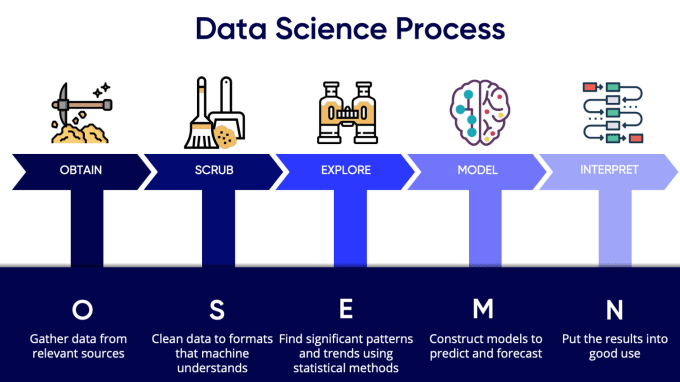
It’s been 4 exciting years since I began my journey in Data Science and through each experience, I’ve come to learn that the typical work pipeline in any Data Science Project involves these 5 steps — Data Collection, Data Cleaning, Exploratory Data Analysis, ML Modelling and Data Storytelling.
The life of a Data Scientist
It is a well-known fact that Data Scientists spend almost 80% of the time in cleaning, exploring and preparing the dataset, while the actual modelling and further analysis takes only 20% of the total time spent. For a beginner, this process can be a little too overwhelming and may take much more time, especially if one has less/no prior coding experience.
So how does one tackle this problem, yet be able to improve Data Quality and also quickly explore the dataset to formulate assumptions and hypothesis for modelling?
Enter quickda, a simple, low-code & easy-to-use EDA library in Python to help you quickly explore, clean and visualise data with just few lines of customisable codes! One thing to remember is that QuickDA is supposed to be a starting point for quick exploratory analysis, and in no way a replacement to traditional EDA approaches. So without further ado, let’s get right to it!
Getting Started with QuickDA
QuickDA can be installed using pip. Using the command line interface or notebook environment, run the below cell of code to install QuickDA.
pip3 install quickda
When you install the package, all dependencies are installed automatically. Click here to see the list of complete dependencies.
#programming #python #low-code-development #data-analysis #data-science #data analysis
