A baseline model with LSTMs
The question remains open: how to learn semantics? what is semantics? would DL-based models be capable to learn semantics?
Introduction
The aim of this blog is to explain how to build a text classifier based on LSTMs as well as how it is built by using the PyTorch framework.
I would like to start with the following question: how to classify a text? Several approaches have been proposed from different viewpoints under different premises, but what is the most suitable one?. It’s interesting to pause for a moment and question ourselves: how we as humans can classify a text?, what do our brains take into account to be able to classify a text?. Such questions are complex to be answered.
Currently, we have access to a set of different text types such as emails, movie reviews, social media, books, etc. In this sense, the text classification problem would be determined by what’s intended to be classified (e.g. _is it intended to classify the polarity of given text? Is it intended to classify a set of movie reviews by category? Is it intended to classify a set of texts by topic? _). In this regard, the problem of text classification is categorized most of the time under the following tasks:
- Sentiment analysis
- News categorization
- Topic analysis
- Question answering
- Natural language inference
In order to go deeper into this hot topic, I really recommend to take a look at this paper: Deep Learning Based Text Classification: A Comprehensive Review.
Methodology
The two keys in this model are: tokenization and recurrent neural nets. Tokenization refers to the process of splitting a text into a set of sentences or words (i.e. tokens). In this regard, tokenization techniques can be applied at sequence-level or word-level. In order to understand the bases of tokenization you can take a look at: Introduction to Information Retrieval.
In the other hand, RNNs (Recurrent Neural Networks) are a kind of neural network which are well-known to work well on sequential data, such as the case of text data. In this case, it’s been implemented a special kind of RNN which is LSTMs (Long-Short Term Memory). LSTMs are one of the _improved _versions of RNNs, essentially LSTMs have shown a better performance working with _longer sentences. _In order to go deeper about what RNNs and LSTMs are, you can take a look at: Understanding LSTMs Networks.
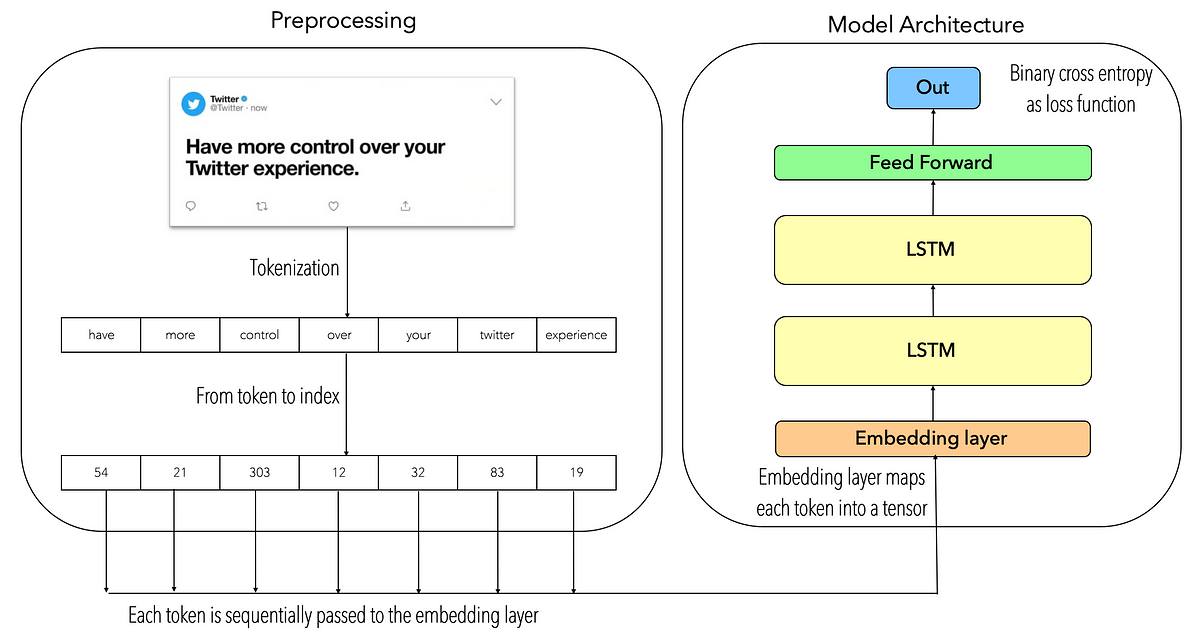
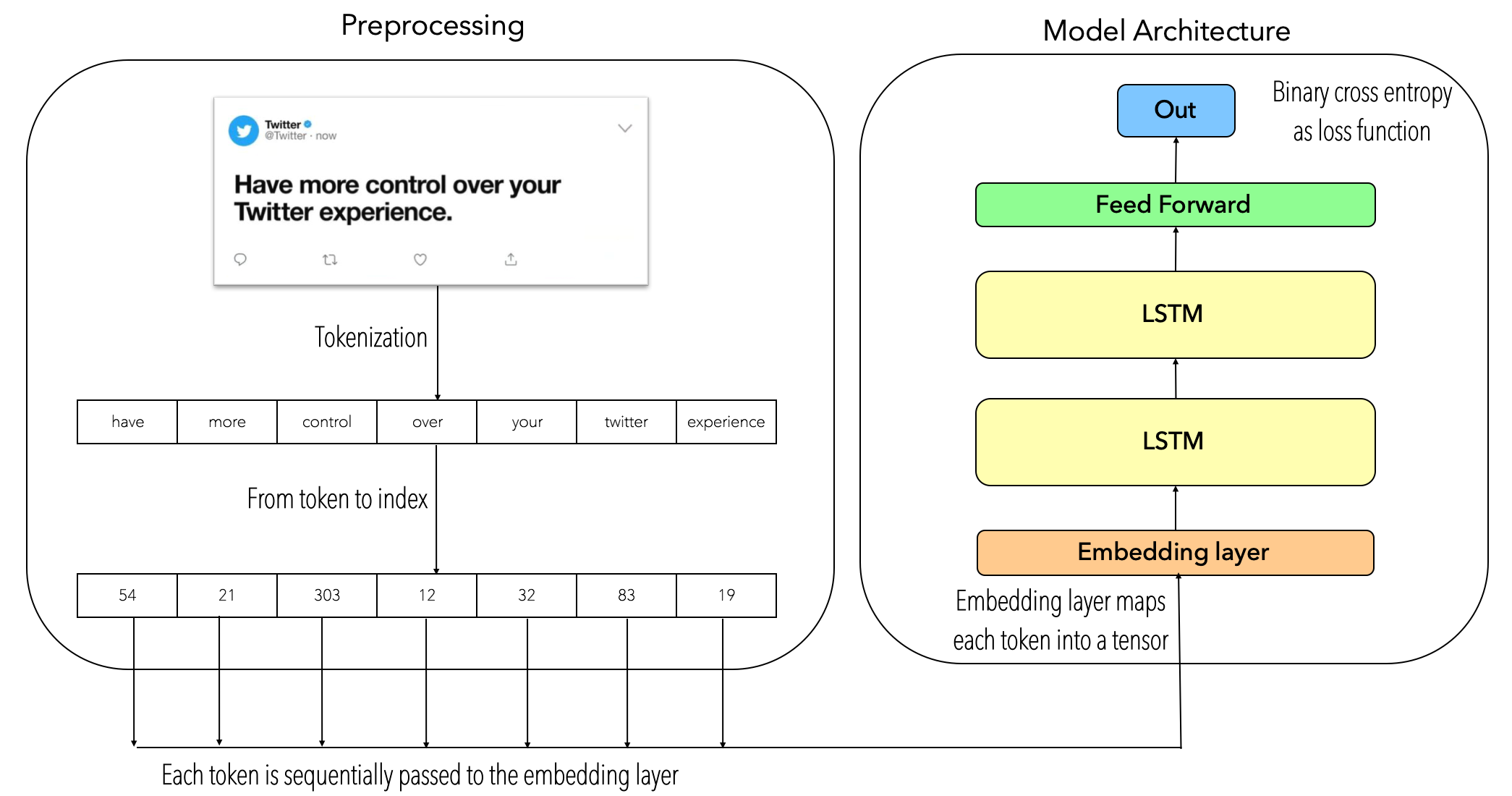
Since the idea of this blog is to present a baseline model for text classification, the text preprocessing phase is based on the tokenization technique, meaning that each _text sentence _will be tokenized, then each _token _will be transformed into its index-based representation. Then, each _token sentence based indexes _will be passed sequentially through an embedding layer, this embedding layer will output an embedded representation of each token whose are passed through a two-stacked LSTM neural net, then the last LSTM’s hidden state will be passed through a two-linear layer neural net which outputs a single value filtered by a sigmoid activation function. The following image describes the model architecture:
#pytorch #text-mining #lstm #text-classification #python