Many datasets are stored as data frames. Learn how to create a data frame, select interesting parts of a data frame, and order a data frame according to certain variables.

What is a data frame?
Recall that for matrices all elements must be the same data type. However, when doing market research, you often have questions such as:
- ‘Are you married’ or other ‘yes/no’ questions (
logical) - ‘How old are you?’ (
numeric) - ‘What is your opinion on this product?’ or other ‘open-ended’ questions (
charactera )
The output, namely the respondents’ answers to the questions above is a data set of different data types. It is common to work with data sets that contain different data types instead of just one.
A data frame has the variables of a data set as columns and the observations as rows.
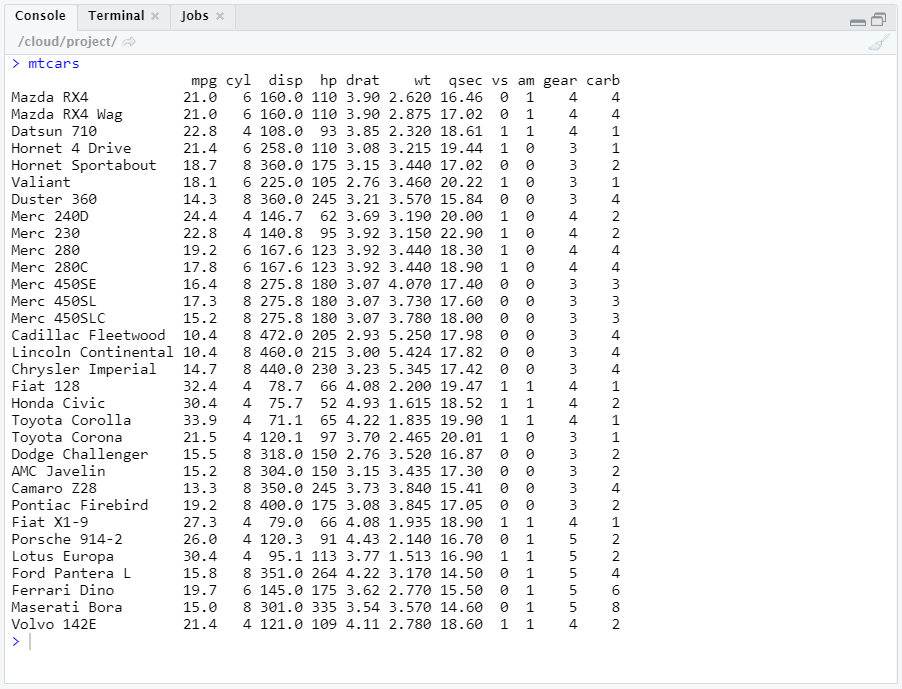
Here is an example of a built-in data frame in R.
Taking a Look at the Data Set
Working with large data sets is not uncommon. When working with (extremely) large data sets and data frames, you must first develop a clear understanding of the structure and main elements of the data set. Therefore, it can often be useful to show only a small part of the entire data set.
To do this in R, you can use the functions [head()](https://www.rdocumentation.org/packages/utils/versions/3.6.2/topics/head) or [tail()](https://www.rdocumentation.org/packages/utils/versions/3.6.2/topics/head) . The head() function shows the first part of the data frame. The tail() function shows the last part. Both functions print a top line called the ‘header’ which contains the names of the different variables in the data set.
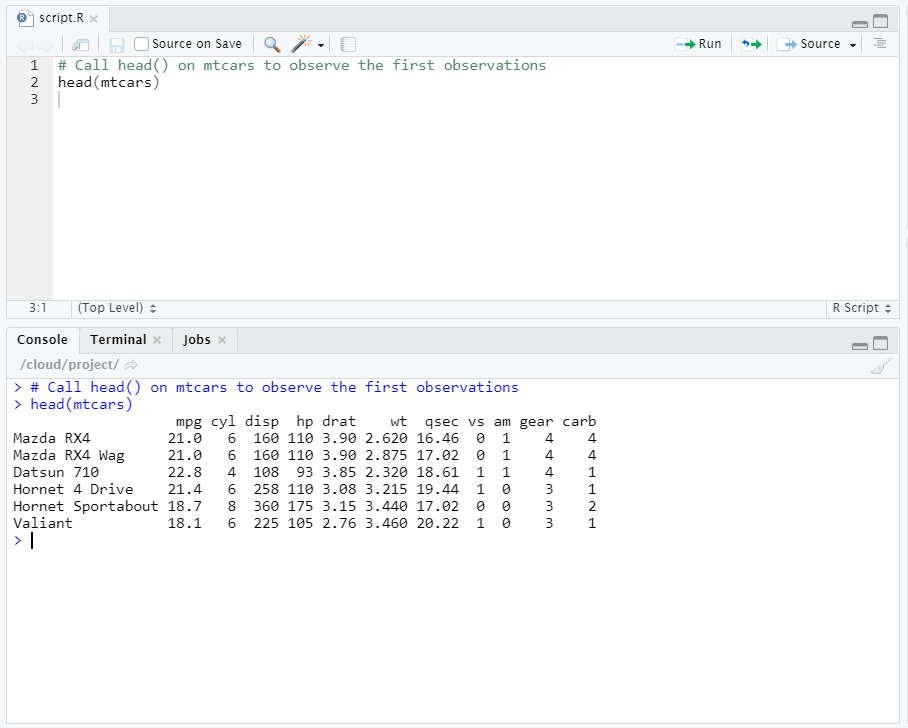
Taking a Look at the Structure
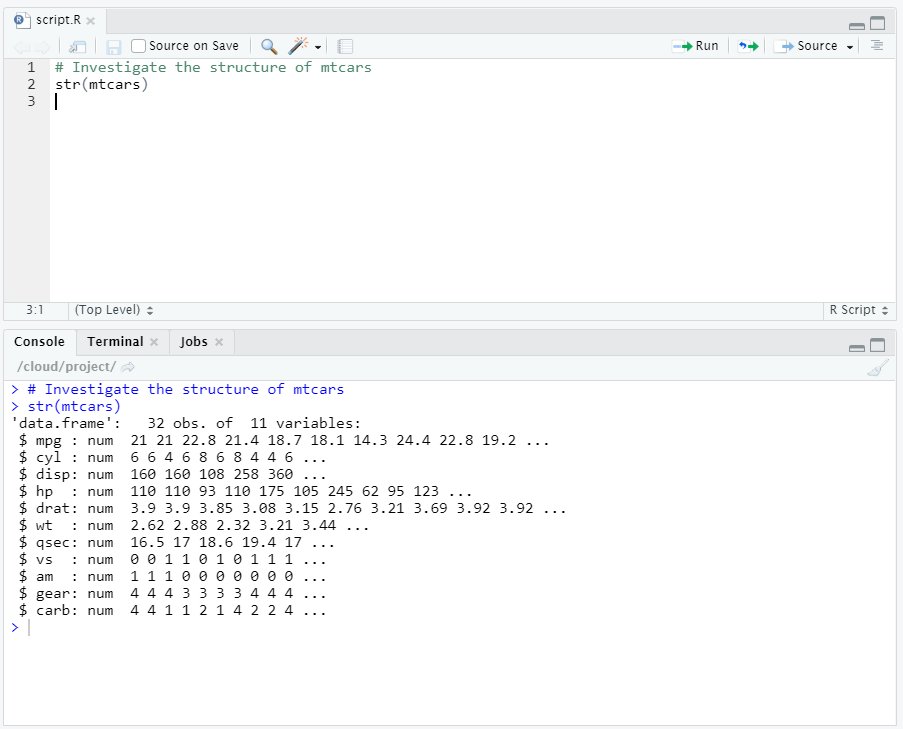
Another method to get a rapid overview of the data is the [str()](https://www.rdocumentation.org/packages/utils/versions/3.6.2/topics/str) function. The str() function shows the structure of the data set. For a data frame it gives the following information:
- The total number of observations (e.g. 32 car types)
- The total number of variables (e.g. 11 car features)
- A full list of the variables names (e.g.
mpg,cy1….) - The data type of each variable (e.g.
num) - The first observations
When you receive a new data set or data frame, applying the str() function is often the first step. It is a great way to get more insight into the data set before deeper analysis.
To investigate the structure of [mtcars](https://www.rdocumentation.org/packages/datasets/versions/3.6.2/topics/mtcars) , use the str() function.
Creating a Data Frame
Let’s construct a data frame that describes the main characteristics of the eight planets in our solar system. Suppose the main features of a planet are:
- The type of planet (Terrestrial or Gas Giant)
- The planet’s diameter relative to the diameter of the Earth.
- The planet’s rotation across the sum relative to that of the Earth.
- If the planet has rings or not (TRUE or FALSE).
Some research shows that the following vectors are necessary: name , type , diameter , rotation , and rings . The first element in each of these vectors corresponds to the first observation.
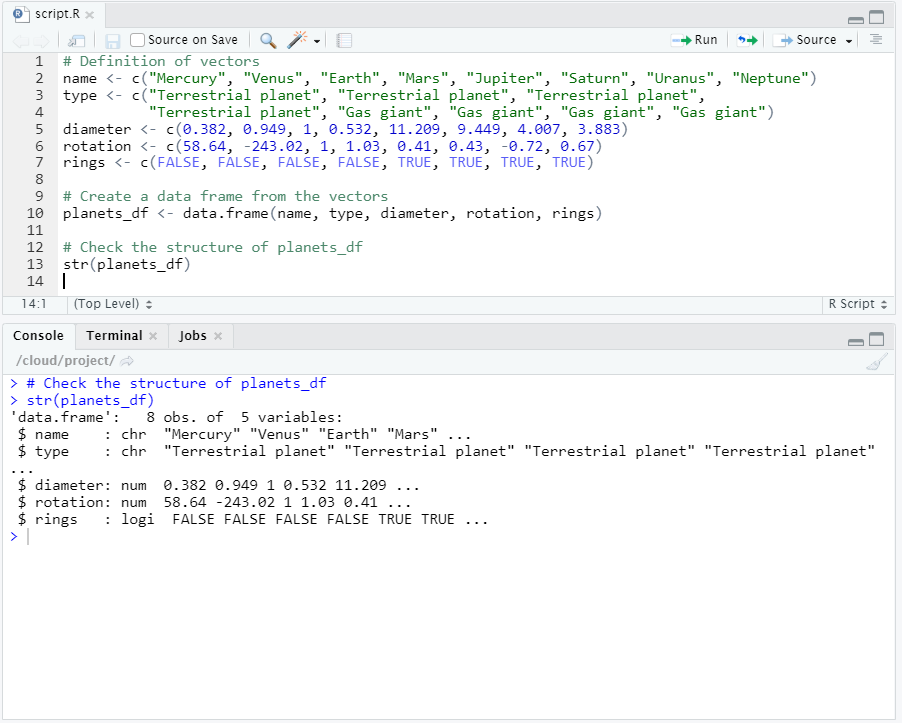
# Definition of vectors
name <- c("Mercury", "Venus", "Earth", "Mars", "Jupiter", "Saturn", "Uranus", "Neptune")
type <- c("Terrestrial planet", "Terrestrial planet", "Terrestrial planet",
"Terrestrial planet", "Gas giant", "Gas giant", "Gas giant", "Gas giant")
diameter <- c(0.382, 0.949, 1, 0.532, 11.209, 9.449, 4.007, 3.883)
rotation <- c(58.64, -243.02, 1, 1.03, 0.41, 0.43, -0.72, 0.67)
rings <- c(FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE)
To construct a data frame, use the [data.frame()](https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/data.frame) function. As arguments, the vectors from before must be passed: they will become the different columns of the data frame. Because every column has the same length, the vectors you pass should also have the same length. Remember though, it is possible that they contain different types of data.
To construct the planets data frame, we will use the data.frame() function and pass the vectors name, type , diameter , rotation , and rings as arguments.
# Create a data frame from the vectors
planets_df <- data.frame(name, type, diameter, rotation, rings)
The data frame has 8 observations and 5 variables.
Let’s investigate the structure of the new data frame. Recall that we can use the str() function to accomplish this.
#data-science #programming #r #data-analysis #data analysis
