Data leakage in machine learning pipelines can cause havoc for your model. In this post, I’m going to share an amazingly simple way to detect data leakages using NANs and complex numbers while treating your ML pipeline as a black box. I’ll talk very briefly about what data leakage is. I’ll also talk about leak-detect, a python package I’m releasing to do all this in one line code.
A quick intro to data leakage
The most precise way to describe data leakage could be this:
Data leakage in an ML model occurs when data used to create predictor variables during training time is unavailable at the time of inference.
Clearly, using data(features) unavailable at inference time during training leads to model underperforming in production. This under-performance could mean millions of lost dollars depending on the scale of your company!
An example of leakage
What are some ways feature creation pipelines can introduce data leakage?
- Using target or data used to create target for feature engineering.
- Using data from future periods for feature engineering.
First is generally easier to detect and keep track of. So, let’s try to understand the second one using an example. Consider you are trying to predict stock price of a company after 5 days. Our data contains date and daily open price.
## target (to be predicted): Open price after 5 days.
data['target'] = data['open_price'].shift(-5)
We want to create various hand-made features for this task. Say, one feature we want is ‘price on the previous day’.
data['price_previous_day'] = data['open_price'].shift(1)
# .shift(1) gives value from previous row
But instead of doing .shift(1), let’s say by mistake we did .shift(-1)and used values from the next row of open price as a feature. We just created ‘price on the next day’ instead. This is a leaky feature because it uses data from a future period.
There are many best practices to follow to avoid leakage, but none of these can make you 100% sure that your pipeline is not leaky. This is where NANs and complex numbers come in! This methodology can be looked at as a unit test for data leakages.
The Methodology
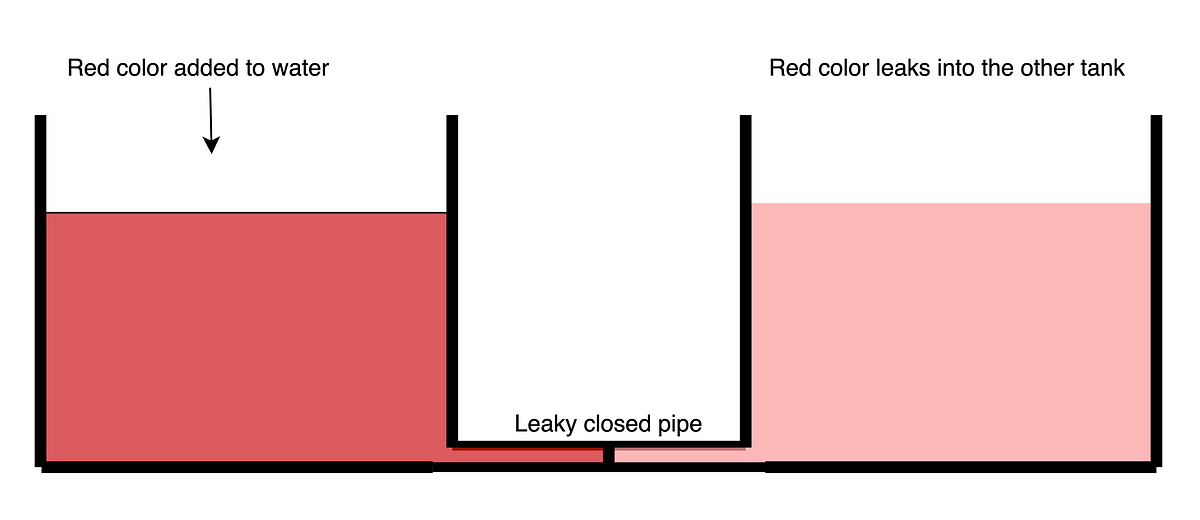
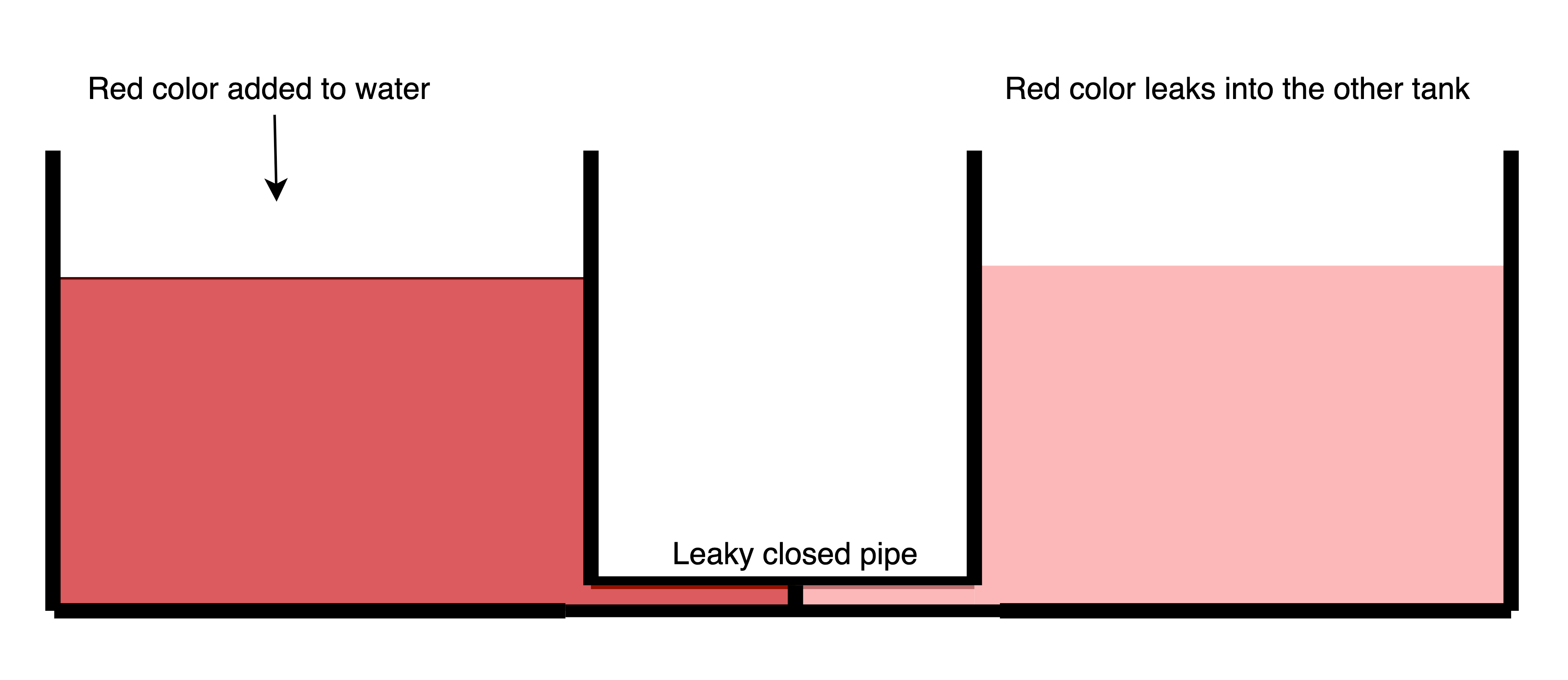
Before getting to the methodology, let’s do an analogy first :).
Let’s say you have two tanks connected through a pipe which is closed. How can we detect that this pipe is indeed closed and is not leaky without inspecting the pipe? You can add color to one tank and check if the other tank also gets that color. **Just like watercolors, NANs and complex numbers are ideal for leakage detection tasks because they have the ability to persist after any operation with real numbers. **Operations like addition, subtraction, etc between a real number and NAN or complex number yield NAN or complex number respectively. Of course, there are exceptions to this and we will come to that later.
In the stock price example, let’s say we set open price on a specific day D to NAN and create our features using this data. ‘Price on next day’ (leaky feature) will have NAN value for day D-1, whereas ‘price on previous day’ (non-leaky) will have it for day D+1.
#machine-learning #data-leakage-prevention #python #data-analysis #data-science #data analysis