I recently worked with a team that was lacking a bit of documentation, so I took it upon myself to create some. In the process, I gained sympathy for authors of documentation. Documentation can often seem incomprehensible, and that’s in part because when you write documentation, you have to assume your audience has some baseline level of knowledge. We can all agree, your project’s README isn’t the place to explain if/else statements! So I wrote some documentation outlining the steps required to make a pull request… only to realize some people on my team didn’t know what a pull request was. Whoops. So let’s clear that up!
The Problem with Collaborative Repositories
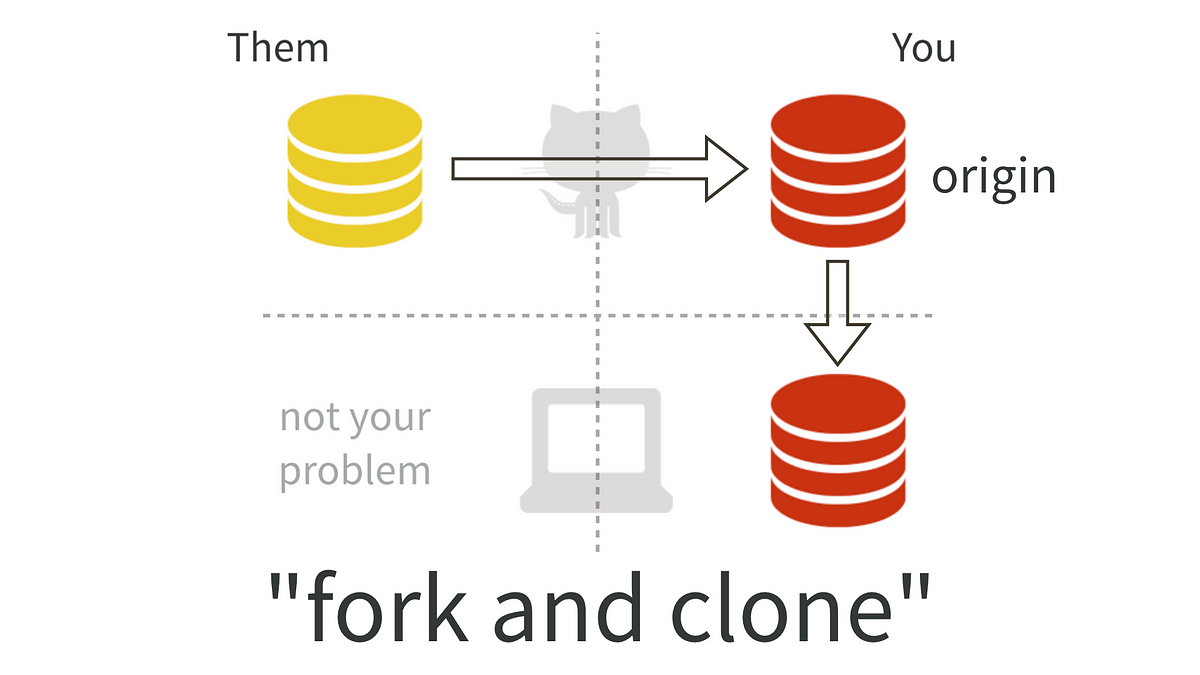
If you’re reading this article, I’m going to assume you’ve used Github before. You’ve made a personal repository for your own code, created commits, and then pushed those commits to that repository. This is a fantastic milestone in your development journey! Now you want to contribute to someone else’s repository. Perhaps this repository is open source, or perhaps it is a team’s repository. Okay, but simple enough, right? Let’s just clone this repo and push commits to it, just like you did with your personal repo.
BUT WAIT! That’s dangerous territory. What if someone pushes error-filled code to this shared repository? Or even worse, what if some malicious Github user intentionally breaks the app with pernicious code? We can’t have that! Therefore, this collaborative repo needs one or more trusted maintainers that review all incoming changes. Now the question is: how do you run your code by these maintainers?
Answer: You Make a Fork
A fork is simply a copy of the repo that lives on your own personal Github profile. You can make any changes you want to this fork and experiment all you want with its code, and that’s fine! Any changes you make to your fork have no effect on the original (henceforth, “upstream”) repository you forked from. In fact, the only way your changes make it into the upstream repo is through pull requests.
#github #git #github repos