Differences between React Redux Thunk and Elm
Introduction
It’s a bit easier to learn Elm if you compare it to things you know. If you know React and Redux, then comparing them can help a lot to understand Elm concepts. I’ve built the same application in React Redux Thunk and Elm so we can compare them together. The end result is a table of things you can paginate through. Comparing these 2 applications is apples to apples. They’re identical to the end user. Yet the technologies behind them are apples to oranges. Seeing those deviations using familiar tech in the same application can help your understanding.
Below, I’ve linked to both applications code bases which you can download and run locally if you wish.
Company Dashboard Code – React Redux Thunk
What is React, Redux, Thunk, and Elm?
React is a JavaScript library that allows you to ensure your HTML and CSS are in sync with your data. You use this to build single page web applications.
Redux is a library that allows you have a single variable for your data model. This ensures your applications are predictable and testable. It is the core of the Elm architecture and is often used in React.
Thunk is a library that allows your Redux actions to be asynchronous.
Elm is a functional programming language, compiler, repl, package manager, and a set of libraries to build single page applications. You write in Elm and it compiles to JavaScript.
Building and Compiling React
You build React applications using Node.js. Using a package manager like Yarn or npm to install libraries, and run commands to test and build your application for production. Yarn and Node utilize npm, the Node Package Manager, to install libraries and interface with Node. Yarn is used mainly because it has advanced features that npm doesn’t have, and it can yield more deterministic installs and builds compared to npm. Front-end applications tend to have more libraries than back-end Node API ones. Yarn is used more often in React given it’s front-end. The source of truth is usually a package.json, a JSON file that contains all the libraries to be installed and commands needed to test and build the application. This holds true whether the application is regular JavaScript, using advanced ES6 features, using advanced compilation tools like Babel and Webpack, and/or utilizing typed languages like as Flow and TypeScript.
The easiest way to build them at the time of this writing is using create-react-app, which abstracts most of the compilation and build toolchain away into simple commands with updates being usually as simple as updating the react-scripts library.
Like Elm, React can compile to simple components embedded in other web applications. It can also compile too large, single page applications.
Building and Compiling Elm
For simple applications, Elm the language is compiled to JavaScript and HTML through the Elm compiler via elm make. For more advanced applications, the compiler will output just JavaScript that you embed in your HTML. Libraries are installed through elm install and written in elm.json. While there is a local web server called elm reactor, it lacks many basic features such as auto-refresh that many other JavaScript tools have. Use elm-live instead.
Like React, you’ll use Node, npm, and/or yarn to various degrees of complexity. Like React, Elm can compile to simple components embedded into other web applications. Elm can also be used to build large, single page applications. The common ways to build at the time of this writing is create-elm-app which isn’t very friendly behind corporate proxies, and the simpler elm-live. If you’re not on a corporate network, create-elm-app is also an option.
Although Elm is fully featured, it’s still missing features native to JavaScript. As such you’ll sometimes interface with JavaScript. At the time of this writing for Elm version 0.19.0, this includes binary file upload, and application storage to name just two. This ensures you can benefit from Elm’s features, but not have to wait on them or the open source community to build Elm versions of those features.
HTML in React
HTML in React is rendered by React via JSX. They handle all the efficient ways of updating it, the cross-browser challenges, etc. All you do is provide a function or class with a render function that returns this JSX.
const Message = () => (<div>Sup</div>)
Then you can use this “component” like a normal HTML tag in your other React JSX:
<Message />
React became popular with functional programmers because it was basically a pure function for the DOM. A pure function is a function that always outputs the same thing if you give it the same arguments with no side effects. You give the Message component above an Object, and React will render the same DOM each time. This input in React is called “props” or properties.
const Message = props => (<div>Sup {props.name}</div>
Whenever that props.name value changes, so too will the HTML React renders. You can embed JavaScript or just values like the above using the squiggle braces ({}). There are a variety of rules that make JSX not exactly like HTML. There are a host of them, but examples include event objects are a custom copy to prevent certain bugs, and using onClick instead of onclick for events. That said, React has done a great job to make it feel and work like you’d expect HTML to work.
HTML in Elm
Everything in Elm is a function. HTML is no different. Each HTML element has a corresponding function name. All HTML elements typically have attributes and contents. Below, the div tag has a style attribute and text contents:
<div style="color: red;">Sup</div>
In Elm, you’d import and use the div, style, and text functions to accomplish the same thing:
div [ style "color" "red"] [ text "Sup" ]
Elm functions do not use commas, and parenthesis are optional in most cases. Above the div function takes 2 list arguments, the style function 2 string arguments, and text 1 string. Rewritten in JavaScript that’d be:
div([style('color', 'red')], [text('Sup')])
Working With CSS in React
Cascading Style Sheets have a lot of different ways of working in React depending on what you’re building, and the team’s style. Component based styles have risen in popularity in React. The first reason for this is it’s easier for modern tools to “only compile what you use”; if you don’t use the component, it won’t compile the CSS in. Larger websites that have accrued many shared styles from many teams over years have this issue. Since the tools aren’t very good to ensure modifying styles doesn’t break something else unintentionally, teams end up adding new styles of their own to prevent breakage which just adds to the file size and speed slow down despite not being inline. The second reason for this is co-location. The styles that handle the component are right next to it; you don’t have to hunt around various css, sass, or externalized html template files to “piece together” how a component is supposed to look.
React supports normal className attributes to emulate how the class attribute works. You can also use style create CSS through JavaScript Objects. This is popularized by the “CSS-in-JS” movement, and keeps your styles co-located to the components they are affecting. There are libraries that take this concept to the nth degree such as Emotion. Teams will either standardize on one approach depending on team make up, and/or use a multitude depending upon what they’re building and interfacing with. Beyond the className and style attributes for JSX, React’s version of HTML, React doesn’t prescribe how you handle CSS.
Styling with className:
<div className="textColor">Sup</div>
Styling with style:
const myStyles = {color: 'red'}
<div style={myStyles}>Sup</div>
Working with CSS in Elm
Elm, like React, doesn’t prescribe a way how you handle CSS. Elm’s version of HTML is functions. There is a function for each html element. If you’re adding styles to a div [] [], then you’d go div [ style "color" "red"] []. If you want to use a css class, you’d go div [ class "textColor" ] [].
The only modification is if you wish to have stronger compiler help with your CSS, you can use the elm-css library. The normal Elm style function doesn’t give you much help from the compiler given both arguments are strings. The elm-css library on the other hand ensures both types and argument order which really makes the most of the Elm compiler.
Coding in React
In React, you typically write in JavaScript. It’s a dynamic, interpreted language that is native in all browsers. Dynamic means you can change a variable that is a number to string or any type you want. Interpreted means you can write some code, put in the browser, and it’ll run. You do not need to compile yourself. The browser handles converting that to machine code that it can run quickly. You can debug the code, in the browser, using both logs and breakpoints which stop the code from running and allow you to step through each part line by line.
This also means that most styles of programming are supported. This includes Imperative, Object Oriented, and Functional. Imperative being many lines of code in a file that run from top to bottom in a procedural way. Object Oriented mean classes that encapsulate state, message passing, and a variety of design patterns. Functional meaning pure functions.
React allows both CSS and HTML to be written in JavaScript. This means that everything that makes up the visual elements on the screen can be put right next to each other, giving you a clearer picture of how each visual thing works. Sometimes.
The pros of a dynamic language are speed of development. You can quickly play with new ideas using only a little code. You don’t need any tools to make it work beyond a web browser. If you need a server, you can write the same language, JavaScript, to make Node do this for you.
Prop Types
The cons of a dynamic language is you have to run it to know if it works. While running can be fast, sometimes you have to click through the UI to trigger some part of the code, and that process isn’t that fast, or is tediously manual. Many tools can automate these kind of checks. For UI development in the browser, this is often verifying the components attributes (their inputs) and their events (change handlers).
<CrayButton label={datText} onGo={clickHandler} />
However, you won’t know if datText is actually a String, nor if clickHandler is a Function with proper scoping and no negative down stream effects till you actually test it. To help a bit with these problems, React has propTypes which has a bit of runtime type checking. You still have to run the code, and it only works in development mode, BUT it quickly aborts the code with correct errors vs. errors which may not be clear what went wrong.
CrayButton.propTypes = {
label: PropTypes.string,
onGo: PropTypes.func
}
Flow or TypeScript
Computers are much better than humans at finding, storing, and quickly accessing large amounts of numbers. For code, there are many different paths that could happen, and compilers are good at quickly verifying if your code is going to work or not in milliseconds to microseconds. One of the ways they do this is through types. You write in a different language entirely, then the compiler will convert it to JavaScript. Like the propTypes above, except the code won’t actually compile if it finds errors. Once you fix all the errors, it’ll then compile. The theory is in the little time it takes you to add types to the code, the compiler can find errors in microseconds to minutes. These milliseconds/minutes are supposed to be much shorter than the time it takes you to track down bugs.
Flow and TypeScript both offer really nice types with the ability to integrate with existing JavaScript and libraries. If a library was coding in JavaScript, many will offer TypeScript definitions which give the public API functions it exposes types. This allows TypeScript to offer type checking on it even though the library is JavaScript and has no types. For large codebases that already exist, including libraries, it’s much easier to create a definition file.
The create-react-app generator offers a TypeScript option, again abstracting away all the work to setup and maintain the compiler. The TypeScript/Flow flexibility, however, means that you have less guarantees that when your code actually compiles, it’ll work. Flow and TypeScript both compile to JavaScript, and have no runtime type checking.
Coding in Elm
In Elm, you write in the Elm language. It is functional and strongly typed. Functional means pure functions with no side effects. In fact, you cannot create side effects at all in Elm. The Elm framework handles all side effects for you. Everything from creating HTML to REST calls are simply pure functions. The types use Haskell style Hindly-Milner types. You put the function’s input(s) and output up top, and that’s all the compiler needs. This as opposed to TypeScript and ReasonML for example, where you put next to the variables at the end of the function. The function below is a simple add function, taking in 2 numbers, and returning whatever they are added together.
add : Int -> Int -> Int
add first second = first + second
That said, the compiler is pretty smart, so you can omit them and it’ll “know what you meant”.
add first second = first + second
In JavaScript, that’d be:
add = (first, second) => first + second
… sort of. Since all Elm functions are curried by default, a more accurate JavaScript representation would be:
add = first => second => first + second
Unlike Flow or TypeScript, Elm ensures when it compiles, you will not get any null pointer exceptions. There are only 2 ways to break this guarantee. The first is integrating with JavaScript through ports and you aren’t careful, or you are, but the JavaScript is just obnoxious. The second way is in development mode sending large amounts of text into the Debug.log function, using all of the browser’s memory.
As a functional language, there are no exceptions. This means all Error‘s are return values. More on error handling below.
In React, it’s not uncommon to see functions, classes, strings, numbers, modules, and images all in the same code base. In Elm, everything is a function or a type.
Side Effects in JavaScript
In JavaScript, you have control over some side effects. You can even create them yourself. This includes logging to the console, creating HTTP requests, reading from various storage locations such as files, listening for push requests on web sockets, various events from user interactions such as mouse clicks, and when the browser URL changes.
The ways these work varies from return values, callbacks, event handlers, to Promises. Some of these have built-in error handling and some do not.
To parse JSON from an outside source, it does a return value. If it fails, it’ll throw an exception you catch via try/catch.
result = JSON.parse('{"sup": "yo" }')
To listen to mouse events in React, it’s common to use inline callbacks:
<button onClick={() => console.log("Clicked, sucka!")}>Sup</button>
However, you can do it the event based way as well. We use a class method below so it can be cleaned up later.
theButton.addEventListener("click", this.clickHandler)
Many newer API’s offer Promises, and Promises have built-in try/catch. Here’s how to make an HTTP GET request using fetch which returns a Promise:
fetch(someURL)
.then(result => result.json())
.then(json => console.log("json is:", json))
.catch(console.log)
When unit testing, you’ll typically either mock the concretes using something like Sinon or Test Double to make the code more predictable. If you’re using functional style, you’ll pass in the module/class as one of the function parameters, and then a stub in your unit tests.
Side Effects in Elm
All side effects in Elm, with the exception of Debug.log in development, and JavaScript ports, are handled by Elm itself. You cannot create side effects in Elm. You merely create functions that return data. The Elm Architecture handles the actual side effects, allowing all of your code to be pure. We’ll talk more about how you get actual things done in the Elm Architecture section below. For now, just know that you can make the Elm Architecture create and handle side effects via one of the 3:
- Messages (think onClick + Redux Action Creator)
- Commands (think Redux Action Creator)
- Subscriptions (think Thunks or Sagas triggered from
window.onlocationchangeor web sockets)
Errors in React
Like Dart and Angular before it, React really has done some interesting things with Error handling. The first was error boundaries. Anyone who’s built UI’s knows that handling errors when drawing things is rough. Doing it in an async way is even harder since it’s hard to track where and when it may have occurred. Building errors into the components was a great first step in ensuring a single error didn’t bring down a whole application. Using throw in Fiber, their architecture that builds their own call stack, they can create Algebraic Effects. This means errors can be resumed safely from anywhere.
That said, errors in React are basically errors in JavaScript. They have tons of problems.
First, they aren’t pure. Pure functions have no side effects. Errors, even in the browser, cause side effects. They can put code currently, or later, into an unknown state. This could be from synchronous UI code, asynchronous WebWorkers, or some 3rd party library you’re not even sure is involved. If your web application has monitoring such as Catchpoint, you can get a text message at 3am because of an uncaught null pointer. Thus, they’re hard to predict and make your code flaky.
Second, JavaScript doesn’t really have good error handling facilities. They make it really easy to hurt yourself, the code, and the browser (or Node.js). Some languages languages such as Java have throwable. If a function has that, the compiler forces you to catch it. JavaScript has no such facilities, and is interpreted so you don’t know about errors until you run the code, see them, and get screwed over by them. Adding try/catch everywhere is not fun to write, nor read, and slows your code down. The asynchronous ones are a bit better in that catch on Promises only has to be written once, but with the popularity of async``await syntax, people forego even writing those. They let explosions happen there uncaught as well. The window.onerror is a strange method with various browser support intricacies that can sometimes affect how bad the crash is based on what you return. This is still great to have it, but it has the same thing in common with try``catch and the catch on a Promise: you can screw those up, and cause another error with no language/compiler support.
Third, the stack traces aren’t always accurate to what’s going on. They’ve greatly improved over the years since I abandoned Flash Player for JavaScript. Still, errors don’t always originate from the exact line of code that caused the error, or do but say something inaccurate to what’s actually causing the problem.
Errors in Elm
Elm doesn’t throw errors, that’s one of the draws of using it. Instead, if a function can fail, you return a Result. The compiler will ensure you’re handling it correctly. There are a few types that you can chain together like Promises such as Maybe and Result. If they fail, you handle the error in 1 place. These errors are return values and do not negatively affect the rest of your program.
If you’re in debug mode and send too much text, you can use all of the browser’s available memory and crash the program that way. Elm will not compile for production builds unless logs are removed.
If you’re using 3rd party JavaScript libraries on the page, or using ports with volatile JavaScript, they will also crash your program.
Redux in React
Redux is a framework inspired by Elm to help bring predictability to larger React applications. At some point when you outgrow Context, or just want the predictability that Functional Programming can bring, you reach for Redux. It ensures only 1 variable is in your entire application, and that 1 variable is all the data your application needs. You can use the Redux Dev tools to see your data change over time and clearly see the state changes, the order, and how they affect your UI. Since React components are pure functions that take in props and render DOM, Redux scales this concept for for the data.
Below is a crash course in Redux. You are welcome to skip it. I include it here for those who do not know Redux very well, nor why you even use it. Knowing how Redux works helps you understand how Elm works since they’re based on the same ideas.
Reducers
In Redux you have store; this is the main variable that stores your data. You get it via store.getState() and change it via store.dispatch({action}). The dispatch will call you reducers, or a function that takes in the state and the action. If you know the Array.reduce function, it’s the same thing. It’s assumed that your reducers do not mutate data, and simply return a copy of the store with whatever changes you need. Updating a person’s name for example would go like this:
const firstNameReducer = (person, action) => ({ ...person, firstName: action.firstName })
If I pass in firstNameReducer( { firstName: 'cow' }, { type: 'updateFirstName', firstName: 'Albus' } ), then it’ll return a brand new Object { firstName: 'Albus' }. This is important because it means the code returns immutable data, doesn’t mutate anything, and is easily testable. Thus, predictable. When you start building an application full of those reducer functions, your application becomes more predictable.
If you’re from an OOP background, you’re probably wondering why in the heck you can’t just go UserModel.getInstance().firstName = 'Albus' or even UserController.getInstance().setFirstName('Albus'). Or even just modifying on the variable in general. Remember, Redux uses pure functions. Pure functions do not mutate or “change” data. If you use immutable data, this ensures you’re following pure function rules. If you mutate things, then it’s not predictable who changes things, and where. If you use pure functions in Redux, the only mutation occurs in the store. You can predict which actions, in order, change your data and can visualize it using browser tools or simple logs. Yes, you can set a breakpoint in Java or JavaScript, and follow all the getter/setters for one code path, but not all. This is where you get “who’s changing my data, where, and when”. Redux has the same challenges, but it’s super clear “who” is doing it, and “how”. Since each change is immutable, there is no weird references going on.
Store
If data is immutable, then how do you change it? VERY carefully. Redux does this via reducer functions.
We know how to write pure functions that return immutable data, but nothing in the real world is immutable. Someone, somewhere has to hold the data we get back from the server, the changes the user makes on the UI, etc. That 1 var is the Store.
const store = createStore(firstNameReducer, { firstName: '???', lastName: 'Warden' })
This store holds your data. Notice we’ve put our reducer function for it as the 1st parameter.
You get it out via getState:
const person = store.getState() // { firstName: '???', lastName: 'Warden' }
To change the data, we call the dispatch method and pass in an Object:
store.dispatch({ type: 'updateFirstName', firstName: 'Jesse' })
Now when we get our data out, it’ll be changed:
const updated = store.getState() // { firstName: 'Jesse', lastName: 'Warden' }
Action Creator
The Object you pass as the 1st and only parameter to dispatch is called the “Action”. However, purist Functional people get mad creating random Objects, so they create a pure function. Those are suddenly called “Action Creators”:
firstNameAction = firstName => ({ type: 'updateFirstName', firstName })
An Action Creator is a function that return an Object. It’s assumed that Object, at a minimum, has a type property. You’ll use that type in your reducer function to know what data you want to change.
Many Types
As your application grows, you’ll probably need to change many aspects of your data model. For our person, we want to change the last name as well. So we create another reducer for changing the last name, but using a pure function. This means a copy of the data is returned vs. mutating it:
const lastNameReducer = (person, action) => ({ ...person, lastName: action.lastName })
To trigger it, we need another action creator for updating lastName:
lastNameAction = lastName => ({ type: 'updateLastName', lastName })
When we created our store above, we put the firstNameReducer with our store to handle all dispatches. Now we need both reducers, and each needs to run based on the type of Action Creator. Let’s create a new one that uses a switch statement.
const personReducer = (person, action) => {
switch(action.type) {
case 'updateFirstName':
return firstNameReducer(person, action)
case 'updateLastName':
return lastNameReducer(person, action)
}
}
In a unit test, if we call personReducer with {}, { type: 'updateFirstName', firstName: 'Joe' } then we’ll get back { firstName: 'Joe' }. If we call it with {}, { type: 'updateLastName', lastName: 'Hall' }, then we’ll get back { lastName: 'Hall' }.
To call it in your application, or even in a unit test, you’d go store.dispatch(lastNameAction('Warden')) to update the lastName to “Warden”.
As that switch statement grows, there are other ways to scale it, and improve it overall. That’s the gist of Redux.
Why Are We Using This?
When building applications in React, you need some sort of state and need it placed somewhere. For some applications, most of it can reside in the URL in the form of GET variables. For others, it’s simply a global variable. For others, if you load a list from the server, you’ll store that in a components props or even state for class components, or a closure for Hooks. Some keep it in sessions.
Eventually, though, some applications need 2 things that the above doesn’t provide: the ability to share the same data between multiple components, and the ability to update that data from any place you need. Sometimes an OOP Mediator design pattern, higher order components, or even just component composition works. You do this to avoid passing props down many component levels, or the components themselves via higher order components. You have a parent component who’s sole job is to handle communication between a bunch of children components.
As things grow, rather than utilize a Model View Controller style architecture, React provided Context. They describe it as a “tree”, from the idea that a component made of many components forms a tree, much like html within html forms a tree of nodes. When many in the tree, or even sibling components need to share the same data, and communicate up and down, performance aside, Context is the go to.
If, however, you want something deterministic without any state that can be mutated or “changed”, you use Redux. While people will often use Redux for the same reasons they use Context, the whole point is to ensure predictable code. If you only have 1 variable, you can ensure that the rest of your code is pure functions. If the rest of your code is pure functions, they’re predictable and easier to test. That means the bugs are typically type related, race conditions, CSS, or null pointers in your component code or 3rd party libraries. If your component code is intentionally dumb, small, and using Hooks in function components over classes, then you’re significantly reducing the places bugs can hide.
In short, all your code uses const and pure functions as much as possible, and all the hard work is in Redux reducers with as little code as possible in your React components and Hooks. Redux hides from you the only var (or let, heh) in the entire application. Now your application has only 1 variable which is your Model. All data is there, easy to find, and as your application grows, your Model just gets more branches on the Object. Given how JavaScript works, creating immutable versions of just pieces of tree means components see only the part they care about, and in turn the reducers only change the part they care about.
Redux Thunk
The above code is all synchronous. JavaScript applications are often asynchronous. The web browser is asynchronous because the code that renders the screen is also the code that loads image.
Redux’ default store doesn’t have the ability to deal with Promises or any type of callback async style. The redux-thunk library was created to make that as simple as possible.
An example would be modelling ajax calls. For example, the UI below shows the 3 possible states: loading, error, success:

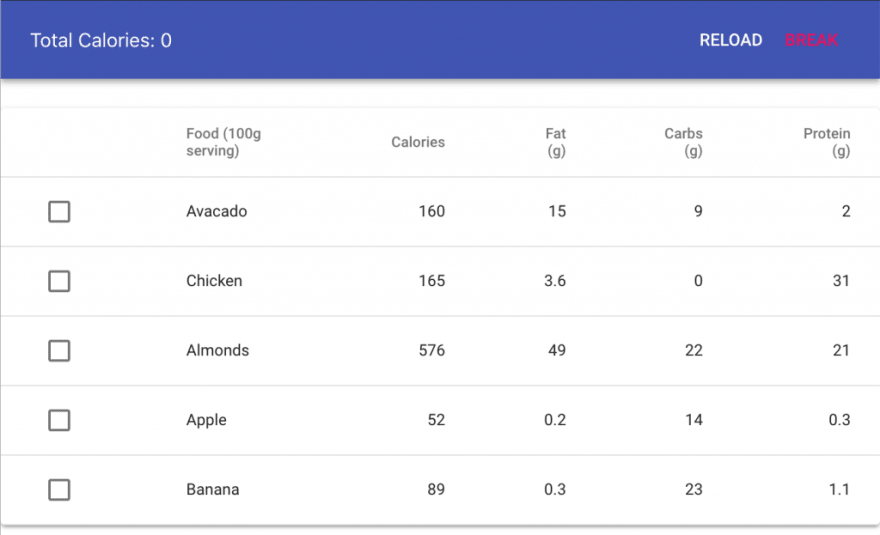
Putting that in a Redux Store would look something like:
{
loadingState: {
loading: true,
isError: false,
error: undefined,
data: undefined
}
}
Or using Algebraic Data Types:
{
loadingState: LoadingFoods()
}
You dispatch an Action Creator before the AJAX call to put it in a loading state, when it fails you dispatch an error Action Creator, or when it succeeds, you dispatch a success Action Creator. Using a Promise, it looks like this:
dispatch(loadingFoods())
fetch('/foods')
.then(result => result.json())
.then(foods => dispatch(foodsLoaded(foods))
.catch(error => dispatch(foodsFailed(error))
Connecting Redux to React
Now that you have Redux and Thunks for async calls, you now wire up to React, usually using the connect library. A pattern emerges where you’ll have “dumb” components who take data, render it, or are just simple UI elements like , etc. You then have “connected” components that know about Redux. Their sole job is to provide an interface for a React component to get its data from the current state, and when the component has events, those trigger Action Creators. This requires 2 functions called mapStateToProps and mapDispatchToProps and put you those 2 in the connect call with your Component, and it smooshes them together into a “ConnectedComponent”. If you have a Cow component, and connect it to Redux, it’ll be a ConnectedCow.
An example React component that would show 3 screens needs 1 piece of data to know what screen to show, and 1 click handler when the user clicks “reload”.
<Screen loading={true} reloadClicked={reloadClicked} />
To get data, you create a function called mapStateToProps. The longer version is “Yo, I’ll give you the current Redux state in the store; you can either use it as is, even if it’s a gigantic Object, or you can snag off the pieces you want. Whatever you return to me, I’ll set as the props to your component for you. Also, don’t worry, I’ll get called every time the data you care about changes.” Since the whole point of using React is to keep your DOM in sync with your data, this is a perfect match.
Given our example Object above of modelling the loading state, it’d be:
const mapStateToProps = state => state.loadingState
Second, we need a mapDispatchToProps. This function takes any events that come out of our React component, and makes it fire the dispatch action creator we want. If we want to click a
const Screen = props => (
<div>
<div>Loading: {props.loading}</div>
<button onClick={props.reloadClicked}>Reload</div>
</div>
)
So we’ll create that reload function for it like so:
const mapDispatchToProps = dispatch =>
({
reloadClicked: () => dispatch(reloadActionCreator())
})
Last part is to smoosh them together via connect:
const ConnectedScreen = connect(
mapStateToProps,
mapDispatchToProps
)(Screen)
Elm Architecture
Below is a crash course in the Elm Architecture. It can be a LOT to take in, even if you’ve had extensive Redux experience. Don’t fret, and read the Elm Guide multiple times, it’ll click.
Elm comes built-in with the Elm Architecture. There is no way to NOT use the Elm architecture, unless you’re playing around with Elm code in the elm repl. If you’re familiar with Redux, then you’ll understand the Elm architecture.
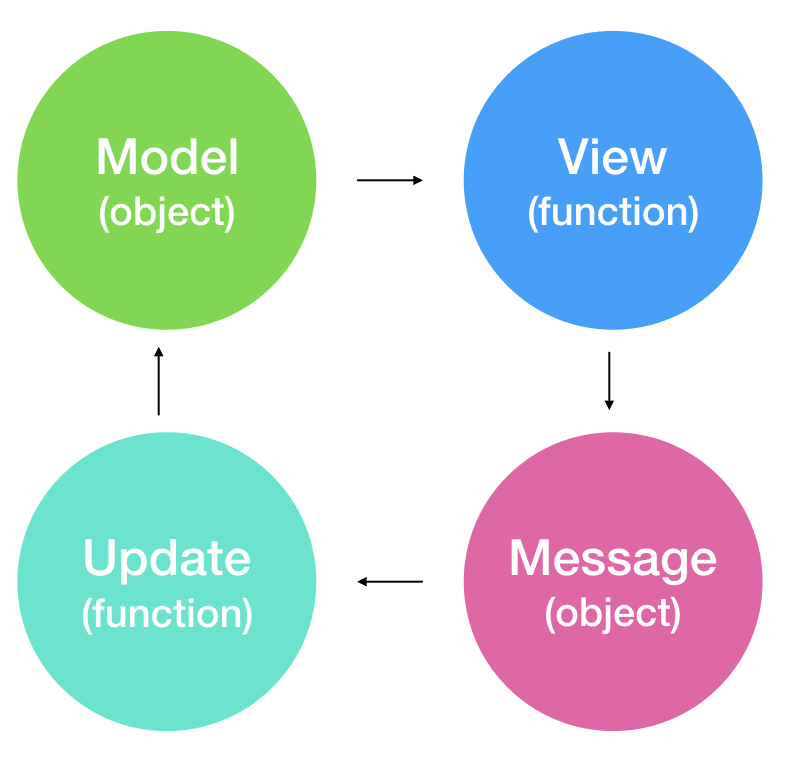
Similar to Redux, you have a model that is your data. In Redux, it’s some Object that grows over time. In Elm, it’s a Record that grows over time. The difference is Elm has types to ensure the Model’s values are changed correctly.
type alias Model =
{ firstName : String
, lastName : String }
initialModel =
{ firstName = "???"
, lastName = "Warden" }
Think of type alias as a JavaScript class. You can instantiate new type alias things. To change the Model, you send Messages. They’re just types too. They’re like Redux Actions. Instead of { type: 'UpdateFirstName' }, it’s UpdateFirstName. You don’t need Action Creators like you do in JavaScript since the compiler will ensure you create them correctly.
type Msg
= UpdateFirstName String
| UpdateLastName String
You handle those Messages in the update function just like you handle Actions in Redux reducer functions. Elm will not compile unless you handle all of them. In JavaScript you can intentionally ignore Actions you don’t understand by using default at the bottom of the switch statement. You can also forget as your application grows and you miss one and have no compiler to yell at you. The code below ignores an action with the type “updateLastName”.
const personReducer = (person, action) => {
switch(action.type) {
case 'updateFirstName':
return firstNameReducer(person, action)
default:
return person
}
}
Not so in Elm. This only handles UpdateFirstName. Elm won’t compile until you implement it correctly.
update message model =
case message of
UpdateFirstName firstName ->
{ model | firstName = firstName }
Check out this beastly compiler error:
Missing Patterns
Line 26, Column 5
This `case` does not have branches for all possibilities:
26|> case msg of
27|> UpdateFirstName firstName ->
28|> { model | firstName = firstName }
Missing possibilities include:
UpdateLastName _
I would have to crash if I saw one of those. Add branches for them!
Hint: If you want to write the code for each branch later, use `Debug.todo` as a
placeholder. Read <https://elm-lang.org/0.19.0/missing-patterns> for more
guidance on this workflow.
Fixing our code to handle both Messages by now including the UpdateLastName:
update message model =
case message of
UpdateFirstName firstName ->
{ model | firstName = firstName }
UpdateLastName lastname ->
{ model | lastName = lastName }
The view function gets the Model as the first parameter. There’s no need to setup components to be aware of it like in React via the connect function for Redux. They are just functions and can take the Model as a parameter, or parts of it. It’s up to you. In Redux, you’d use mapStateToProps. The connect library will then spread all the data you need on your React component props. In Elm, you just get the whole model. You’re welcome to snip off the pieces you want, though.
view model =
div [] [ text "First Name: " ++ model.firstName ]
When you’re ready to make HTTP calls, your update function is returned to send back 2 values instead of just the model. In Redux, you get the model and action, but only have to return the model. Below is the Redux reducer for the loading state:
const loadingState = (state, action) => {
switch(action.type) {
case 'loading':
return {...state, loading: true}
case 'error':
case 'success':
return {...state, loading: false}
}
}
You’ll then have code elsewhere that dispatches the Action, then makes the fetch call, then dispatches either an Error or Success Action.
In Elm, you can’t make HTTP calls on your own since those are side effects. Instead, you use a Command. You don’t typically create Commands on your own. Rather, things that cause side effects like HTTP calls create them for you, you just return them in your update function so Elm knows what to do.
update model =
LoadData ->
( { model | state = "loading" }
, Http.get
{ url = "/companies"
, expect = Http.expectString CompaniesHTTPResult
}
)
...
That Http.get returns a Command. Elm internally will make the call for you. Whenever the HTTP result is successful or fails, your update will be called again some time later with your CompaniesHTTPResult message. Think of the error and success in the JavaScript Redux reducer above as one CompaniesHTTPResult below. The result parameter lets you know if it worked or not.
update model =
CompaniesHTTPResult result ->
-- it's either Ok or Err
This concept of just having functions either return data or Commands seems weird at first. In JavaScript you’re used to “making it do”. Things like “make this GET request and wait for it”, or “Read this data from Application Cache”. In Elm, you can do those things, but it’s all through returning Commands in the update function. Elm will handle the nitty gritty of making the actual XHR call, or reading from the browser’s storage. You’ll typically have a Message to “kick it off”. This means there is no need for a Thunk. No need for a mapping function of events to dispatches. Your UI will trigger messages, and inside the update function, you can then return Commands to do side effect things.
Bugs in React
Bugs in React are usually because of JavaScript. The language is fast to develop in and run with no compile step. This speed comes at the cost of having little to no correctness guarantees when you run. Maybe it’ll work, maybe it won’t. That is a adrenaline rush for some people, myself included.
However, some errors aren’t even reported. They’re “swallowed”. Meaning, your application doesn’t work like you expect, but you don’t get an exception. No stack trace, no error, no red in the console, no error breakpoint triggered… just “what… the….”. These are the worst because at least Exceptions give you a possible hint and path to follow. At least returned Errors from more functional code can also give a hint and a path.
Below, I’ve listed some common ones not always caught by ESLint plugins via misspellings, lack of types, null pointers, missing case statements, and logic errors.
Swallowed Errors via Misspellings
In JavaScript, you can name Object properties just about anything you want. The problem is when it’s accidental and onClick becomes onClck. JavaScript doesn’t know you meant onClick, and if you pass React event handlers undefined, they’ll assume you want nothing to happen. One mispelling, 2 miscommunications. Worse? It’s silent; you won’t get any runtime exception. You click a button and nothing happens.

ESLint plugins can only help so much. Some code can only be known to work together if it’s run, and some variables aren’t known to each other unless you had types and a compiler.
In Elm, every single variable’s spelling must match a known type, or it won’t compile. With the exception of magic strings, this completely solves swallowed errors via misspellings.
Null Pointers Because of the Lack of Types
You can use Algebraic Data Types in JavaScript. This allows you to return a Result from an operation that could fail, either success or failure. It’s called an Either in some Functional languages, but in JavaScript, the default one is a Promise. However, Promises don’t come with the popular matching syntax where as something like Result from Folktale or true-myth do.
Downside? You have to memorize the variable names, specifically how you destructure. Without types, you can get subtle bugs that can inadvertently get swallowed. In Redux, since all of the code is synchronous, it’s easier and more fun to use Result as opposed to Promise because the code is synchronous, can be chained like Promise, and has matching syntax. In our reducer below, if the ajax call to load the accounts works, great, we parse it and return a success. If not, we return a failure. The UI can match on this to know what to draw.
export const accounts = (state=AccountsNotLoaded(), action) => {
...
case 'fetchAccountsResult':
return action.fetchResult.matchWith({
Ok: ({ value }) => {
...
AccountsLoadSuccess(...)
},
Error: ({ error }) =>
AccountsLoadFailed(error)
})
The bug is both Ok and Error have a value to destructure. That means AccountsLoadFailed(error) is actually AccountsLoadFailed(undefined). This ends up on the React UI and causes a null pointer:

That’s because the error is actually undefined and when you go undefined.anything it blows up. Types in Elm won’t compile if you misspell things or spell the wrong thing because you haven’t learned the API yet.
In Elm, you have types and a compiler to help ensure that never happens.
FetchAccountsResult result ->
case result of
Ok accountJSONs ->
...
{ model | accountState = AccountsLoadSuccess accounts }
Err datError ->
{ model | accountState = AccountsLoadFailed (httpErrorToString datError) }
In the Elm code above, the AccountsLoadFailed is defined as AccountsLoadFailed String. If you were to pass the error itself like AccountsLoadFailed datError, the compiler wouldn’t compile your code, saying you’re passing an Error when you should be passing a String. Using types and a compiler, Elm ensures you’ll never get null pointers at runtime. You still have to do the work to build an error UI and format the errors for viewing.
Missing Case Statements
Missing case statements can bite you in 2 places in React. The first is in your reducers. If you miss a case statement, you get no indication you did beyond your application doesn’t work correctly. Below is a reducer that handles all 4 things you can do in the example app; loading the data, parsing the response, and pressing the next/back buttons.
accounts = (state=AccountsNotLoaded(), action) => {
switch(action.type) {
case 'fetchAccounts':
...
case 'fetchAccountsResult':
...
case 'previousAccountPage':
...
case 'nextAccountPage':
...
default:
...
}
}
What happens when you forget one? We’ll comment out the 'fetchAccountsResult' one.

You’ll now see the loading UI forever. You won’t know if this is because the server is slow or your code is broken. If you’re using TypeScript in strict-mode, and you convert your case strings to actual type‘s, TypeScript won’t compile because you haven’t handled every potential case.
The 2nd place is forgetting the default. Again, TypeScript can help here.
The 3rd place, and is more dealing with Algebraic Data Types, is the matching syntax. For example, if our server is down, but we forget to render that part of the UI in the React component:
const AccountStates = ({ accountsState }) =>
accountsState.matchWith({
AccountsNotLoaded: () => (<div>Accounts not fetched yet.</div>),
AccountsLoading: () => (<div>Loading accounts...</div>),
AccountsLoadNothing: () => (<div>No accounts.</div>),
// AccountsLoadFailed: ({ value }) => (<div>{value.message}</div>),
AccountsLoadSuccess: ({ accountView }) => (...)
})
Notice the above code has AccountsLoadFailed commented out. That means, if the server fails, you get the following null pointer error:

In Elm, every case statement is basically the matching syntax. With the compiler, this ensures you will never miss a case. Below, I have a Result when the Account REST call returns. It either worked or it didn’t:
FetchAccountsResult result ->
case result of
Ok json ->
...
Err error ->
...
However, if I forget the Err, then I’ll get a compiler error:

Elm ensures you never forget a case statement, including default.
Logic Error: Off By 1
Even if all your code doesn’t have null pointer exceptions, and you handle all possible case statements, you can still have logic errors. It’s where your code doesn’t explode, but doesn’t work like you want it to. Both the React app and Elm app can have this same bug.
When you click the next and back buttons in the application, they increment what page you are in. If we can’t increment anymore, we do nothing and stay on the same page. There is a bug in this function, specifically the accountView.currentPage < accountView.pageSize. We’ll come back to this below. We’ve implemented this in the Redux reducer:
const nextPage = accountView => {
if(accountView.currentPage < accountView.pageSize) {
return {...accountView, currentPage: accountView.currentPage + 1}
}
return accountView
}
Using that number as the index to the Array, you can determine which page you should show. We use this awesome chunk function from Lodash that takes your Array and automatically creates pages from it. So if you’re array is [1, 2, 3, 4, 5, 6, 7] and you want 3 pages, you go chunk(3, yourArray) and it’ll give you an Array that looks like [ [1, 2, 3], [4, 5, 6], [7] ]. If your current page is 0, then you’ll draw a list of [1, 2, 3]. If you’re current page is 2, then you’ll draw a list of [7].
const getCurrentPage = pageSize => currentPage => accounts => {
const chunked = chunk(pageSize)(accounts)
if(isNil(chunked[currentPage])) {
return []
}
return chunked[currentPage]
}
When you run the application, it allow works, and you can click the next button to cycle through the pages. However, a logic error arises at the end. Once there, the screen goes blank, the numbers show 11 of 10, and you can no longer click the back button. There are no null pointers caught by React, and the console doesn’t show any issues. Wat.

The first bug as explained above is how you increment the pages:
if(accountView.currentPage < accountView.pageSize) {
That means you can increment the current page, which starts at 0, to 10 since there are 10 pages and pageSize is 10. The problem is, Array’s are 0 based, and 0 counts as a number. So now you have the ability to next to 11 pages. That logically should not be allowed, but your code allows it. The function the way it is written, being typed with TypeScript, or even Elm would still result in the same logic error of being off by 1 number.
We fix it by adding a 1 to our page size:
if(accountView.currentPage < accountView.pageSize + 1) {
Now the current page will never exceed 9 which is the last item in the Array of 10 items.
Errors in Elm
There are no null pointers in Elm; that’s one of the main draws to using it. When you compile, you will NOT get runtime errors.
Sort of. The marketing isn’t as clear as it could be on this. Let’s break down the 3 types of errors you can and cannot get in Elm. You won’t get null pointers like you do in JavaScript. There are 2 exceptions to this. The first is when you are in development mode and log out enough JSON that you cause the browser to run out of memory eventually causing the page to crash. The second is when you are integrating with JavaScript through ports and the JavaScript crashes the application by either throwing an error or disobeying the port’s rules.
The third errors are built into Elm as an Algebraic Data Type: Error. They’re just like Folktale/true-myth’s Error type and are encouraged to be used, returning them from functions that can fail. The lack of data such as undefined which typically causes errors in JavaScript is called a Maybe in Elm. It’s actually embraced in Elm as a type, just like Error to prevent null pointers from ever occurring.
We’ll focus on the Maybe, Error, and logic errors below since ports and safely working with JavaScript is beyond this article’s scope. You can read more about ports in the official guide.
Null Pointers
Most null pointers you get in JavaScript result from trying to dot on an undefined like this.someMethod() in a class or:
const value = getSomething()
const result = value.something
If the value returned is undefined, then instead of value.something, what actually happens is undefined.something and that causes a null pointer.
Null pointers also happen because you misspell things. Either the code fails immediately, or later with some subtle bug because the name you placed was on an Object property name instead of a variable or instance, and you don’t find out till later.
None of those bugs can’t happen in Elm. You’ll never have scope problems because Elm doesn’t have any. Classes hide state, and Elm is a functional language that doesn’t allow you to create any state. No classes, no this. You can store things in the Model and it feels like a variable (let or var), but any changes you make are immutable. There are no classes to hide mutations.
The second reason the dots never fail in Elm is because of the type system. If you can guarantee that all Objects (called Records in Elm) match the types exactly, then you know exactly if you can dot or something or not. Here is a Person type alias; think of it like a class you can instantiate:
type alias Person =
{ firstName : String
, age : Int }
Now you can create a Person by simply going:
myPerson = Person "Jesse" 40
The compiler will check this for you and allow it. If you did this:
myPerson = Person 'Jesse' 40
It wouldn’t compile because single quotes are used for characters. If you did this:
myPerson = Person "Jesse" 40.2
It wouldn’t work because 40.2 is a Float, not an Int. If you did this:
myPerson = Person "Jesse"
msg = log "firstName: " myPerson.firstName
It wouldn’t work because myPerson is a partial application; it’s a function waiting for you to give it an Int so it can make a person. Since it’s a function, it has no firstName property so the program won’t compile. Technically it’s type is Int -> Person.
If you log out the name, it works fine:
myPerson = Person "Jesse" 40
msg = log "firstName: " myPerson.firstName
But if you misspell firstName to have a missing “i”:
myPerson = Person "Jesse" 40
msg = log "firstName: " myPerson.frstName
Elm won’t compile and will suggest maybe you meant firstName.
The third place you can get null pointers in JavaScript is when your code is good, and the data it creates is good and predictable, but then you get JSON from some other place like a web service. When the JSON changes, or they send you HTML instead of JSON, suddenly your functions are acting weird because they don’t know what HTML is, or the Objects they thought they were getting in JSON have slightly different names or a slightly different structure.
In Elm, all JSON into Elm is parsed using strict decoders. This ensures that no untyped values that could cause a null pointer get into Elm from HTTP calls and JavaScript. If JavaScript passes you a Person like the above, it’ll either work, or fail to parse. There is no middle ground here.
Maybe
Since there is no way to create an undefined or null in Elm, then how do you deal with things that don’t return anything? In cases where you might not get a value back, Elm provides a Maybe type. It allows you get a value wrapped in something called a Just or when you don’t have a value, it’s a Nothing. This forces your functions to suddenly handle the case when they get nothing back. Our JavaScript function above for getting the current page, you saw that it handled if it got undefined back, then it defaulted to an empty Array. This is a great practice and acts like a Maybe. However, not all functions in JavaScript handle this case and all you have to do is miss one, and POW, null pointer.
Since Elm has types, it knows what a Maybe is. This means if you mess up, misspell it, or only handle the Just, it won’t compile until you fix it. For example, if you get an item from an Array but the Array is empty, you’ll get a Nothing back. If the Array is full of things, and you ask for the first item, you’ll get a Just back. There is no way to know until runtime, though, so Elm ensures you handle both:
getFirstPersonsName =
case Array.get 0 peopleList of
Just item ->
item.firstName
Nothing ->
"Nobody is in the list."
If you leave out the Nothing, Elm won’t compile your code, letting you know you need to handle the Nothing case. This is true for all functions, and ensures your entire program cannot be broken by 1 missing value.
Error Type
There are functions that can work or fail. These are different than Maybe‘s. In the case of loading data from a back-end web service, it’ll either work or it won’t. Sure, you could get back an empty Array which could count as a Nothing, but there are a litany of things that could go wrong instead. All you want to know is “Did it work? Let me know and give me the value, otherwise give the error so I can show it.”
Unlike exceptions in JavaScript, however, there is no throw in Elm, nor any try/catch. There are also no error boundaries like in React. If a function can fail, you return an Ok or an Err. If you need to handle that in your UI, you do a case statement to draw a different UI for each piece:
case httpResult of
Ok data ->
div [] [ text ("Yay, data: " ++ data) ]
Err reason ->
div [] [ text ("Bummer, an error: " ++ (httpErrorToString reason))]
Logic Errors
Null pointers are fixed by types and Maybe‘s. Errors are handled by the Error type. Encoding/decoding is handled by the JSON Decoder/Encoder modules to ensure only typed data gets in. If you’re going to use Port’s, you already accepted you’re in dangerous territory. So no more bugs right?
Sadly, Elm too can still have logic errors. Types CAN help here, but they’re not a panacea. Either you don’t know the data type your need, or haven’t written the appropriate unit test, or didn’t know you needed to.
Our Elm code can have the same bug as the React app where it increments the next page too high:
nextPage accountView =
if accountView.currentPage < accountView.pageSize then
{ accountView | currentPage = accountView.currentPage + 1}
else
accountView
Again, you need to remember Array’s are 0 based, so have to ensure currentPage can only be 0 through 9. You fix that by accountView.currentPage < accountView.pageSize + 1.
Before you start writing unit and functional tests, though, remember you have a pretty good type system in Elm. Can you create a type that prevents this bug from happening? Making an impossible state, impossible to happen? Richard Feldman talks about these types of data types in his talk. There are a lot of these types of data types that, once learned, ensure you’ll never get into an impossible state, and don’t even need unit tests for it.
Conclusions
React, JavaScript, Redux, and Thunks
React uses JavaScript, Redux, and Thunks. JavaScript is a dynamic language that, even with various tooling, you still have to run it to see if it works. The speed of development is great for fleshing out ideas and quickly iterating. The cost of that speed is null pointer exceptions, swallowed errors, many are just because of misspellings. This is compounded by the most libraries installed via npm being also written in JavaScript.
React helps with a few of these challenges by optionally providing PropTypes which allow better error messages at runtime. It also allows global error handling via error boundaries with fallback UI’s in the case of problems. By encouraging pure functions via propTypes in function components, and Algebraic Effects via Hooks, they’ve abstracted many of the side effects away from you which is often the causes of many bugs. It still runs on JavaScript so can only help so much. The create-react-app project generator and build system now offers TypeScript to help here.
Redux helps ensure your application only has 1 variable as your data model. You only change it via pure functions which means all data is immutable. This means the data that runs your application is predictable and removes a ton of possibilities for bugs that arise from side effects, race conditions, and mutable state.
Redux is just for synchronous changes, though. Redux Thunks handle all the asynchronous changes you need to make in reasonable to learn Promise style.
Elm
Elm is a typed, functional language that compiles to JavaScript, a framework, has a compiler, and a repl. The elevator pitch for Elm is once your application compiles, you won’t get null pointer errors. Although I still recommend Test Driven Development / Red Green Refactor, using the type system, you can refactor with confidence. Simply changing your Model makes the compiler find errors everywhere. Once you fix those and it compiles again… it works with confidence. It’s amazing. At first you feel you code Elm 5% of your time, and battle with the compiler 95%. In actuality, that 95% is the best part because once you’re done, you KNOW YOUR’RE DONE. As opposed to JS where you go “Let’s run it and see…”.
The types also help you model your application to ensure it can avoid some logic errors. You can model states that prevent the application from getting in a bad state or an impossible one.
Given that the language is functional, you never have scope problems or other mutable state changing things on you. There are no classes, nor variables, and every function is pure. All changes are immutable and this makes writing unit tests for the hairier parts of your application easier.
Elm does not allow you to create side effects. This further purifies your code making all functions taking inputs and producing outputs. While you can write pure functions in JavaScript, at some point, some function has to do the actual side-effect. The Elm framework handles that.
Like Redux, the Elm framework ensures you only have 1 model, and all changes to it are immutable, and thus predictable. Unlike Redux Thunks, the Elm framework handles both sync and asynchronous changes as normal.
Like React, Elm views are pure functions, taking in data, and returning DOM. Like React, Elm also doesn’t care how your do your CSS, although using the elm-css library can help leverage the type system for it. Like React, Elm doesn’t care how your organize your code and files.
Like JavaScript, Elm also can have logic errors. Unit tests are still valuable. Property/fuzz tests are still valuable. End to end tests are still valuable. Like JavaScript, Elm can also have race conditions. Elm solves a host of problems JavaScript does not, but you’ll still have to do work. While you may enjoy your job coding Elm more, it’s still a job requiring work.
Finally, Elm is an ongoing project. JavaScript has had explosive growth in terms of API’s implemented in the browser the past decade. Elm purifies them. This means not all API’s are yet implemented in Elm. As new ones come out, someone has to build those Elm equivalents. Thus, if you’re doing any Elm app, you’ll probably still be writing JavaScript. JavaScript doesn’t go away. How you write that JavaScript, however, is probably much more functional and predictable. Much to the chagrin of many Elm purists, npm/yarn doesn’t go away. But a ton of problems do!
#reactjs #redux #javascript
