Topic Model: In a nutshell, it is a type of statistical model used for tagging abstract “topics” that occur in a collection of documents that best represents the information in them. Many techniques are used to obtain topic models. This post aims to demonstrate the implementation of LDA: a widely used topic modeling technique.
Latent Dirichlet Allocation (LDA)
By definition, LDA is a generative probabilistic model for a given corpus. The basic idea is that documents are represented as a random mixture of latent topics, where each topic is characterized by a distribution of words.
LDA algorithm under the hood
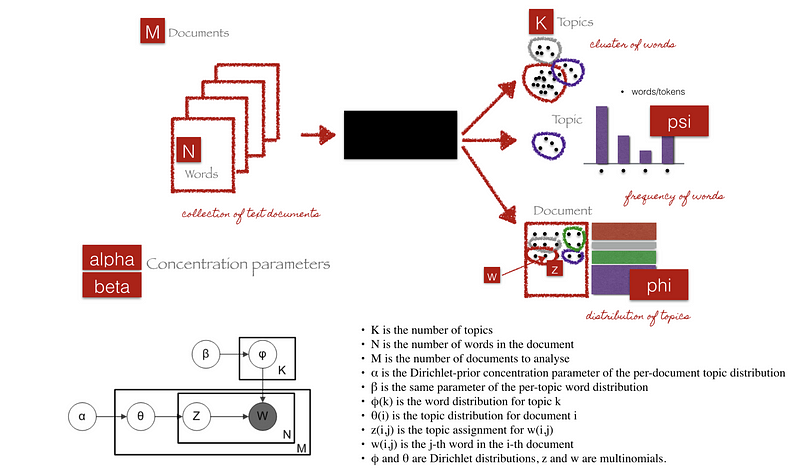
Given the M number of documents, N number of words, and estimated K topics, LDA uses the information to output (1) K number of topics, (2) psi, which is words distribution for each topic K, and (3) phi, which is topic distribution for document i
Alpha parameter is Dirichlet prior concentration parameter that represents document-topic density — with a higher alpha, documents are assumed to be made up of more topics and result in more specific topic distribution per document.
Beta parameter is the same prior concentration parameter that represents topic-word density — with high beta, topics are assumed to made of up most of the words and result in a more specific word distribution per topic.
LDA Implementation
The complete code is available as a Jupyter Notebook on GitHub
- Loading data
- Data cleaning
- Exploratory analysis
- Preparing data for LDA analysis
- LDA model training
- Analyzing LDA model results
Loading data

For this tutorial, we’ll use dataset of papers published in NIPS conference. The NIPS conference (Neural Information Processing Systems) is one of the most prestigious yearly events in the machine learning community. At each NIPS conference, a large number of research papers are published. The CSV file contains information on the different NIPS papers that were published from 1987 until 2016 (29 years!). These papers discuss a wide variety of topics in machine learning, from neural networks to optimization methods and many more.
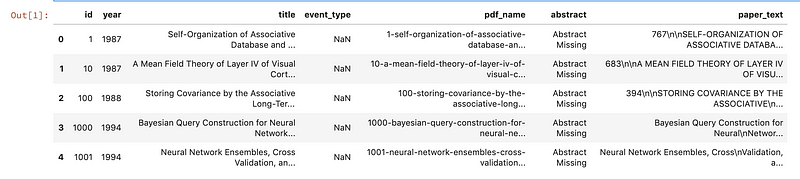
First, we will explore the CSV file to determine what type of data we can use for the analysis and how it is structured. A research paper typically consists of a title, an abstract and the main text.
In[1]:
# Importing modules
import pandas as pd
import os
os.chdir('..')
# Read data into papers
papers = pd.read_csv('./data/NIPS Papers/papers.csv')
# Print head
papers.head()
Data Cleaning
Drop Redundant Columns
For the analysis of the papers, we are only interested in the text data associated with the paper as well as the year the paper was published in. Since the file contains some metadata such as id’s and filenames, it is necessary to remove all the columns that do not contain useful text information.
In[2]: # Remove the columns papers = papers.drop(columns=['id', 'event_type', 'pdf_name'], axis=1) # Print out the first rows of papers papers.head()

Remove punctuation/lower casing
Now, we will perform some simple preprocessing on the paper_text in order to make them more amenable for analysis. We will use a regular expression to remove any punctuation in the title. Then we will perform lowercasing.
# Load the regular expression library
import re
# Remove punctuation
papers['paper_text_processed'] = papers['paper_text'].map(lambda x: re.sub('[,\.!?]', '', x))
# Convert the titles to lowercase
papers['paper_text_processed'] = papers['paper_text_processed'].map(lambda x: x.lower())
# Print out the first rows of papers
papers['paper_text_processed'].head()

Exploratory Analysis
In order to verify whether the preprocessing happened correctly, we can make a word cloud of the text of the research papers. This will give us a visual representation of the most common words. Visualization is key to understanding whether we are still on the right track! In addition, it allows us to verify whether we need additional preprocessing before further analyzing the text data.
Python has a massive number of open libraries! Instead of trying to develop a method to create word clouds ourselves, we’ll use Andreas Mueller’s wordcloud library
# Import the wordcloud library from wordcloud import WordCloud # Join the different processed titles together. long_string = ','.join(list(papers['paper_text_processed'].values)) # Create a WordCloud object wordcloud = WordCloud(background_color="white", max_words=5000, contour_width=3, contour_color='steelblue') # Generate a word cloud wordcloud.generate(long_string) # Visualize the word cloud wordcloud.to_image()

Prepare text for LDA Analysis
LDA does not work directly on text data. First, it is necessary to convert the documents into a simple vector representation. This representation will then be used by LDA to determine the topics. Each entry of a ‘document vector’ will correspond with the number of times a word occurred in the document (Bag-of-Words BOW Representation).
Next, we will convert a list of titles into a list of vectors, all with length equal to the vocabulary.
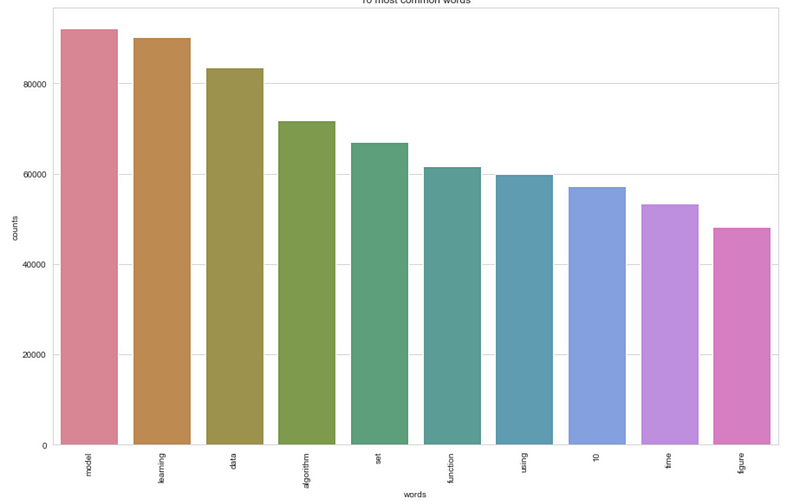
We’ll then plot the 10 most common words based on the outcome of this operation (the list of document vectors). As a check, these words should also occur in the word cloud.
# Load the library with the CountVectorizer method
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
%matplotlib inline
# Helper function
def plot_10_most_common_words(count_data, count_vectorizer):
import matplotlib.pyplot as plt
words = count_vectorizer.get_feature_names()
total_counts = np.zeros(len(words))
for t in count_data:
total_counts+=t.toarray()[0]
count_dict = (zip(words, total_counts))
count_dict = sorted(count_dict, key=lambda x:x[1], reverse=True)[0:10]
words = [w[0] for w in count_dict]
counts = [w[1] for w in count_dict]
x_pos = np.arange(len(words))
plt.figure(2, figsize=(15, 15/1.6180))
plt.subplot(title='10 most common words')
sns.set_context("notebook", font_scale=1.25, rc={"lines.linewidth": 2.5})
sns.barplot(x_pos, counts, palette='husl')
plt.xticks(x_pos, words, rotation=90)
plt.xlabel('words')
plt.ylabel('counts')
plt.show()
Initialise the count vectorizer with the English stop words
count_vectorizer = CountVectorizer(stop_words=‘english’)
Fit and transform the processed titles
count_data = count_vectorizer.fit_transform(papers[‘paper_text_processed’])
Visualise the 10 most common words
plot_10_most_common_words(count_data, count_vectorizer)
LDA model training and results visualization
The only parameter we will tweak is the number of topics in the LDA algorithm. Typically, one would calculate the ‘perplexity’ metric to determine which number of topics is best and iterate over different amounts of topics until the lowest ‘perplexity’ is found. We’ll cover the model evaluation and tuning concept along with exploring Gensim, widely used natural language processing toolkit, in the next article.
import warnings
warnings.simplefilter(“ignore”, DeprecationWarning)Load the LDA model from sk-learn
from sklearn.decomposition import LatentDirichletAllocation as LDA
Helper function
def print_topics(model, count_vectorizer, n_top_words):
words = count_vectorizer.get_feature_names()
for topic_idx, topic in enumerate(model.components_):
print(“\nTopic #%d:” % topic_idx)
print(" ".join([words[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))Tweak the two parameters below
number_topics = 5
number_words = 10Create and fit the LDA model
lda = LDA(n_components=number_topics)
lda.fit(count_data)Print the topics found by the LDA model
print(“Topics found via LDA:”)
print_topics(lda, count_vectorizer, number_words)

Analyzing LDA model results
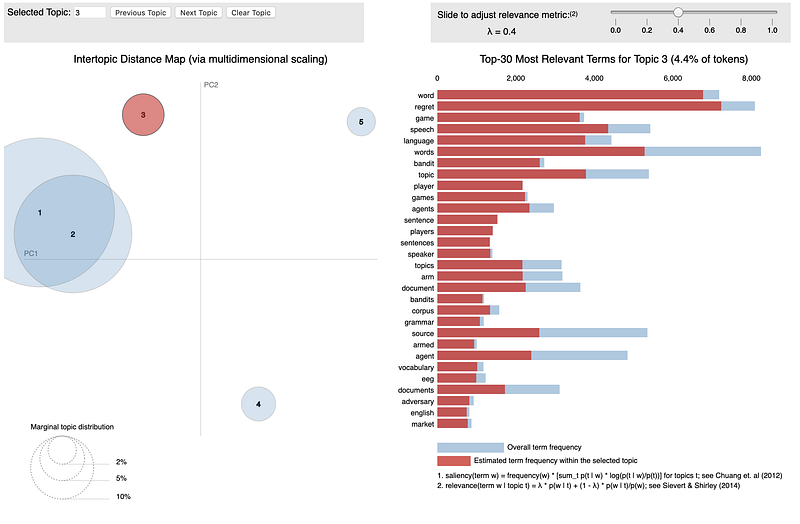
pyLDAvis package is designed to help users interpret the topics in a topic model that has been fit to a corpus of text data. The interactive visualization pyLDAvis produces is helpful for both:
- Better understanding and interpreting individual topics, and
- Better understanding the relationships between the topics.
For (1), you can manually select each topic to view its top most freqeuent and/or “relevant” terms, using different values of the λ parameter. This can help when you’re trying to assign a human interpretable name or “meaning” to each topic.
For (2), exploring the Intertopic Distance Plot can help you learn about how topics relate to each other, including potential higher-level structure between groups of topics.
%%time
from pyLDAvis import sklearn as sklearn_lda
import pickle
import pyLDAvis
LDAvis_data_filepath = os.path.join(‘./ldavis_prepared_’+str(number_topics))# this is a bit time consuming - make the if statement True
# if you want to execute visualization prep yourself
if 1 == 1:
LDAvis_prepared = sklearn_lda.prepare(lda, count_data, count_vectorizer)
with open(LDAvis_data_filepath, ‘w’) as f:
pickle.dump(LDAvis_prepared, f)load the pre-prepared pyLDAvis data from disk
with open(LDAvis_data_filepath) as f:
LDAvis_prepared = pickle.load(f)
pyLDAvis.save_html(LDAvis_prepared, ‘./ldavis_prepared_’+ str(number_topics) +‘.html’)
Machine learning has become increasingly popular over the past decade, and recent advances in computational availability have led to exponential growth to people looking for ways how new methods can be incorporated to advance the field of Natural Language Processing. Often, we treat topic models as black-box algorithms, but hopefully, this post addressed to shed light on the underlying math, and intuitions behind it, and high-level code to get you started with any textual data.
As described above, in the next article, we’ll go one step deeper into understanding one can evaluate the performance of topic models, tune the hyper-parameters to get it to the point that could be deployed into production.
Originally published by Shashank Kapadia at https://towardsdatascience.com/end-to-end-topic-modeling-in-python-latent-dirichlet-allocation-lda-35ce4ed6b3e0
Thanks for reading :heart: If you liked this post, share it with all of your programming buddies! Follow me on Facebook | Twitter
Learn More
☞ Machine Learning with Python, Jupyter, KSQL and TensorFlow
☞ Python and HDFS for Machine Learning
☞ Applied Deep Learning with PyTorch - Full Course
☞ Tkinter Python Tutorial | Python GUI Programming Using Tkinter Tutorial | Python Training
☞ Machine Learning A-Z™: Hands-On Python & R In Data Science
☞ Python for Data Science and Machine Learning Bootcamp
☞ Data Science, Deep Learning, & Machine Learning with Python
☞ Deep Learning A-Z™: Hands-On Artificial Neural Networks
☞ Artificial Intelligence A-Z™: Learn How To Build An AI
#python #machine-learning