3D target detection based on laser point cloud is the core perception module in the autonomous driving system. Due to the sparseness of the point cloud and the disorder of the spatial structure, a series of Voxel-based 3D detection methods have been developed.However, the Voxel-based method requires a predefined spatial grid resolution, and the effectiveness of its feature extraction depends on the spatial resolution.
[1] mainly studies 3D target detection indoors and outdoors based on RGB-D images. The previous methods focused on 2D images or 3D voxels, which would blur the pattern of the 3D data itself and the invariance of the 3D data.
The advantage of learning directly from point cloud data is that it can accurately estimate the 3D bounding box under strong occlusion or very sparse points.
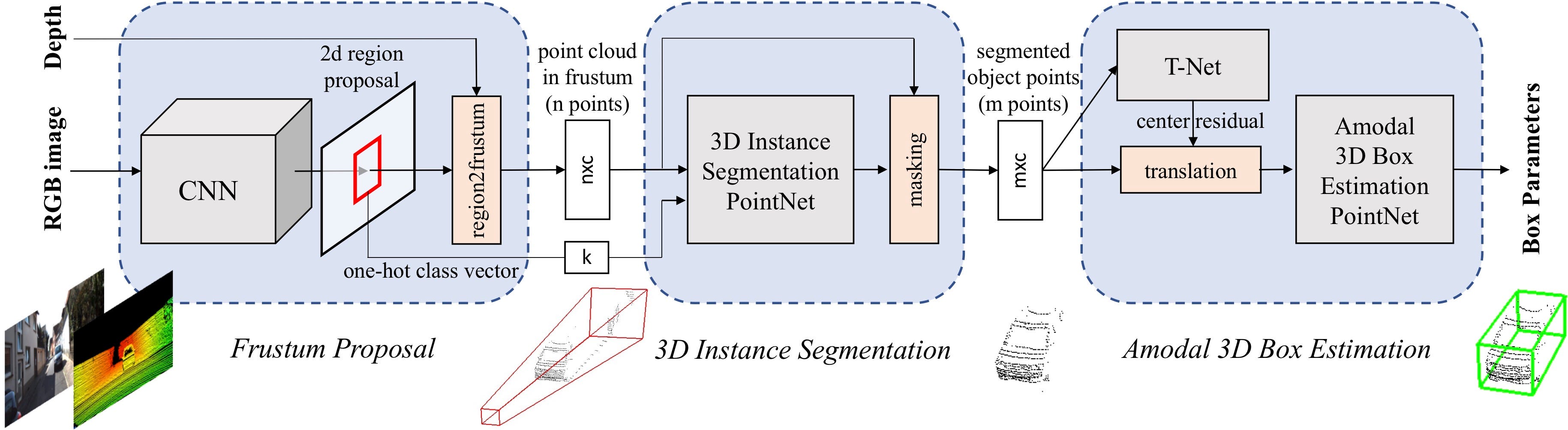
Frustum PointNets for 3D object detection [1]. They first leverage a 2D CNN object detector to propose 2D regions and classify their content. 2D regions are then lifted to 3D and thus become frustum proposals. Given a point cloud in a frustum (n × c with n points and c channels of XYZ, intensity etc. for each point), the object instance is segmented by binary classification of each point. Based on the segmented object point cloud (m×c), a light-weight regression PointNet (T-Net) tries to align points by translation such that their centroid is close to amodal box center. At last the box estimation net estimates the amodal 3D bounding box for the object.
Given an RGB-D image, our goal is to classify and locate objects in 3D space. The depth data obtained from LiDAR or indoor depth sensor is represented as a point cloud in RGB camera coordinates. The projection matrix is known, so we can get the 3D frustum from the 2D image area.
#object-detection #machine-learning #segmentation #computer-vision #point-cloud #cloud