Introduction
Pain Points in NLP: In the NLP domain, to train an ML model, we need a proper dataset that is related to the context of the problem under study. But it’s often difficult to get this domain-specific data, and even found it’s quite a heavy task to perform labeling.
Solution: to tackle this situation, researchers have created a general-purpose model which are trained on the huge unannotated raw texts found on the internet, which includes vast domain’s context.
BERT is one such solution which can be fine-tuned to any NLP related context prediction.
Where BERT comes into play?
There are multiple algorithms that try to find solutions to NLP problems. So, where does BERT fits in, and how is it better than others?
Let’s go a bit further and discover
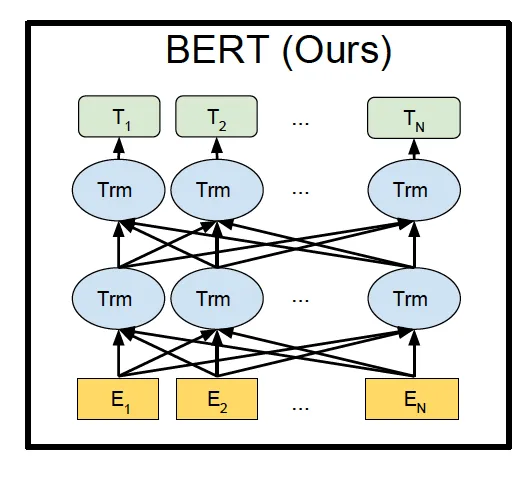
BERT is a pre-trained bidirectional model which is trained on vast data from the web — Original paper
Traditionally, the NLP domain has evolved from context-free models like word2vec, which converts each word to corresponding number representation, since the machine learning model can take only an array of numbers as input. With this methodology, a word is independent of other words in the sentence, completely ignoring the underlying meaning and resulting in less accuracy.
This is where BERT comes to the rescue. BERT is a context-based bidirectional model that understands the current meaning of a word from left-to-right and also from right-to-left.
#machine-learning #ai #nlp #data-science #data