Overview
So, I have a working machine learning (ML) model that I want to move to the edge.
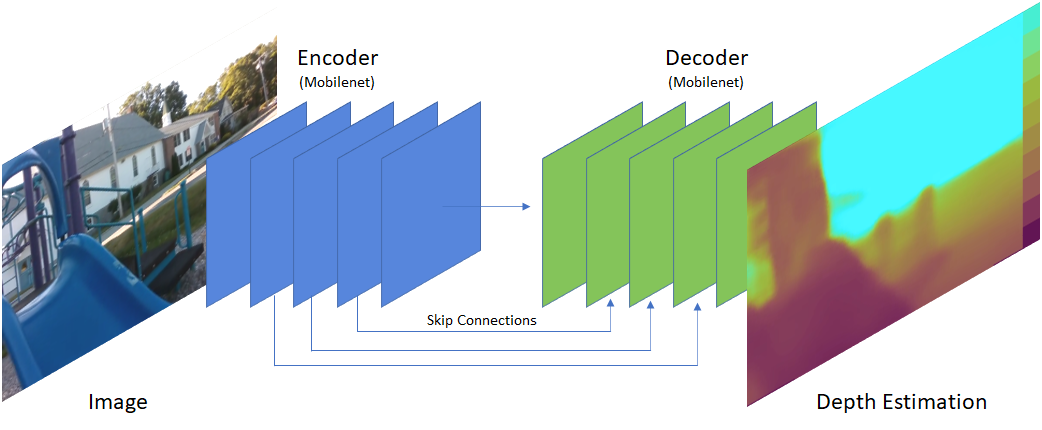
By the way, my ML model processes images for depth estimation to provide perception capabilities for an autonomous robot. The machine learning model used is based on Fast Depth from MIT. This is a U-Net architecture focused on speed. It uses a MobileNet encoder and a matching decoder with skip connections.
(Image by Author)
It was developed using Keras (PyTorch at first) on Python with a CUDA backend.
By moving to the edge, I mean I needed this running on a small CPU/GPU (Qualcomm 820) running an embedded Linux where the GPU (Adreno 530) can only be accessed via OpenCL (i.e., not CUDA.)
Caveat — If you’re on iOS or Android you’re already relatively home free. This article is for getting machine learning on the GPU on embedded Linux using OpenCL.
Travels to Find a Workable Solution
This is going to be easy. Hah! Turns out once you leave CUDA behind you’re in the wilderness…
There are really two broad approaches to deploying a model at the edge.
- Try and duplicate your development environment on the edge and let it run there. If this is possible, it is always a good first step, if just to convince yourself how slow it’s performing. I explored this world to the extent possible, though in my case I didn’t even have a full Linux on my device so I couldn’t even support Python.
- Find an inferencing framework that can run your code in a more high performance, low resources context. This requires more work on your part, especially as you are going to have to take your C++ coding skills out for a spin. This is where we are going to explore.
#machine-learning #edge-computing