I have read many articles on the topic to find out which is better out of two and what should I use for my model. I wasn’t satisfied with any of them and that left my brain confused which one should I use? After having done so many experiments, I have finally found out all answers to Which Regularization technique to use and when? Let’s get to it using a regression example.
Let’s suppose we have a regression model for predicting y-axis values based on the x-axis value.
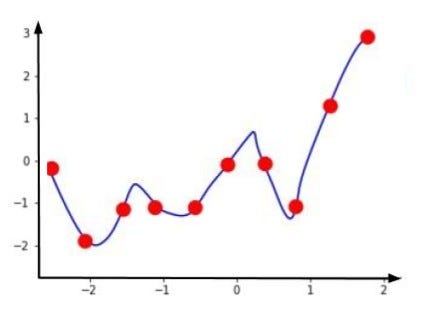
Train Data
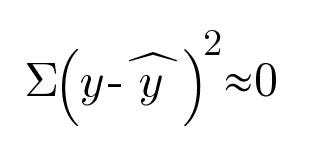
Cost Function
While training the model, we always try to find the cost function. Here, y is the actual output variable and ŷK is the predicted output. So, for the training data, our cost function will almost be zero as our prediction line passes perfectly from the data points.
Now, suppose our test dataset looks like as follows
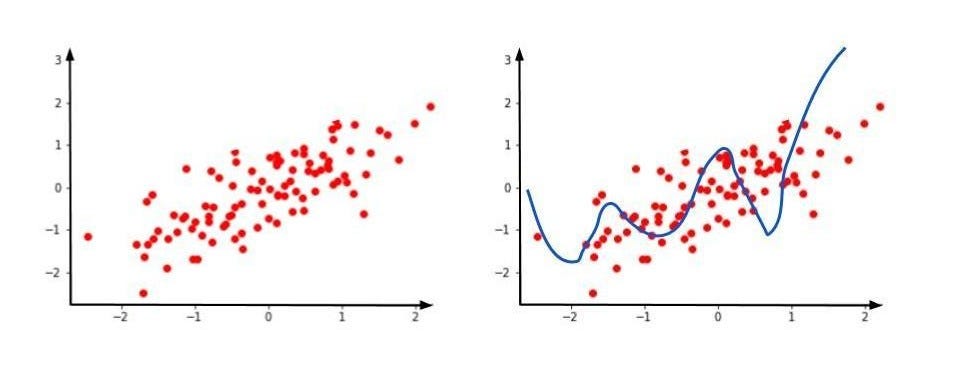
Model on the test dataset
Here, clearly our prediction is somewhere else and the prediction line is directed elsewhere. This leads to overfitting. Overfitting says that with respect to training dataset you are getting a low error, but with respect to test dataset, you are getting high error.
Remember, when we need to create any model let it be regression, classification etc. It should be generalized.
We can use L1 and L2 regularization to make this overfit condition which is basically high variance to low variance. A generalized model should always have low bias and low variance.
#ridge-regression #data-science #machine-learning #regularization #lasso-regression