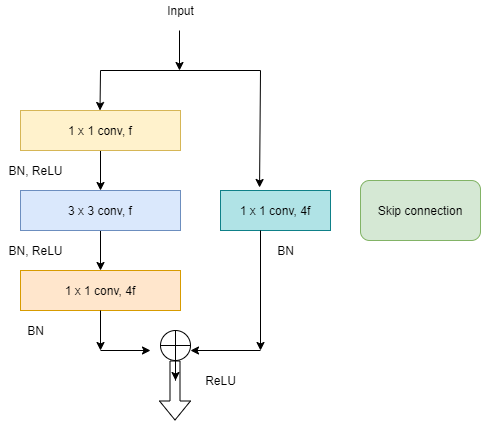
It is seen that often deeper neural networks perform better than shallow neural networks. But, deep neural networks face a common problem, known as the ‘Vanishing/Exploding Gradient Problem’. To overcome this problem the ResNet network was proposed.
Residual Blocks:
ResNets contain Residual blocks. As seen in Figure 1, there is an activation ‘a_l’ followed by a linear layer with the ReLU non-linearity, ‘a_l+1’. It is followed by another linear layer, with another non-linearity, ‘a_l+2_’. This is what a normal or plain neural network looks like. What ResNet adds to this is the skip-connection. In ResNet, the information from ‘a_l_’ is fast-forwarded and copied after the linear layer following ‘a_l+1_’, and before the ReLU non-linearity. This entire block, now with the skip-connection is known as a residual block. Figure 2 shows the residual block, as seen in the original ResNet paper. The skip connections help to skip over almost two layers, to pass its information deeper into the neural network.
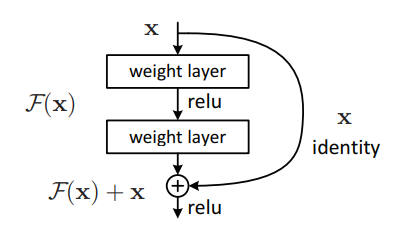
Figure 2. Residual block as shown in the ResNet paper (Source: Original ResNet paper)
Using residual blocks allowed to train much deeper neural networks. So the authors of the ResNet paper, stacked several of these residual blocks one after the other to form a deep residual neural network, as seen in Figure 3.
Figure 3. Image snippet of a 34 layer plain network vs a 34 layer residual network (Souce: Original ResNet paper)
It was seen that when an optimization algorithm such as SGD was used to train a deep plain network, theoretically the training error should have constantly decreased as the number of layers in the neural network increased, but that was not the case practically. After a decrease up to a certain layer, the training error started increasing again. But using residual blocks this problem could be overcome, and the training error kept on decreasing even when the number of layers was significantly increased. This can be seen in Figure 4.
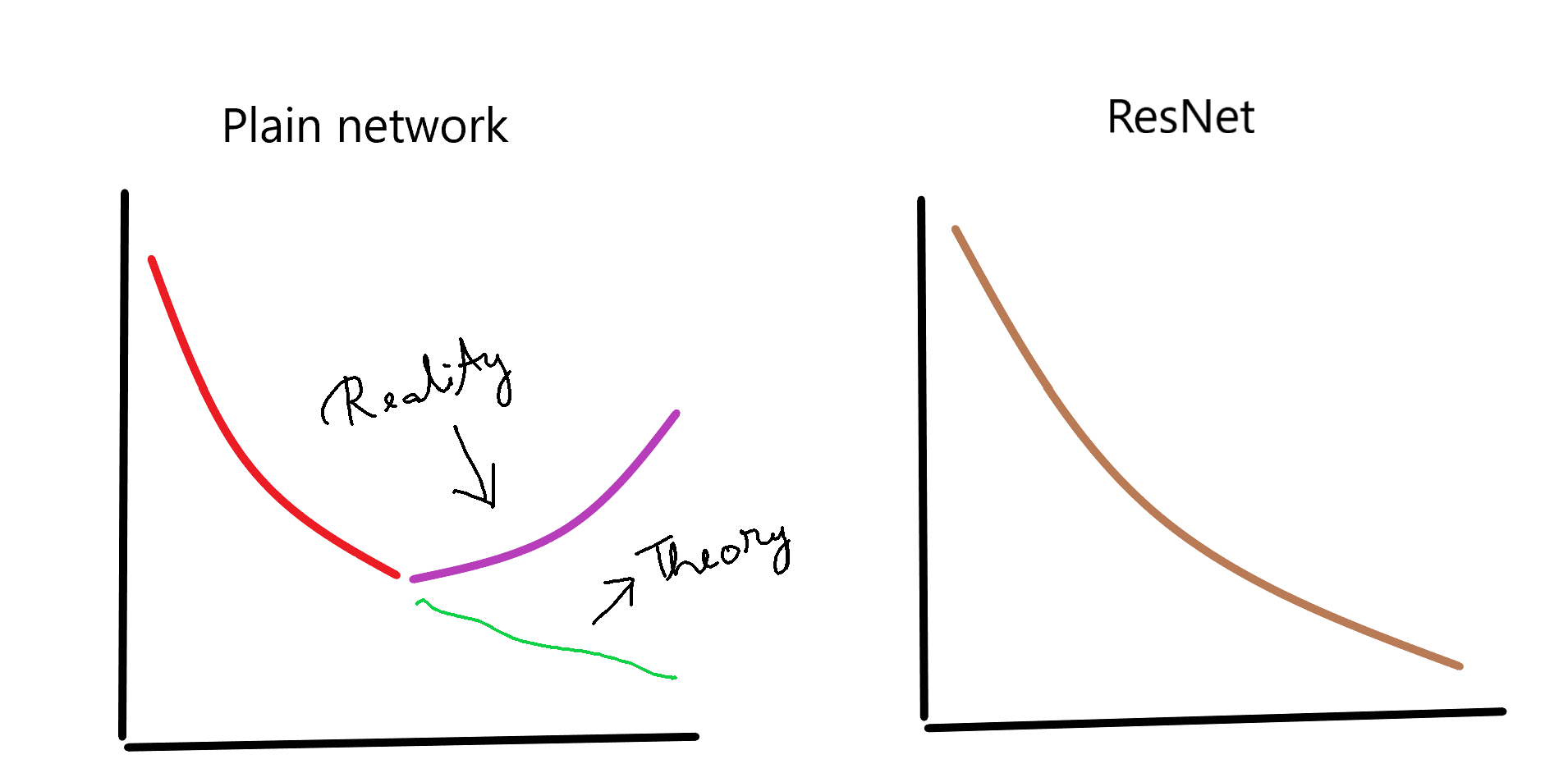
Figure 4. Training error in plain networks vs ResNet. The X-axis shows the increase in the number of layers and the y-axis shows the training error (Source: Image by author)
#machine-learning #deep-learning #artificial-intelligence #tensorflow #towards-data-science