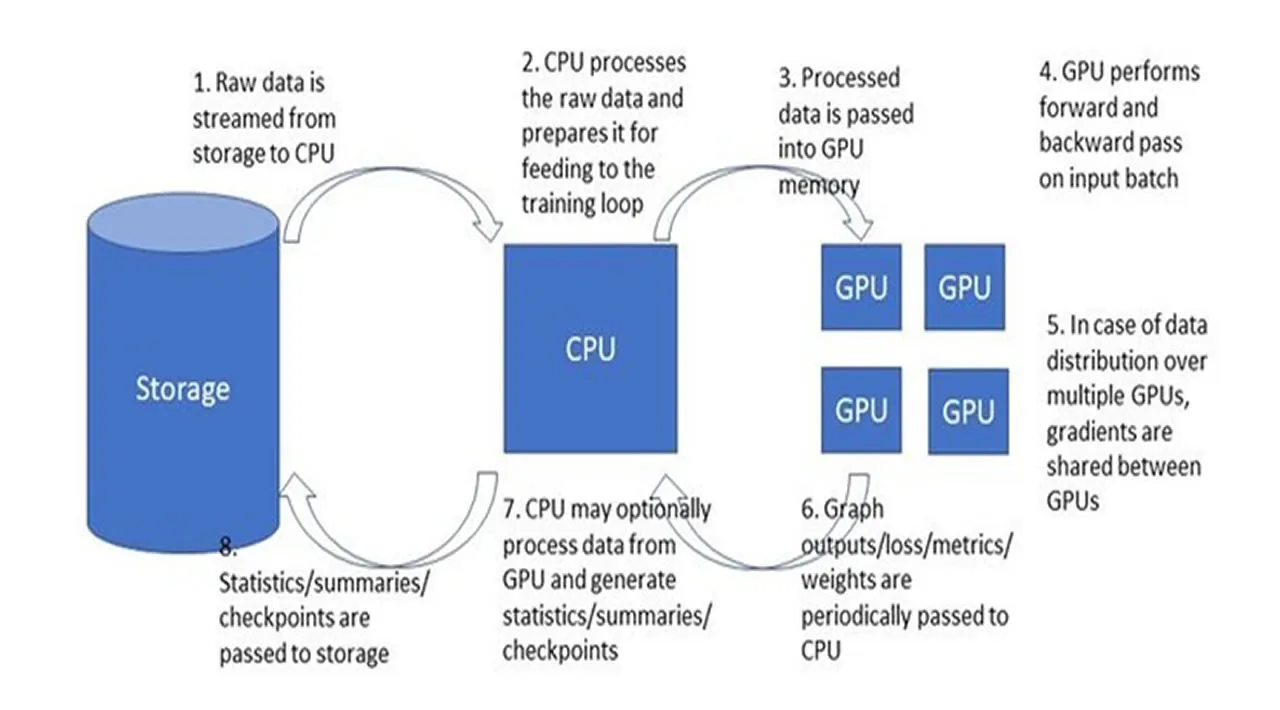
In a previous post, I spoke about the importance of profiling the runtime performance of your DNN training sessions as a means to making the most of your training resources, accelerating your training, and saving money. I described a typical training pipeline, (see the diagram below), reviewed some of the potential performance bottlenecks, and surveyed some of the tools available for identifying such bottlenecks. In this post I would like to expand on one of the more common performance bottlenecks, the CPU bottleneck, and some of the ways to overcome it. More specifically, we will discuss bottlenecks that occur in the data preprocessing pipeline, and ways to overcome them.
In the context of this post, we will assume that we are using TensorFlow, specifically TensorFlow 2.4, to train an image processing model on a GPU device, but the content is, mostly, just as relevant to other training frameworks, other types of models, and other training accelerators.
#data-preprocessing #tensorflow #bottleneck #machine-learning