These are the lecture notes for FAU’s YouTube Lecture “Deep Learning”. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
Navigation
Previous Lecture** / Watch this Video / Top Level / Next Lecture**Welcome back to deep learning! Today I want to show you one alternative solution to solve this vanishing gradient problem in recurrent neural networks.

Famous words by Jürgen Schmidhuber.
You already noticed long temporal contexts are a problem. Therefore, we will talk about long short-term memory units (LSTMs). They have been introduced by a Hochreiter in Schmidhuber and they were published in 1997.

Two famous authors in the world of machine learning. Image under [CC BY 4.0]from the [Deep Learning Lecture]
They were designed to solve this vanishing gradient problem in the long term dependencies. The main idea is that you introduce gates that control writing and accessing the memory in additional states.
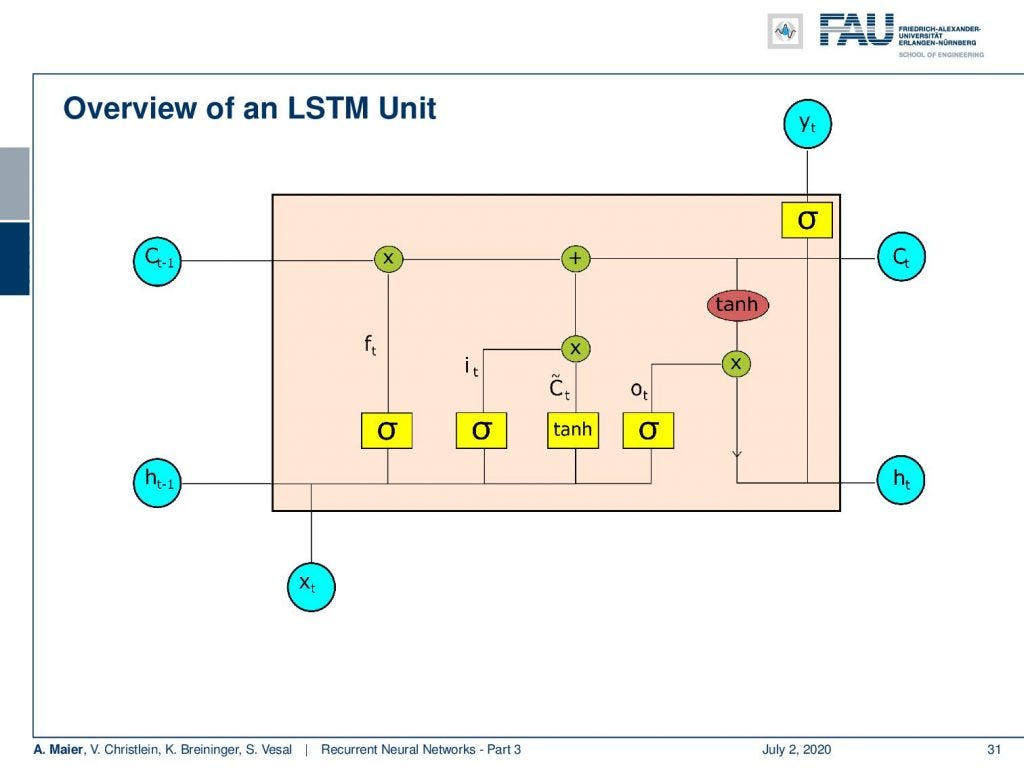
Overview on the LSTM cell.
So, let’s have a look into the LSTM unit. You see here, one main feature is that we now have essentially two things that could be considered as a hidden state: We have the cell state C and we have the hidden state h. Again, we have some input x. Then we have quite a few of activation functions. We then combine them and in the end, we produce some output y. This unit is much more complex than what you’ve seen previously in the simple RNNs.

#machine-learning #deep-learning #fau-lecture-notes #artificial-intelligence #data-science #deep learning
