime as n scales higher and higher. Although everyone knows that Big-O is not a function, that type of thinking often appears in disguised form in other scenarios.
These functions all have the same Big-O notation.
For instance, questions like “an algorithm is O(_n_²). At _n=_5, the algorithm takes 10 seconds. How long will the algorithm take to run at n=10?” are based on the premise that O(_n_²) is a function and another misconception about the relationship between time and complexity, as will be explored further on.
As another example, an underlying belief that Big-O is a function leads people to make silly comparisons between algorithms, declaring that one is ‘better’ than the other on the basis of a ‘better’ Big-O form. For instance, consider two algorithms, one with O(_n_²) and the other with O(_n_³). It’s convincing for many to directly establish that the former is somehow ‘better’ than the latter simply because of the shape of the driving forces behind the scaling complexity.
Although it’s admittedly somewhat of an extreme example, rethink your comparison now: which algorithm is ‘better’?

Furthermore, comparison of algorithms may not even be justified at all, depending on what n means. Different algorithms operate in different ways, so sometimes they cannot be compared at all. For instance, consider Mergesort, with O(n log n), which is part of a family of sorting algorithms that are comparison-based, meaning it sorts items by comparing them relative to others. Radixsort is O(n). Even disregarding multiplicative and additive constants, is it fair to say that Radixsort has a lower complexity than Mergesort? No!
This is because Radixsort is not comparison-based, in that it never makes a comparison between two keys, instead basing sorts off place value. n does not mean the same thing in Mergesort and Radixsort. In order to compare the two complexities, we must define a shared model of computation, for example using the action of reading a byte as a primitive operation.
On the other hand, comparing the complexities Mergesort to another comparison-based algorithm like Quicksort would be legal, as long as the limitations of what Big-O means are taken into account.
#programming #algorithms #computer-science #coding #data-science #algorithms
