I recently came across the following programming exercise used by Microsoft for interviewing software developers and data engineers, and was curious how implementing such an algorithm using different abstract data types and programming languages would perform:
Given an unsorted array of integers, find the length of the longest consecutive elements sequence. For example, given [100, 4, 200, 1, 3, 2], the longest consecutive element sequence is [1, 2, 3, 4]. Return its length: 4. Your algorithm should run in O(n) complexity.
The initial implementation of the algorithm in conformance of O(n) complexity itself was strait forward, especially when only using six integers. I became curious how the performance characteristics of the algorithm might change using different programming languages and specific abstract data types, and also vary at increasing larger scale of data (not just 6 integer elements!). After implementing the algorithm using several languages, here is what was measured using Python 3.8, C++20 using GCC v10.0.1, Rust 1.43.1, and Java 14 across an increasing number of integer elements…

The table contains the time, measured in seconds, to execute the algorithm on the exact same host machine (a System76 Oryx Pro Laptop running Ubuntu 20.04) using different abstract data types that hold an increasing number of standard integer types. In certain cases where “nan” is present, a timed analysis was not performed — it most of these cases it was already obvious that implementation of the algorithm was inefficient. In other cases , a timed analysis was not completed due to the inability of the algorithm to execute with 64GB of memory. In all cases, a “nan” represents an inability for the particular implementation to meet scale requirements.
A visual below shows the best performing abstract data types for each of the programming languages up to 100 million elements (Note: Python and Java did not scale past this point).
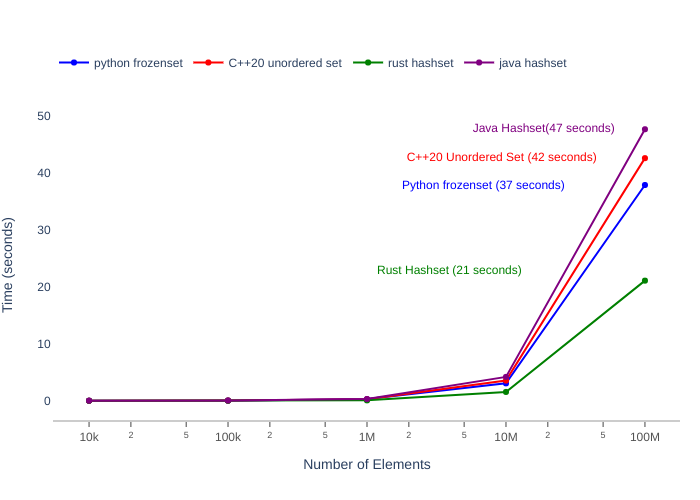
Figure-2: Best Performing Abstract Data Types for Multiple Languages
B23 Practical Algorithm Use Cases — Geospatial and Computer Vision Machine Learning
A common use case for B23 that is relevant to this exercise is the daily processing billions of rows of mobile location data points which are comprised of latitude and longitude values. Identifying sequences of these points and using the appropriate data structures at scale and speed are critical for a several of our analytics. GDAL¹ is a common geospatial library we use that has bindings for the languages above and allow us even greater flexibility in geospatial analysis.
#computer-science #rustlang #rust #data analysis
