A simple hands-on practice on Scikit-learn. In this work I have tried to showcase the housing prices in California, datasets are available on GitHub
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
housing = pd.read_csv('housing.csv')
housing.head()


housing.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.5+ MB
- There is 20,640 instance in the dataset, which means that it is fairly small by Machine learning standards. Notice the total_bedrooms attribute has only 20,433 non-null values, meaning that 207 districts are missing this feature. We need to take care of this later.
- ocean_proximity column was repetitive, which means it is probably a categorical attribute, we will see how many districts belong to each category by using the value_counts() method.
Big Data Jobs
housing['ocean_proximity'].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
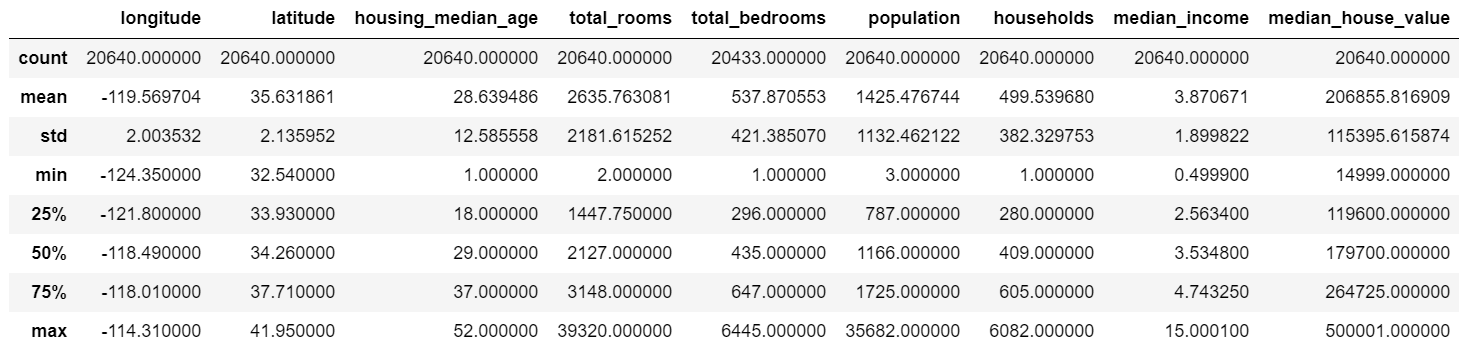
housing.describe()
From the histogram, we can see that slightly over 800 districts have a median_house_value equal to about $100,000.
housing.hist(bins=50, figsize=(20,15))
plt.show()
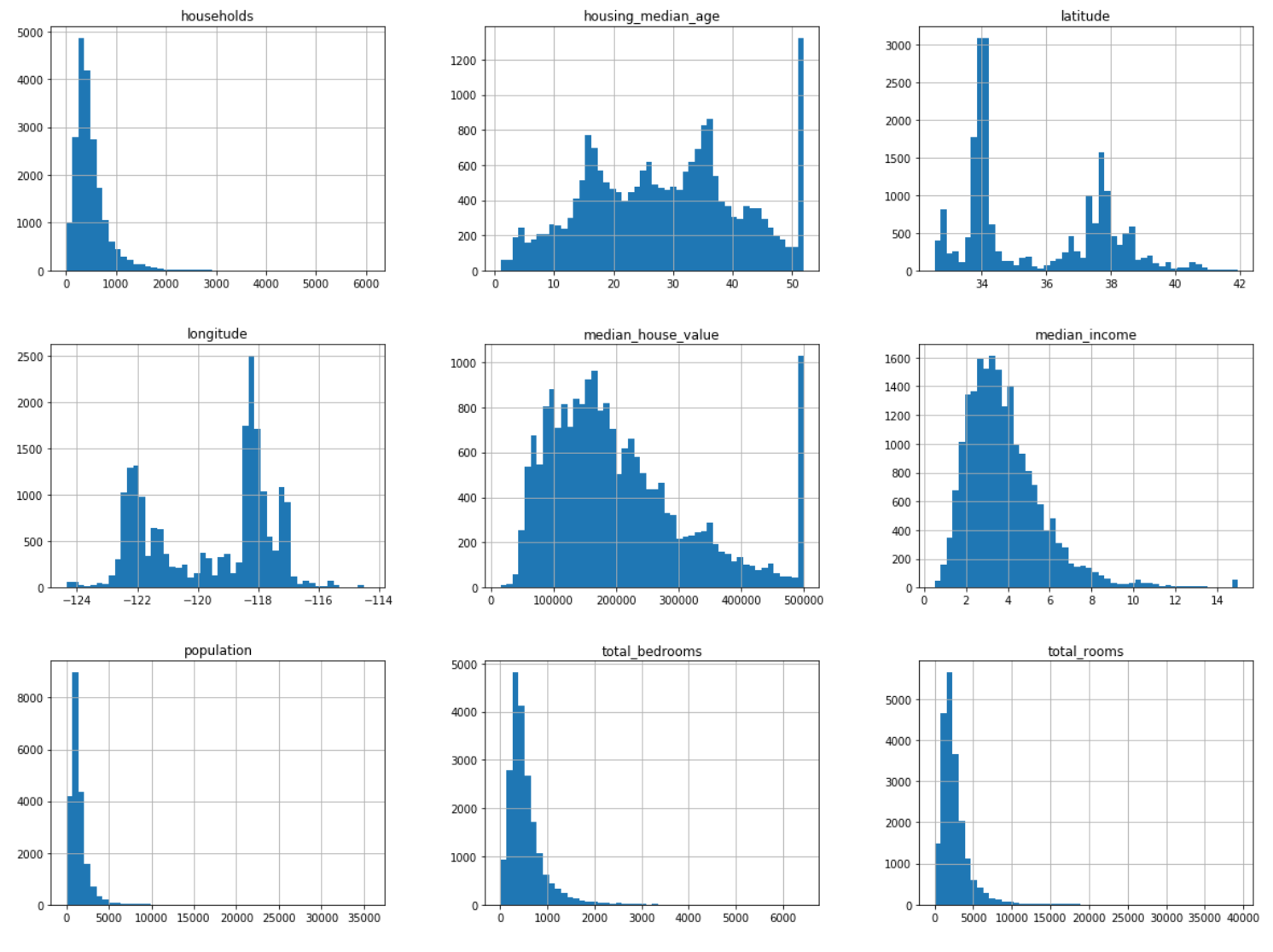
- Since the median income is a very important attribute to predict median housing prices. If we look at the median income histogram more closely most of the median income values are clustered around 2 to 5 (i.e., $20,000 — $50,000), but some median goes far beyond 6 ($60,000).
- It is important to have a sufficient number of instances in our dataset for each stratum, or else the estimation of the dataset may be biased. This means that we should not have too many strata.
#scikit-learn #ai #data-model #data-science #machine-learning #deep learning

2.35 GEEK