If Any of you want to know about the Basic of Machine Learning . I have Written a post on this topic in a very very Simple Language with real World Example, and with easy explanation about all the term and classification .After reading my Post you can answer anyone about the Basic of Machine Learning.
Here is the Link below :-
A Little Introduction About the Project:-
These Informations are Gathered from Different Sources:-
Spam Email , become a big trouble over the internet. Spam is waste of time, storage space and communication bandwidth. The problem of spam e-mail has been increasing for years. In recent statistics, 40% of all emails are spam which about 15.4 billion email per day and that cost internet users about $355 million per year. Knowledge engineering and machine learning are the two general approaches used in e-mail filtering. In knowledge engineering approach a set of rules has to be specified according to which emails are categorized as spam or ham.
Machine learning approach is more efficient than knowledge engineering approach; it does not require specifying any rules . Instead, a set of training samples, these samples is a set of pre classified e-mail messages. A specific algorithm is then used to learn the classification rules from these e-mail messages. Machine learning approach has been widely studied and there are lots of algorithms can be used in e-mail filtering. They include Naive Bayes, support vector machines, Neural Networks, K-nearest neighbour, Rough sets and the artificial immune system.
Why We Using Naive Bayes as an Algorithms for Filtering the Email:-
Naive Bayes work on dependent events and the probability of an event occurring in the future that can be detected from the previous occurring of the same event . This technique can be used to classify spam e-mails, words probabilities play the main rule here. If some words occur often in spam but not in ham, then this incoming e-mail is probably spam. Naive Bayes classifier technique has become a very popular method in mail filtering Email. Every word has certain probability of occurring in spam or ham email in its database. If the total of words probabilities exceeds a certain limit, the filter will mark the e-mail to either category. Here, only two categories are necessary: spam or ham.
Here are Some Calculation Which help you to Understand how it work.
The statistic we are mostly interested for a token T is its spamminess (spam rating), calculated as follows:-
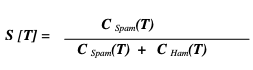
Where CSpam(T) and CHam(T) are the number of spam or ham messages containing token T, respectively. To calculate the possibility for a message M with tokens {T1,……,TN}, one needs to combine the individual token’s spamminess to evaluate the overall message spamminess. A simple way to make classifications is to calculate the product of individual token’s spamminess and compare it with the product of individual token’s hamminess
(H [M] = Π ( 1- S [T ]))
The message is considered spam if the overall spamminess product S[M] is larger than the hamminess product H[M].
All the Machine Learning Algorithms works on two stages:-
- Training Stage.
- Testing Stage.
So In the Training Stage Naive Bayes create a Lookup table in which they store all the possibility of probability which we are going to use in the Algorithm for predicting the result.
And In the testing phase let Suppose you have given a test point to the algorithm to predict the result , they fetch the values from the lookup table in which they store all the possibility of probability and use that value to predict the result .
Now Our Main Work on Email Spam Classifier Start:-
First of all I want to make you clear that we have a folder name “e-mail” in which we have about 5172 file and each file is one of the e-mail and on each e-mail they mentioned that particular e-mail is spam or ham.
Our first target is to make a list of all the word which are used in that 5172 Email. For this we have some step:
- Load the “e-mail” folder in Jupiter Notebook With the help of OS in which each file is one Email.
import os
folder='Desktop/e-mail/'
files=os.listdir(folder)
emails=[folder+file for file in files]
- Open each file with the help of f=open(e-mail)
- In this f=open (e-mail) if you have give one file in f=open() it open that file to read.
- Read the File.
- f.read() it read all the content of that email file and store in string format.
- Split the file with the spaces (“ “)and append in the list.
words=[]
for e-mail in e-mails:
f=open(e-mail,encoding='latin-1')
blob=f.read()
words+=blob.split(" ")
In this time we have a list of Words in which we have all the words stored which are used in 5172 Email. But we don’t know which word occur how much time , for finding this we are going to import counter from collection ,this counter will give you the result that which word occur how much time
from collections import Counter
And pass the word list in counter it form a dictionary which show
which word occur how much time
#naive-bayes #machine-learning #email #deep learning