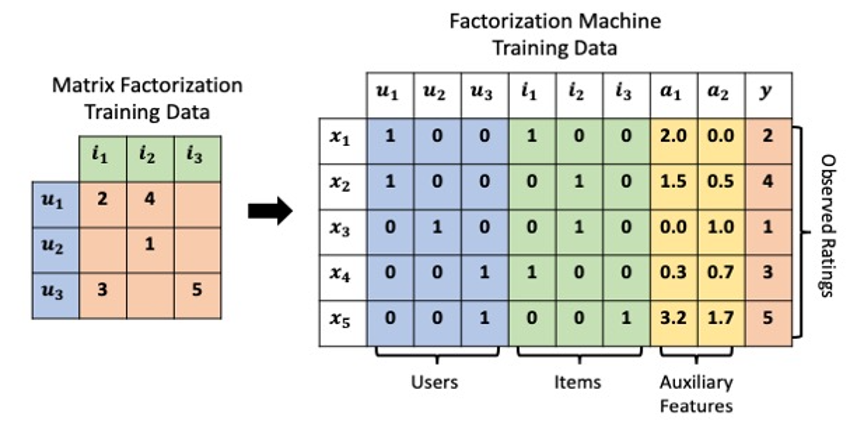
Introduction
In this article, we’ll introduce Factorization Machines (FM) as a flexible and powerful modeling framework for collaborative filtering recommendation. We’ll then describe how specialized loss functions that directly optimize item rank-order make it possible to apply FM models to implicit feedback data. We’ll finish up by demonstrating these points with a real-world implicit feedback data set using a new open-source FM modeling library. Onwards!
Recommender Systems
As the digital economy continues to expand in size and increase in sophistication, the role of recommender systems to provide personalized, relevant content to each individual user is more important than ever. E-commerce sites with ever-larger product catalogs can present individualized store fronts to millions of users simultaneously. Digital content providers can help users navigate more books, articles, songs, movies, etc. than could be consumed in a lifetime to find the small subset best matching each user’s specific interests and tastes. For example, Netflix reported in 2015 that its recommender system influenced roughly 80% of streaming hours on the site and further estimated the value of the system at over $1B annually.[1]
The two broad high-level approaches to recommender systems are Content-Based Filtering (CBF) and Collaborative Filtering (CF). CBF models represent users and items as vectors of attributes or features (e.g. user age, state, income, activity level; item department, category, genre, price). In contrast, CF methods rely only on past user behavior: the model analyzes co-occurrence patterns to determine user and/or item similarities and attempts to infer a user’s preferences over unseen items using only the user’s recorded interactions. CF-based approaches have the advantages of being domain-free (i.e. no specific business knowledge or feature engineering required) as well as generally more accurate and more scalable than CBF models.[2]
Matrix Factorization
Many of the most popular and most successful CF approaches are based on Matrix Factorization (MF), with development accelerating rapidly due to the 2006–2009 Netflix Prize in which the winning entry made heavy use of MF techniques, including the now-popular SVD++ algorithm.[3] MF models attempt to learn low-dimensional representations, or embeddings, of users and items in a shared latent factor space. In essence, the observed sparse user-item interaction matrix is “factorized” into the approximate product of two low-rank matrices which contain user and item embeddings. After these latent factors are learned, user/item similarity can be computed and unobserved preferences inferred by comparing the user/item latent factor representations.
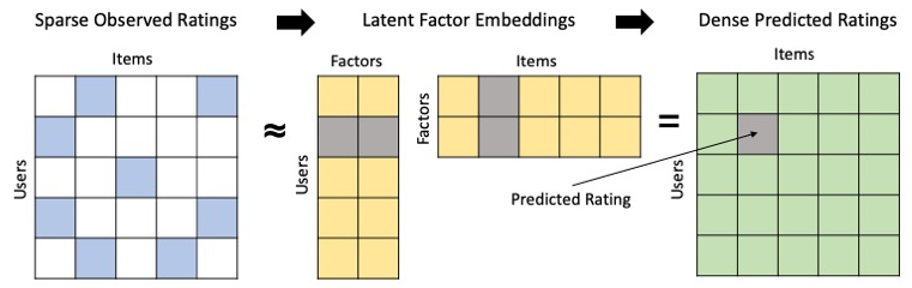
Image by Author
Many popular MF algorithms learn these user/item latent factors by minimizing the squared error between observed and predicted ratings, where predicted ratings are computed as the inner product of the relevant user and item latent factors. Some model specifications further include global user/item biases and/or regularization terms to prevent overfitting. A common MF loss function can be expressed as:
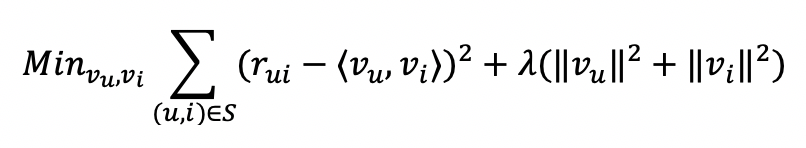
#machine-learning #recommendation-system #factorization-machine #learning-to-rank #collaborative-filtering