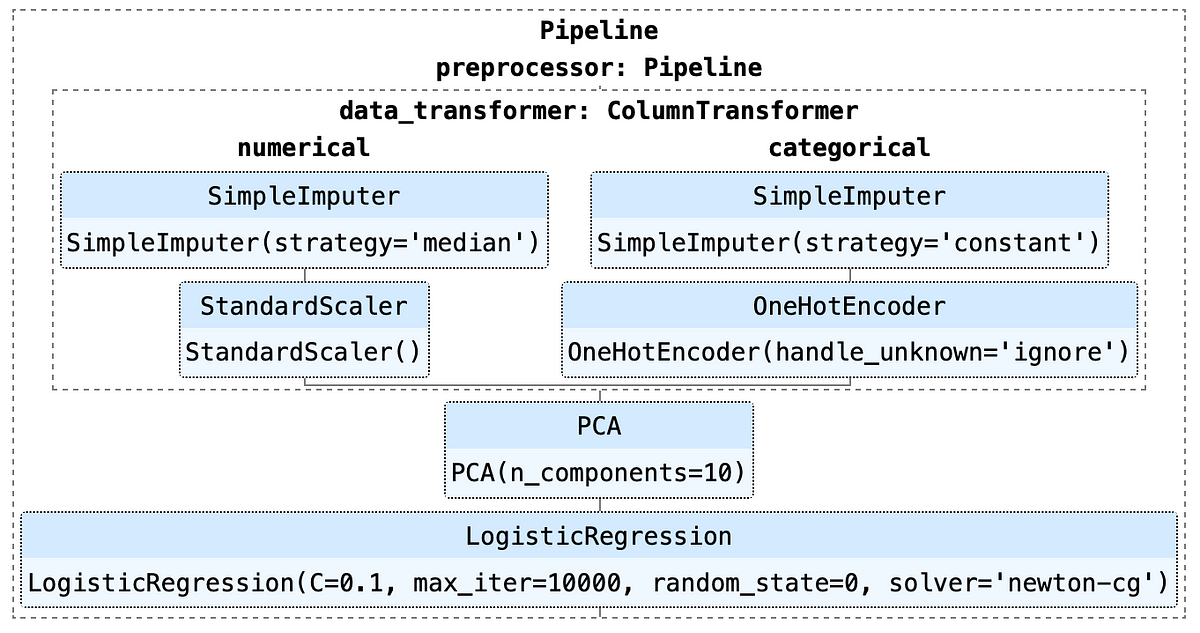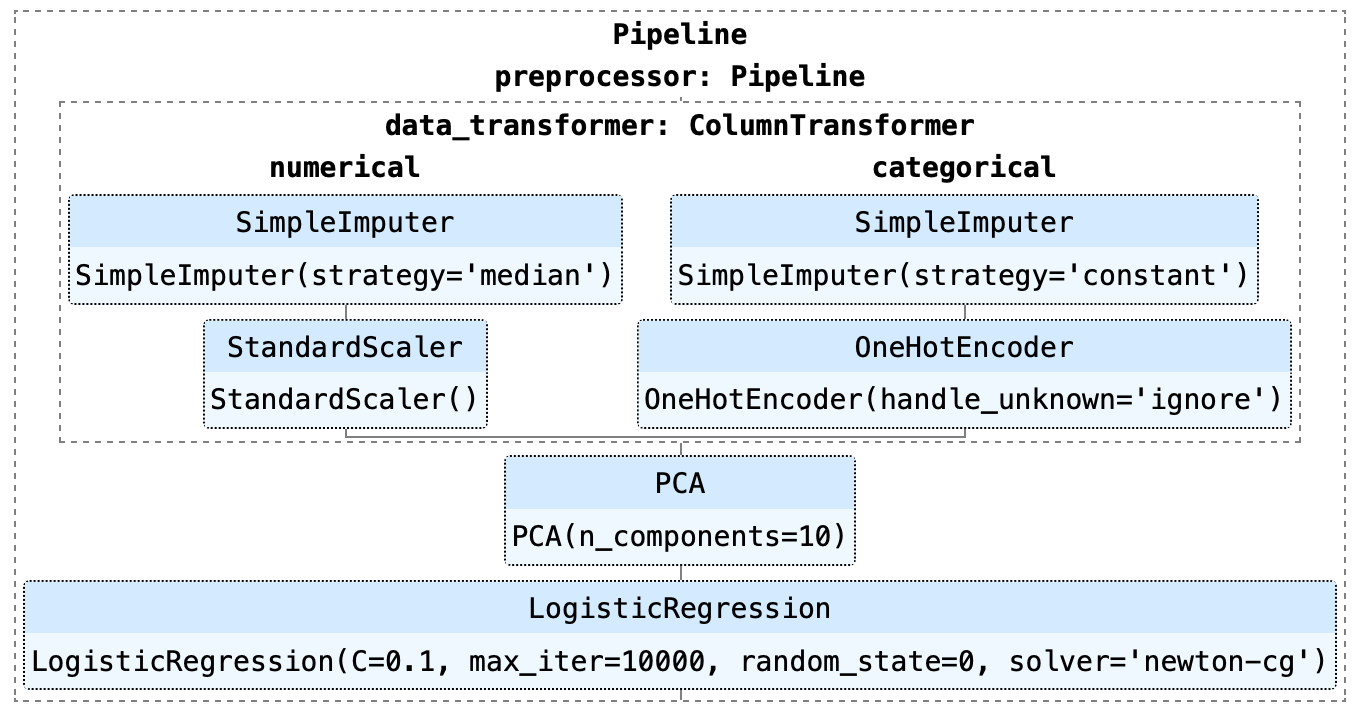
If you are doing Machine Learning, you would have come across pipelines as they help you to make a better machine learning workflow which is easy to understand and reproducible.
I recently discovered that you can combine Pipeline with GridSearchCV to not only find best hyperparameters for your model but can also find the best transformers for your machine learning tasks like-
- Scaler to scale your data.
- Impute strategy to fill missing values.
- The number of components in PCA you should use.
and many others. Let’s see how it can be done.
Dataset details
To best demonstrate, I am going to use the Titanic dataset from OpenML here to walkthrough on how you can create a data pipeline.
You can download the dataset using the following commands-
from sklearn.datasets import fetch_openml
# Dataset details at- https://www.openml.org/d/40945
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
Also, have a look at my notebook which have more details about each operation, feel free to download and import it in your environment and play around-
#pipeline #machine-learning #data-science #scikit-learn #python