The history behind Russian disinformation is a dense and continuously evolving subject. The world’s best research hasn’t seemed to hit the mainstream yet, which made this an excellent opportunity to see if I could use some open source tooling to surface new analytical evidence.
The premiere dataset available for researchers on this subject has a lot of history to it. Researchers from Clemson University, Darren Linvill, and Patrick Warren, published a dataset containing 2,973,371 tweets from a network of 2,848 fake accounts belonging to the IRA. Darren and Patrick have added an extraordinary amount of depth to this subject over the years to help monitor and tackle foreign malign influence on social media platforms.
“At heart, if security agencies and political actors throughout the democratic world are to detect and deter such action in the future, it is crucial that we understand the pattern of such strategic social media activity, and develop tools to resist it when it emerges.”
— Darren Linvill, Patrick Warren, Brandon Boatwright, and Will Grant
The big dataset was published by the Clemson researchers and open-sourced through FiveThirtyEight on GitHub. You can read more about the history behind the dataset and the schema information on the git repository here.
Open source repositories
In this blog post, I’ll show you how to use Apache Pinot and Superset to analyze 3 million tweets by the Internet Research Agency (IRA) open-sourced by FiveThirtyEight.
To get up and running with the example project I discuss in this blog post, and please head over to my open source repository with the bootstrap recipe.
https://github.com/kbastani/russian-troll-analysis
Analyzing the dataset
To do efficient exploratory analysis on top of millions of tweets in real-time requires a fast datastore designed to do precisely that. Apache Pinot provides the backend query capabilities that enabled me to do this research. Taking it to the next level, I needed a tool to create charts and dashboards on top of Pinot, for which Apache Superset played a perfect role.
My analysis started with some basic assumptions based on my prior research on the subject. First, I wanted to take a step back from the existing beliefs that the trolls employed strategies to influence the desired election outcome. This assumption is infamous and may have led to complex investigations politicized by both the news media and congress members after 2016.
So, I thought to myself, what if election interference using social media isn’t technically possible?
Exploring the data
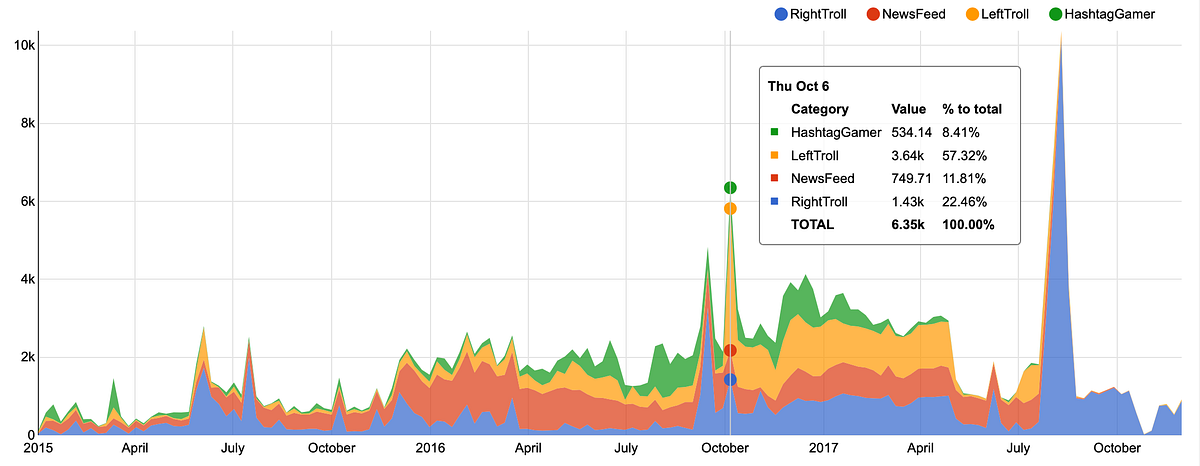
After loading the raw data into Apache Pinot, the first step was to verify the analysis that was initially provided by FiveThirtyEight in 2018. The first chart they showed was a simple activity view that attempted to show possible election interference in 2016.
#data #politics #nlp #data-science #machine-learning