Apache Spark is the most developed library that you can utilize for many of your Machine Learning applications. It provides the users with the ease of developing ML-based algorithms in data scientist’s favorite scientific prototyping environment Jupyter Notebooks.
The Main Differences between MapReduce HDFS & Apache Spark
MapReduce needs files to be stored in a Hadoop Distributed File System, Spark doesn’t need that and it is really really fast compared to MapReduce. In contrast, Spark uses Resilient Distributed Datasets aka RDDs to store data which highly resembles Pandas dataframes. RDDs are also where Spark shines really brightly because you can harness the mighty power of the pandas-like data preprocessing and transformation through them.
The Main Installation Choices for Using Spark
- You can launch an AWS Elastic Map Reduce Service and use Zeppelin Notebooks but this is a premium service and you have to deal with creating an AWS account.
- Databricks Ecosystem → Has its own file system and dataframe syntax, it is a service started by one of the Spark’s founders, however this will result in a vendor lock-in and it is also not free.
- You can install it on your local Ubuntu or Windows too, but this process is very very cumbersome.
How to Install Spark on you local environment with Docker
Disclaimer, I am not going to dive into installation details of docker on your computer here for which many tutorials are available online. This command(embedded below) instantly gives you a Jupyter notebook environment with all the bells & whistles ready to go! I can’t do enough justice to be able to start a development environment with a single command. Therefore I highly highly recommend anyone who wants to take their Data Science & Engineering skills to the next level to learn at the very least how to effectively utilize Docker Hub images.
docker run -it — rm -p 8888:8888 jupyter/pyspark-notebook
There you go! Your environment is ready, to start using Spark begin a session by:

Every Spark Session Starts with this command
Spark MLlib & The Types of Algorithms That Are Available
You can do both supervised and unsupervised machine learning operations with Spark.
Supervised Learning has labelled data already whereas unsupervised learning does not have labelled data and thus it is more akin to seeking patterns in chaos.
- Supervised Learning Algorithms → Classification, Regression, Gradient Boosting. The algorithms in this category have both the features column and the labels columns.
- Unsupervised Learning Algorithms → K-means clustering, Value Decomposition, Self-organizing maps, Nearest Neighbours Mapping. With this class of algorithms you only have the features column available and no labels.
Spark Streaming Capabilities
I am planning to write an article about this in depth in the future but for the time being I just wanted to make you aware of Spark Streaming.
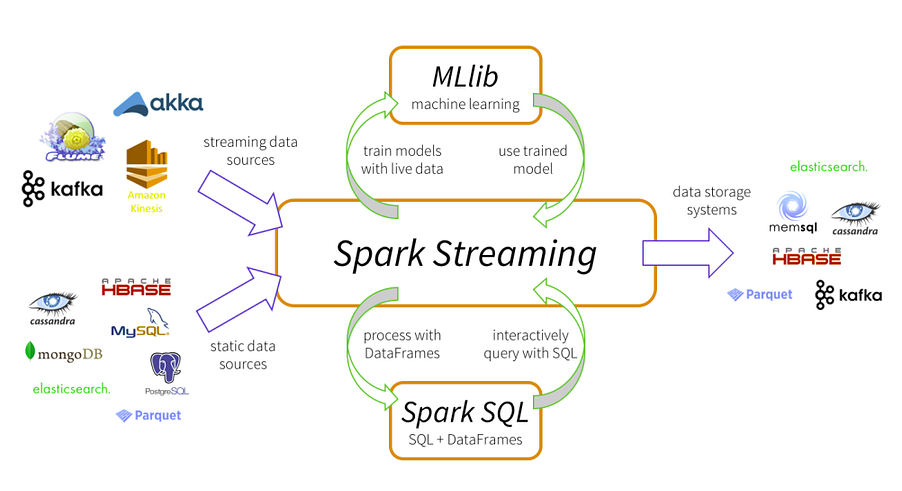
Spark Streaming is a great tool for developing real-time online algorithms.
Spark Streaming can ingest data from Kafka Producers, Apache Flume, AWS’s Kinesis Firehose or TCP Websockets.
One of the most crucial advantages of Spark Streaming is that you can do map, filter, reduce and join actions on unbounded data streams.
#apache spark #docker #python
