With the rise of machine learning, we have seen the rise of many great frameworks and libraries like sci-kit learn, Tensorflow, Pytorch. These frameworks have made it easier for users to create machine learning models easily. But still one needs to follow the whole procedure that includes Data preparation, Modelling, Evaluation. Data preparation contains data cleaning and pre-processing. Modeling takes in the pre-processed data and uses algorithms to predict the result. Evaluation gives us a measure of how well our algorithm is performing. Due to these libraries and frameworks, our time to write everything is reduced but still, we need to write a handful amount of code.
“Machine intelligence is the last invention that humanity will ever need to make.” -Nick Bostrom
The advancements in this field are increasing day by day with the help of amazing open source communities which gave rise to the existing frameworks. Think about a framework that does all of the above-mentioned processes in a single line. Yes, you read it right, now you can also do that. Libra is a framework that does that work for you in a single line. It’s also easy to use even for a non-technical person. Libra requires the least average number of lines to train the model.
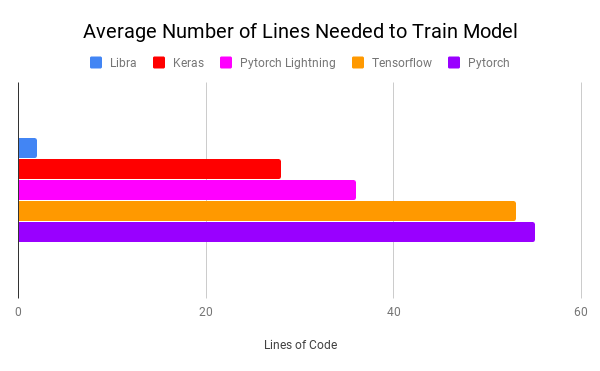
Image taken from the documentation
In this blog, I will give complete guidance on how to use Libra. I will be taking different datasets for a different problem and will show you step by step approach.
Credit Card Fraud Detection Using Libra
I have used the Kaggle dataset for the prediction of credit card fraud. The data has already gone through the principal component analysis, so it is now reduced to less dimensional data as compared to the original one. It requires following a systematic approach while solving this problem. In the General way, you will follow the sequence mentioned in the first paragraph. But with Libra, you don’t have to worry about it.
Link of dataset https:/``[/www.kaggle.com/mlg-ulb/creditcardfraud](https://colab.research.google.com/drive/1khr-nqQVkP_XMUQ5y8GWrK5AUS41lyzC#)
Most of the transactions in this data are Non-Fraudulent (99.83 Percent) of the time, while Fraudulent transactions occur (0.17 percent) of the time in the dataset. Which means that the data is highly imbalanced. Let us see how well Libra preprocess the data and gives us the result.
Installing Libra
pip install -U libra
Importing client from libra
from libra import client
Using Libra
Everything is built around the client object. You can call different queries on it and everything will be stored under the models field of the object.
We pass the location of our file in the client object and name it as newClient. Now to access various queries refer to the documentation. I am using a decision tree here. Instruction in the English language is a statement that represents the task you would like to complete. For example, predict the median house value, or please estimate the number of households. Else the instruction should correspond to a column in the dataset. Libra Automatically detects the target column but just to be sure that it select the right column, I have passed the target column name.
#deeplearing #online-learning #data-science #future #machine
