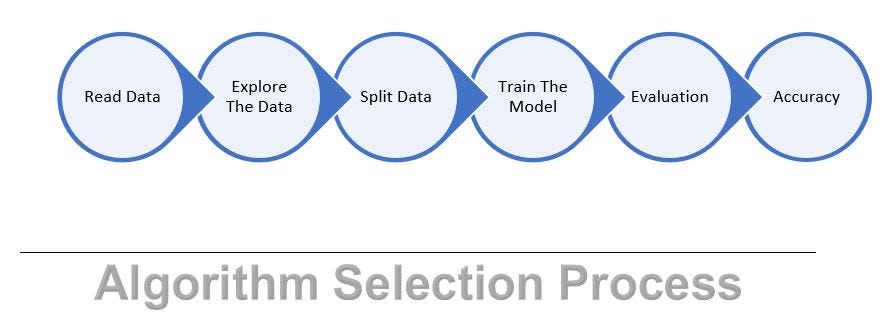
**Algorithm Selection Process: **Below is the algorithm selection process, where we read the data 1st and then we explore the data by various techniques, once data is ready, we divide the data into two parts, Training Data and Testing Data. We train model using training data and we evaluate the model on testing data. At the end we verify the accuracy of each model and best accurate model is used for production
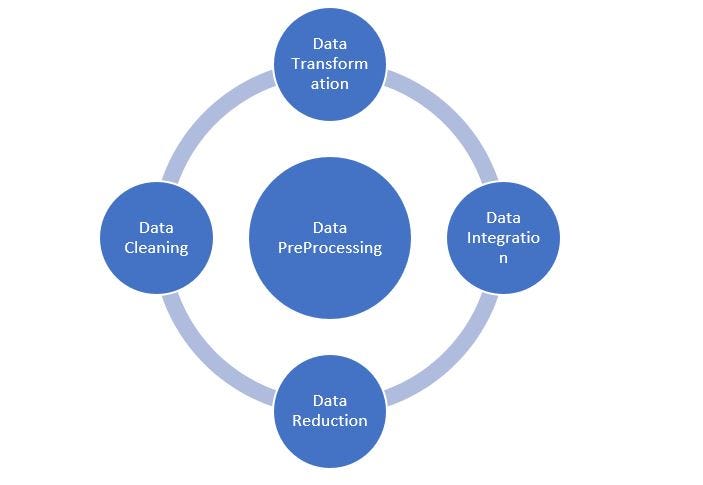
**Data PreProcessing: **Below are the techniques to preprocess the data prior to feeding the data to model. In Data Transformation, we have Feature scaling. In Feature Scaling, we will focus on StandardScaler and MinMaxScaler or Normalization.
Feature Scaling — Why Scale, Standardize, or Normalize?
Many machine learning algorithms perform better or converge faster when features are on a relatively similar scale and/or close to normally distributed. Examples of such algorithm families include:
· linear and logistic regression
· nearest neighbors
· neural networks
· support vector machines with radial bias kernel functions
· principal components analysis
· linear discriminant analysis
The goal of applying Feature Scaling is to make sure features are on almost the same scale so that each feature is equally important and make it easier to process by most ML algorithms.
Standardization: StandardScaler standardizes a feature by subtracting the mean and then scaling to unit variance. Unit variance means dividing all the values by the standard deviation. Standardization can be helpful in cases where the data follows a Gaussian distribution (or Normal distribution). However, this does not have to be necessarily true. Also, unlike normalization, standardization does not have a bounding range. So, even if you have outliers in your data, they will not be affected by standardization.
where μ is the mean (average) and σ is the standard deviation from the mean; standard scores (also called z scores) of the samples are calculated as follows:

StandardScaler results in a distribution with a standard deviation equal to 1. The variance is equal to 1 also, because variance = standard deviation squared. And 1 squared = 1.
StandardScaler makes the mean of the distribution 0. About 68% of the values will lie be between -1 and 1.
Deep learning algorithms often call for zero mean and unit variance. Regression-type algorithms also benefit from normally distributed data with small sample sizes.
#scaling #standardization #normalization