In recent years, stateless middle-tiers have been touted as a simple way to achieve horizontal scalability. But the rise of microservices has pushed the limits of the stateless architectural pattern, causing developers to look for alternatives.
Stateless middle-tiers have been a preferred architectural pattern because they helped with horizontal scaling by alleviating the need for server affinity (aka sticky sessions). Server affinity made it easy to hold data in the middle-tier for low-latency access and easy cache invalidation. The stateless model pushed all “state” out of the middle-tier into backing data stores. In reality the stateless pattern just moved complexity and bottlenecks to that backing data tier. The growth of microservice architectures exacerbated the problem by putting more pressure on the middle tier, since technically, microservices should only talk to other services and not share data tiers. All manners of bailing wire and duct tape have been employed to overcome the challenges introduced by these patterns. New patterns are now emerging which fundamentally change how we compose a system from many services running on many machines.
To take an example, imagine you have a fraud detection system. Traditionally the transactions would be stored in a gigantic database and the only way to perform some analysis on the data would be to periodically query the database, pull the necessary records into an application, and perform the analysis. But these systems do not partition or scale easily. Also, they lack the ability for real-time analysis. So architectures shifted to more of an event-driven approach where transactions were put onto a bus where a scalable fleet of event-consuming nodes could pull them off. This approach makes partitioning easier, but it still relies on gigantic databases that received a lot of queries. Thus, event-driven architectures often ran into challenges with multiple systems consuming the same events but at different rates.
Another (we think better) approach, is to build an event-driven system that co-locates partitioned data in the application tier, while backing the event log in a durable external store. To take our fraud detection example, this means a consumer can receive transactions for a given customer, keep those transactions in memory for as long as needed, and perform real-time analysis without having to perform an external query. Each consumer instance receives a subset of commands (i.e., add a transaction) and maintains its own “query” / projection of the accumulated state. For instance:
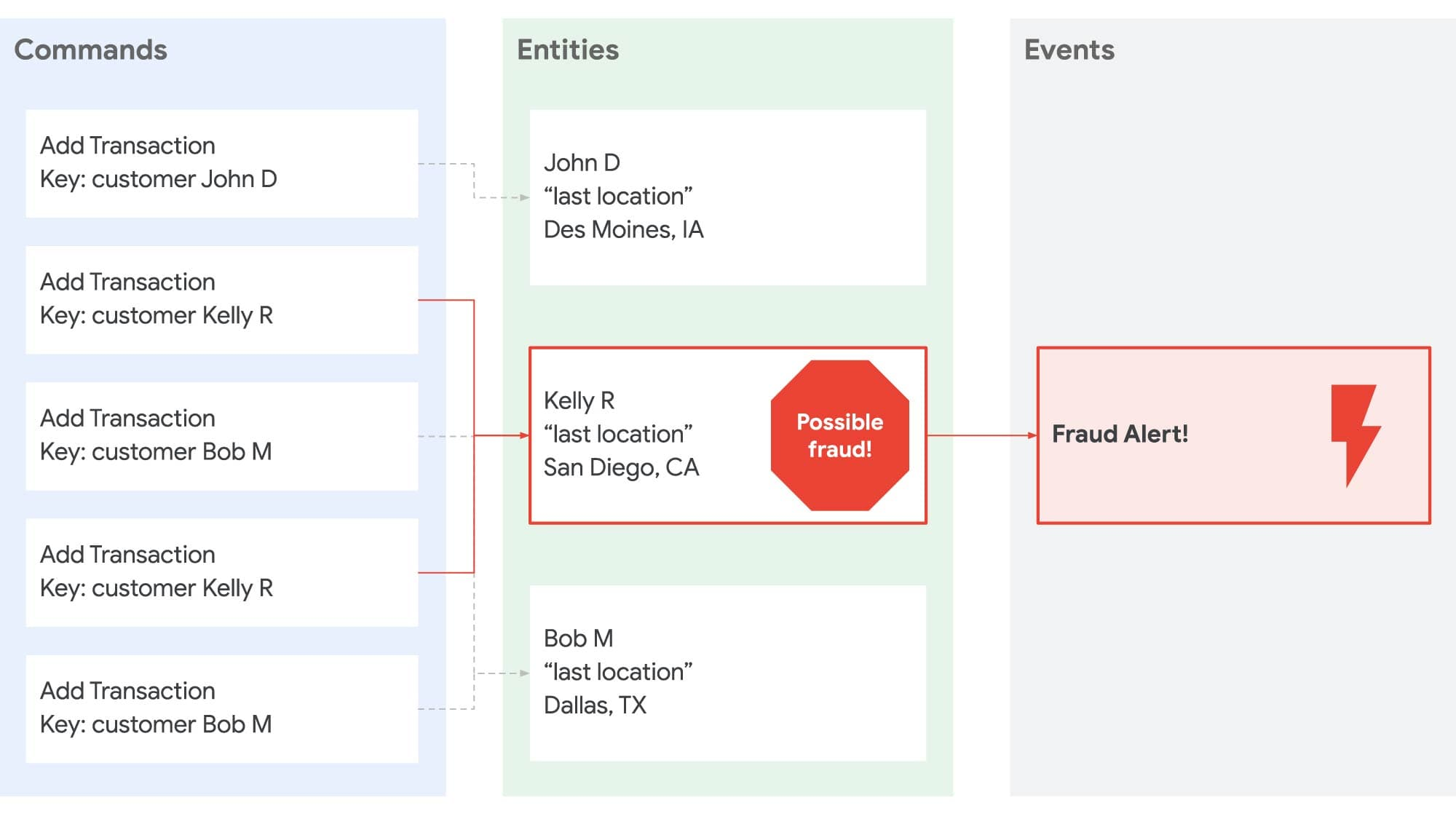
By separating commands and queries we can easily achieve end-to-end horizontal scaling, fault tolerance, and microservice decoupling. And with the data being partitioned in the application tier we can easily scale that tier up and down based on the number of events or size of data, achieving serverless operations.
#application development #serverless #google cloud platform #developers & practitioners