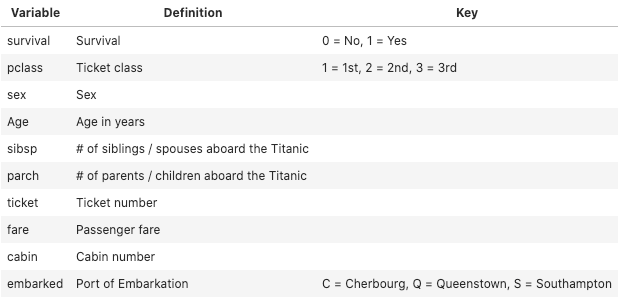
This post will serve as a step by step guide to build pipelines that streamline the machine learning workflow. I will be using the infamous Titanic dataset for this tutorial. The dataset was obtained from Kaggle. The goal being to predict whether a given person survived or not. I will be implementing various classification algorithms, as well as, grid searching and cross validation. This dataset holds records for each passenger consisting of 10 variables (see data dictionary below). For the purposes of this tutorial, I will only be using the train dataset, which will be split into train, validation, and test sets.

(Image by author)
Why Pipelines?
The machine learning workflow consists of many steps from data preparation (e.g., dealing with missing values, scaling/encoding, feature extraction). When first learning this workflow, we perform the data preparation one step at a time. This can become time consuming since we need to perform the preparation steps to both the training and testing data. Pipelines allow us to streamline this process by compiling the preparation steps while easing the task of model tuning and monitoring. Scikit-Learn’s Pipeline class provides a structure for applying a series of data transformations followed by an estimator (Mayo, 2017). For a more detailed overview, take a look over the documentation. There are many benefits when implementing a Pipeline:
#machine-learning-pipeline #crossvalidation #gridsearchcv #machine-learning #pipeline
