In this work, we are going to classify whether an online transaction is fraudulent or not. It is a binary target, named: isFraud. A lot of us have been in a situation where a transaction has been canceled without our consideration. To have a better algorithm that only cancels the fraudulent transaction and doesn’t just result in being embarrassed in a store. While it is often embarrassing at the moment, but this system is truly sparing consumers millions of dollars every year.
The dataset is provided by Vesta’s real-world e-commerce transactions that includes a wide range of features from the country to the recipient email domain. With this dataset, we apply the Lightgbm algorithm on a challenging large e-scale dataset. Improving the effectiveness of fraudulent transaction warnings will save lots of people the trouble of false positive. If you would like to see an implementation in PySpark, read the next article.
But how can we analyze these sorts of problems?
The Data
The first step would be to download the dataset. The training set is used here, which has two sections. One is train_transcation and the other is train_identity.
train_identity = pd.read_csv(‘../input/ieee-fraud-detection/train_identity.csv’)
train_transaction = pd.read_csv(‘../input/ieee-fraud-detection/train_transaction.csv’)
I am going to merge these two DataFrames on a column named “TransactionID”. But not all transactions have corresponding identity information.
train_transaction_identity = train_transaction.merge(train_identity, on=’TransactionID’,how=’left’ )
The dataset contains several features that I only mention a few of them below.
- TransactionDT: timedelta from a given reference datetime (It is not actual time stamp)
- TransactionAMT: transaction payment amount in US Dollar (some of them exchanged from other currencies).
- card1 — card6: payment card information, such as card type.
- addr: address
Please look at the data source link if you want to have a better understanding of features.
As it is displayed below, memory usage is over 1.9+ GB. We can reduce memory usage without losing any data.
train_transaction_identity.info()
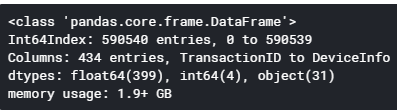
First, I have found out different types of features include Object, float, and Integer. By using .info in the Pandas library, you can find out the size of memory usage. The majority is occupied by float64. I have changed those columns from float64 to float32. As you can see memory usage is reduced by almost 50%.
#fraud-detection #classification #lightgbm #imbalanced-data #data analysis
