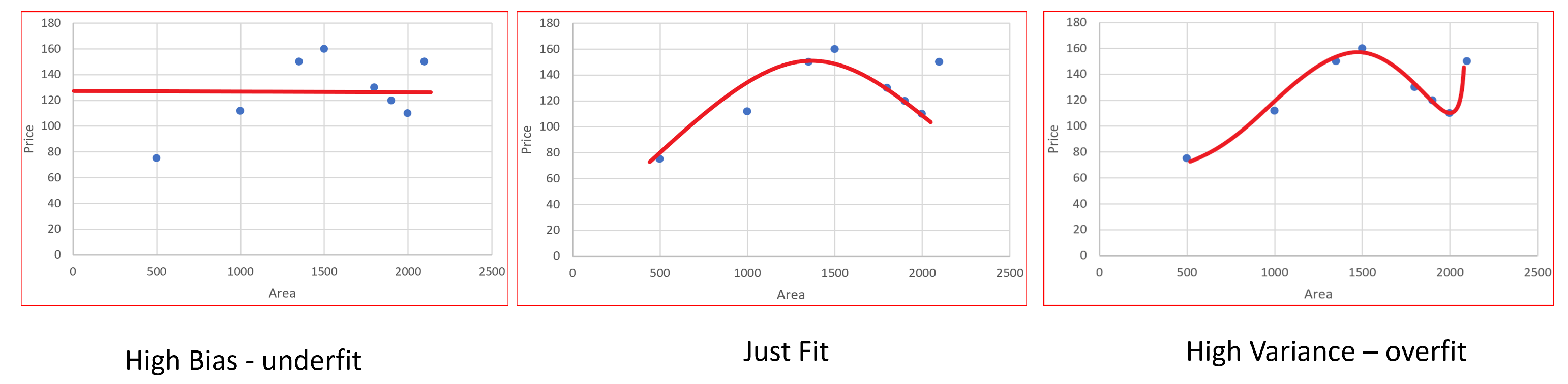
If you run a learning algorithm and it doesn’t perform good as you are hoping, it will be because you have either a high bias problem or a high variance problem, in other words, either an underfitting problem or an** overfitting** problem almost all the time.

It is vital to understand which of these two problems is bias or variance or a bit of both because knowing which of these two things is happening would give a very strong indicator for promising ways to try to improve the algorithm.

High Bias :
- The graph has an overly low order polynomial to fit the data. The hypothesis will not the fit the training set well, we need a higher degree polynomial to fit the data in this case.
- The training set error and cross validation error both are going to be high.
- Cross validation error will close to or slightly higher than training set.
- This is the case of underfitting.
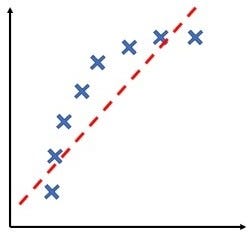
Underfitting
If these are the signs then your algorithm might be suffering from high bias.
High Variance :
- The graph has too large degree of polynomial to fit the data. The hypothesis will not fit the training set well, we need a bit lower degree polynomial to fit the data in this case.
- The data will be fitting the training set very well i.e. the training set error will usually be low but the error of cross-validation set will be much larger than the training error.
- This is the case of overfitting.
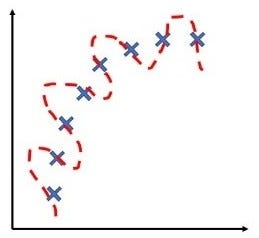
Overfitting
If these are the signs then your algorithm might be suffering from high variance.
#variance #machine-learning #bias #overfitting #underfitting #deep learning
4.05 GEEK