Python Data Structures: A Comprehensive Guide
Master Python data structures with this comprehensive guide. Learn the fundamentals of lists, tuples, dictionaries, sets, and queues, and how to use them to solve real-world problems. With hands-on exercises and code examples, you'll be able to write more efficient and elegant Python code.
Data structures are a way of organizing and storing data so that they can be accessed and worked with efficiently. They define the relationship between the data, and the operations that can be performed on the data. There are many various kinds of data structures defined that make it easier for the data scientists and the computer engineers, alike to concentrate on the main picture of solving larger problems rather than getting lost in the details of data description and access.
In this tutorial, you’ll learn about the various Python data structures and see how they are implemented:
In DataCamp’s free Intro to Python for Data Science course, you can learn more about using Python specifically in the data science context. The course gives an introduction to the basic concepts of Python. With it, you’ll discover methods, functions, and the NumPy package.
Abstract Data Type and Data Structures
As you read in the introduction, data structures help you to focus on the bigger picture rather than getting lost in the details. This is known as data abstraction.
Now, data structures are actually an implementation of Abstract Data Types or ADT. This implementation requires a physical view of data using some collection of programming constructs and basic data types.
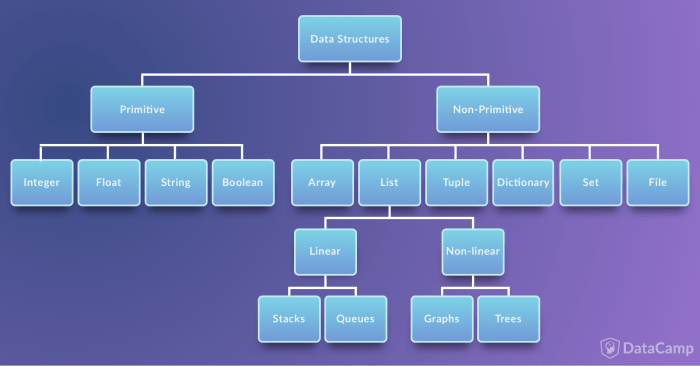
Generally, data structures can be divided into two categories in computer science: primitive and non-primitive data structures. The former are the simplest forms of representing data, whereas the latter are more advanced: they contain the primitive data structures within more complex data structures for special purposes.
Primitive Data Structures
These are the most primitive or the basic data structures. They are the building blocks for data manipulation and contain pure, simple values of a data. Python has four primitive variable types:
- Integers
- Float
- Strings
- Boolean
In the next sections, you’ll learn more about them!
Integers
You can use an integer represent numeric data, and more specifically, whole numbers from negative infinity to infinity, like 4, 5, or -1.
Float
“Float” stands for ‘floating point number’. You can use it for rational numbers, usually ending with a decimal figure, such as 1.11 or 3.14.
Take a look at the following DataCamp Light Chunk and try out some of the integer and float operations!
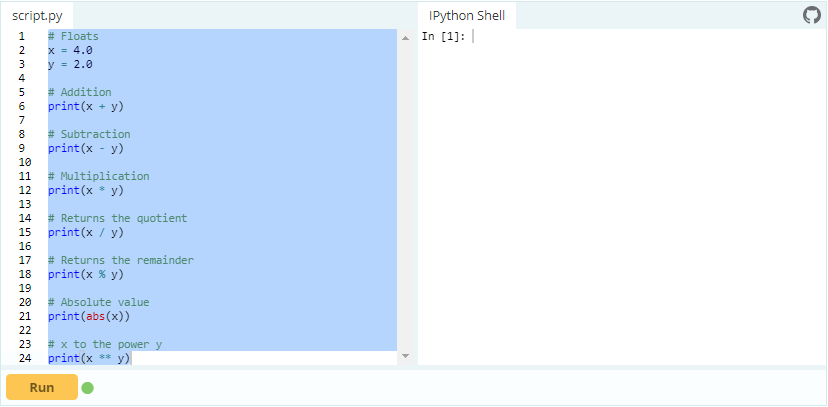
Note that in Python, you do not have to explicitly state the type of the variable or your data. That is because it is a dynamically typed language. Dynamically typed languages are the languages where the type of data an object can store is mutable.
String
Strings are collections of alphabets, words or other characters. In Python, you can create strings by enclosing a sequence of characters within a pair of single or double quotes. For example: 'cake', "cookie", etc.
You can also apply the + operations on two or more strings to concatenate them, just like in the example below:
x = 'Cake'
y = 'Cookie'
x + ' & ' + y
'Cake & Cookie'
Here are some other basic operations that you can perform with strings; For example, you can use * to repeat a string a certain number of times:
# Repeat x * 2
'CakeCake'
You can also slice strings, which means that you select parts of strings:
# Range Slicing
z1 = x[2:]
print(z1)
# Slicing
z2 = y[0] + y[1]
print(z2)
ke
Co
Note that strings can also be alpha-numeric characters, but that the + operation still is used to concatenate strings.
x = '4'
y = '2'
x + y
'42'
Python has many built-in methods or helper functions to manipulate strings. Replacing a substring, capitalising certain words in a paragraph, finding the position of a string within another string are some common string manipulations. Check out some of these:
- Capitalize strings
str.capitalize('cookie')
'Cookie'
- Retrieve the length of a string in characters. Note that the spaces also count towards the final result:
str1 = "Cake 4 U"
str2 = "404"
len(str1)
8
- Check whether a string consists of only digits
str1.isdigit()
False
str2.isdigit()
True
- Replace parts of strings with other strings
str1.replace('4 U', str2)
'Cake 404'
- Find substrings in other strings; Returns the lowest index or position within the string at which the substring is found:
str1 = 'cookie'
str2 = 'cook'
str1.find(str2)
0
- The substring
'cook'is found at the start of'cookie'. As a result, you refer to the position within'cookie'at which you find that substring. In this case,0is returned because you start counting positions from 0!
str1 = 'I got you a cookie'
str2 = 'cook'
str1.find(str2)
12
- Similarly, the substring
'cook'is found at position 12 within'I got you a cookie'. Remember that you start counting from 0 and that spaces count towards the positions!
You can find an exhaustive list of string methods in Python here.
Boolean
This built-in data type that can take up the values: True and False, which often makes them interchangeable with the integers 1 and 0. Booleans are useful in conditional and comparison expressions, just like in the following examples:
x = 4
y = 2
x == y
False
x > y
True
x = 4 y = 2
z = (x==y) # Comparison expression (Evaluates to false)
if z: # Conditional on truth/false value of 'z'
print("Cookie")
else: print("No Cookie")
No Cookie
Data Type Conversion
Sometimes, you will find yourself working on someone else’s code and you’ll need to convert an integer to a float or vice versa, for example. Or maybe you find out that you have been using an integer when what you really need is a float. In such cases, you can convert the data type of variables!
To check the type of an object in Python, use the built-in type() function, just like in the lines of code below:
i = 4.0
type(i)
float
When you change the type of an entity from one data type to another, this is called “typecasting”. There can be two kinds of data conversions possible: implicit termed as coercion and explicit, often referred to as casting.
Implicit Data Type Conversion
This is an automatic data conversion and the compiler handles this for you. Take a look at the following examples:
# A float
x = 4.0
# An integer
y = 2
# Divide `x` by `y`
z = x/y
# Check the type of `z`
type(z)
float
In the example above, you did not have to explicitly change the data type of y to perform float value division. The compiler did this for you implicitly.
That’s easy!
Explicit Data Type Conversion
This type of data type conversion is user defined, which means you have to explicitly inform the compiler to change the data type of certain entities. Consider the code chunk below to fully understand this:
x = 2
y = "The Godfather: Part "
fav_movie = y + x
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
1 x = 2
2 y = "The Godfather: Part "
----> 3 fav_movie = y + x
TypeError: Can't convert 'int' object to str implicitly
The above example gave you an error because the compiler does not understand that you are trying to perform concatenation or addition, because of the mixed data types. You have an integer and a string that you’re trying to add together.
There’s an obvious mismatch.
To solve this, you’ll first need to convert the int to a string to then be able to perform concatenation.
Note that it might not always be possible to convert a data type to another. Some built-in data conversion functions that you can use here are: int(), float(), and str().
x = 2
y = "The Godfather: Part "
fav_movie = (y) + str(x)
print(fav_movie)
The Godfather: Part 2
Non-Primitive Data Structures
Non-primitive types are the sophisticated members of the data structure family. They don’t just store a value, but rather a collection of values in various formats.
In the traditional computer science world, the non-primitive data structures are divided into:
Arrays
Lists
Files
Array
First off, arrays in Python are a compact way of collecting basic data types, all the entries in an array must be of the same data type. However, arrays are not all that popular in Python, unlike the other programming languages such as C++ or Java.
In general, when people talk of arrays in Python, they are actually referring to lists. However, there is a fundamental difference between them and you will see this in a bit. For Python, arrays can be seen as a more efficient way of storing a certain kind of list. This type of list has elements of the same data type, though.
In Python, arrays are supported by the array module and need to be imported before you start inititalizing and using them. The elements stored in an array are constrained in their data type. The data type is specififed during the array creation and specified using a type code, which is a single character like the I you see in the example below:
import array
as arr a = arr.array("I",[3,6,9])
type(a)
array.array
Python Array documentation page provides more information about the various type codes available and the functionalities provided by the array module.
List
Lists in Python are used to store collection of heterogeneous items. These are mutable, which means that you can change their content without changing their identity. You can recognize lists by their square brackets [ and ] that hold elements, separated by a comma ,. Lists are built into Python: you do not need to invoke them separately.
x = [] # Empty list
type(x)
list
x1 = [1,2,3]
type(x1)
list
x2 = list([1,'apple',3])
type(x2)
list
print(x2[1])
apple
x2[1] = 'orange'
print(x2)
[1, 'orange', 3]
Note: like you have seen in the above example with x1, lists can also hold homogeneous items and hence satisfying the storage functionality of an array. This is fine unless you want to apply some specific operations to this collection.
Python provides many methods to manipulate and work with lists. Adding new items to a list, removing some items from a list, sorting or reversing a list are common list manipulations. Let’s see some of them in action:
- Add
11to thelist_numlist withappend(). By default, this number will be added to the end of the list.
list_num = [1,2,45,6,7,2,90,23,435]
list_char = ['c','o','o','k','i','e']
list_num.append(11) # Add 11 to the list, by default adds to the last position
print(list_num)
[1, 2, 45, 6, 7, 2, 90, 23, 435, 11]
- Use
insert()to insert11at index or position 0 in thelist_numlist
list_num.insert(0, 11)
print(list_num)
[11, 1, 2, 45, 6, 7, 2, 90, 23, 435, 11]
- Remove the first occurence of
'o'fromlist_charwith the help ofremove()
list_char.remove('o')
print(list_char)
['c', 'o', 'k', 'i', 'e']
- Remove the item at index
-2fromlist_char
list_char.pop(-2) # Removes the item at the specified position
print(list_char)
['c', 'o', 'k', 'e']
list_num.sort() # In-place sorting
print(list_num)
[1, 2, 2, 6, 7, 11, 11, 23, 45, 90, 435]
list.reverse(list_num)
print(list_num)
[435, 90, 45, 23, 11, 11, 7, 6, 2, 2, 1]
If you want to know more about Python lists, you can easily walk through the 18 Most Common Python List Questions tutorial!
Arrays versus Lists
Now that you have seen lists in Python, you maybe wondering why you need arrays at all. The reason is that they are fundamentally different in terms of the operations one can perform on them. With arrays, you can perform an operations on all its item individually easily, which may not be the case with lists. Here is an illustration:
array_char = array.array("u",["c","a","t","s"])
array_char.tostring()
print(array_char)
array('u', 'cats')
You were able to apply tostring() function of the array_char because Python is aware that all the items in an array are of the same data type and hence the operation behaves the same way on each element. Thus, arrays can be very useful when dealing with a large collection of homogeneous data types. Since Python does not have to remember the data type details of each element individually; for some uses arrays may be faster and uses less memory when compared to lists.
It is also worthwhile to mention the NumPy array while we are on the topic of arrays. NumPy arrays are very heavily used in the data science world to work with multidimensional arrays. They are more efficient than the array module and Python lists in general. Reading and writing elements in a NumPy array is faster, and they support “vectorized” operations such as elementwise addition. Also, NumPy arrays work efficiently with large sparse datasets. To learn more, check out DataCamp’s Python Numpy Array Tutorial.
Here is some code to get you started on NumPy Array:
import numpy as np
arr_a = np.array([3, 6, 9])
arr_b = arr_a/3 # Performing vectorized (element-wise) operations
print(arr_b)
[ 1. 2. 3.]
arr_ones = np.ones(4)
print(arr_ones)
[ 1. 1. 1. 1.]
multi_arr_ones = np.ones((3,4)) # Creating 2D array with 3 rows and 4 columns print(multi_arr_ones)
[[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]
[ 1. 1. 1. 1.]]
Traditionally, the list data structure can be further categorised into linear and non-linear data structures. Stacks and Queues are called “linear data structures”, whereas Graphs and Treesare “non-linear data structures”. These structures and their concepts can be relatively complex but are used extensively due to their resemblance to real world models. You will get a glimpse of these topics in this tutorial.
Note: in a linear data structure, the data items are organized sequentially or, in other words, linearly. The data items are traversed serially one after another and all the data items in a linear data structure can be traversed during a single run. However, in non-linear data structures, the data items are not organized sequentially. That means the elements could be connected to more than one element to reflect a special relationship among these items. All the data items in a non-linear data structure may not be traversed during a single run.
Stacks
A stack is a container of objects that are inserted and removed according to the Last-In-First-Out (LIFO) concept. Think of a scenario where at a dinner party where there is a stack of plates, plates are always added or removed from the top of the pile. In computer science, this concept is used for evaluating expressions and syntax parsing, scheduling algortihms/routines, etc.
Stacks can be implemented using lists in Python. When you add elements to a stack, it is known as a push operation, whereas when you remove or delete an element it is called a pop operation. Note that you have actually have a pop() method at your disposal when you’re working with stacks in Python:
# Bottom -> 1 -> 2 -> 3 -> 4 -> 5 (Top)
stack = [1,2,3,4,5]
stack.append(6) # Bottom -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 (Top)
print(stack)
[1, 2, 3, 4, 5, 6]
stack.pop() # Bottom -> 1 -> 2 -> 3 -> 4 -> 5 (Top)
stack.pop() # Bottom -> 1 -> 2 -> 3 -> 4 (Top)
print(stack)
[1, 2, 3, 4]
Queue
A queue is a container of objects that are inserted and removed according to the First-In-First-Out (FIFO) principle. An excellent example of a queue in the real world is the line at a ticket counter where people are catered according to their arrival sequence and hence the person who arrives first is also the first to leave. Queues can be of many different kinds.
Lists are not efficient to implement a queue, because append() and pop() from the end of a list is not fast and incur a memory movement cost. Also, insertion at the end and deletion from the beginning of a list is not so fast since it requires a shift in the element positions.
Graphs
A graph in mathematics and computer science are networks consisting of nodes, also called vertices which may or may not be connected to each other. The lines or the path that connects two nodes is called an edge. If the edge has a particular direction of flow, then it is a directed graph, with the direction edge being called an arc. Else if no directions are specified, the graph is called an undirected graph.
This may sound all very theoretical and can get rather complex when you dig deeper. However, graphs are an important concept specially in Data Science and are often used to model real life problems. Social networks, molecular studies in chemistry and biology, maps, recommender system all rely on graph and graph theory principles.
Here, you will find a simple graph implementation using a Python Dictionary to help you get started:
graph = { "a" : ["c", "d"],
"b" : ["d", "e"],
"c" : ["a", "e"],
"d" : ["a", "b"],
"e" : ["b", "c"]
}
def define_edges(graph):
edges = []
for vertices in graph:
for neighbour in graph[vertices]:
edges.append((vertices, neighbour))
return edges
print(define_edges(graph))
[('a', 'c'), ('a', 'd'), ('b', 'd'), ('b', 'e'), ('c', 'a'), ('c', 'e'), ('e', 'b'), ('e', 'c'), ('d', 'a'), ('d', 'b')]
You can do some cool stuff with graphs such as trying to find of there exists a path between two nodes, or finding the shortest path between two nodes, determining cycles in the graph.
The famous “travelling salesman problem” is, in fact, about finding the shortest possible route that visits every node exactly once and returns to the starting point. Sometimes the nodes or arcs of a graph have been assigned weights or costs, you can think of this as assigning difficulty level to walk and you are interested in finding the cheapest or the easiest path.
Trees
A tree in the real world is a living being with its roots in the ground and the branches that hold the leaves, fruit out in the open. The branches of the tree spread out in a somewhat organized way. In computer science, trees are used to describe how data is sometimes organized, except that the root is on the top and the branches, leaves follow, spreading towards the bottom and the tree is drawn inverted compared to the real tree.
To introduce a little more notation, the root is always at the top of the tree. Keeping the tree metaphor, the other nodes that follow are called the branches with the final node in each branch being called leaves. You can imagine each branch as being a smaller tree in itself. The root is often called the parent and the nodes that it refers to below it called its children. The nodes with the same parent are called siblings. Do you see why this is also called a family tree?
Trees help in defining real world scenarios and are used everywhere from the gaming world to designing XML parsers and also the PDF design principle is based on trees. In data science, ‘Decision Tree based Learning’ actually forms a large area of research. Numerous famous methods exist like bagging, boosting use the tree model to generate a predictive model. Games like chess build a huge tree with all possible moves to analyse and apply heuristics to decide on an optimal move.
You can implement a tree structure using and combining the various data structures you have seen so far in this tutorial. However, for the sake of simplicity, this topic will be tackled in another post.
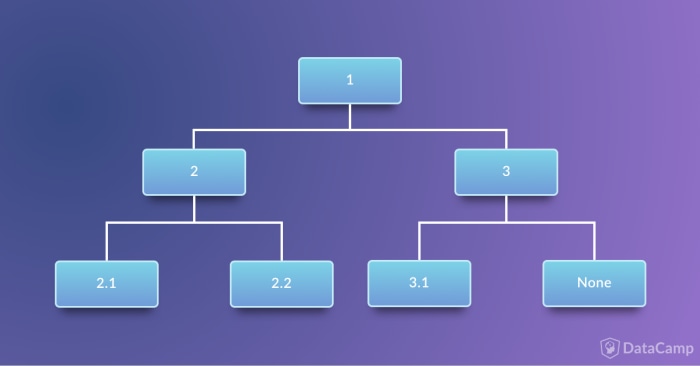
class Tree:
def __init__(self, info, left=None, right=None):
self.info = info
self.left = left
self.right = right
def __str__(self):
return (str(self.info) + ', Left child: ' + str(self.left) + ', Right child: ' + str(self.right))
tree = Tree(1, Tree(2, 2.1, 2.2), Tree(3, 3.1))
print(tree)
1, Left child: 2, Left child: 2.1, Right child: 2.2, Right child: 3, Left child: 3.1, Right child: None
You have learnt about arrays and also seen the list data structure. However, Python provides many different flavours of data collection mechanisms, and although they might not be included in traditional data structure topics in computer science, they are worth knowing specially with regards to Python programming language:
- Tuples
- Dictionary
- Sets
Tuples
Tuples are another standard sequence data type. The difference between tuples and list is that tuples are immutable, which means once defined you cannot delete, add or edit any values inside it. This might be useful in situations where you might to pass the control to someone else but you do not want them to manipulate data in your collection, but rather maybe just see them or perform operations separately in a copy of the data.
Let’s see how tuples are implemented:
x_tuple = 1,2,3,4,5
y_tuple = ('c','a','k','e')
x_tuple[0]
1
y_tuple[3]
x_tuple[0] = 0 # Cannot change values inside a tuple
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
1 y_tuple[3]
----> 2 x_tuple[0] = 0 # Cannot change values inside a tuple
TypeError: 'tuple' object does not support item assignment
Dictionary
Dictionaries are exactly what you need if you want to implement something similar to a telephone book. None of the data structures that you have seen before are suitable for a telephone book.
This is when a dictionary can come in handy. Dictionaries are made up of key-value pairs. key is used to identify the item and the value holds as the name suggests, the value of the item.
x_dict = {'Edward':1, 'Jorge':2, 'Prem':3, 'Joe':4}
del x_dict['Joe']
x_dict
{'Edward': 1, 'Jorge': 2, 'Prem': 3}
x_dict['Edward'] # Prints the value stored with the key 'Edward'.
1
You can apply many other inbuilt functionalies on dictionaries:
len(x_dict)
3
x_dict.keys()
dict_keys(['Prem', 'Edward', 'Jorge'])
x_dict.values()
dict_values([3, 1, 2])
Sets
Sets are a collection of distinct (unique) objects. These are useful to create lists that only hold unique values in the dataset. It is an unordered collection but a mutable one, this is very helpful when going through a huge dataset.
x_set = set('CAKE&COKE')
y_set = set('COOKIE')
print(x_set)
{'A', '&', 'O', 'E', 'C', 'K'}
print(y_set) # Single unique 'o'
{'I', 'O', 'E', 'C', 'K'}
print(x - y) # All the elements in x_set but not in y_set
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
----> 1 print(x - y) # All the elements in x_set but not in y_set
NameError: name 'x' is not defined
print(x_set|y_set) # Unique elements in x_set or y_set or both
{'C', '&', 'E', 'A', 'O', 'K', 'I'}
print(x_set & y_set) # Elements in both x_set and y_set
{'O', 'E', 'K', 'C'}
Files
Files are traditionally a part of data structures. And although big data is commonplace in the data science industry, a programming language without the capability to store and retrieve previously stored information would hardly be useful. You still have to make use of the all the data sitting in files across databases and you will learn how to do this.
The syntax to read and write files in Python is similar to other programming languages but a lot easier to handle. Here are some of the basic functions that will help you to work with files using Python:
open()to open files in your system, the filename is the name of the file to be opened;read()to read entire files;readline()to read one line at a time;write()to write a string to a file, and return the number of characters written; Andclose()to close the file.
# File modes (2nd argument): 'r'(read), 'w'(write), 'a'(appending), 'r+'(both reading and writing)
f = open('file_name', 'w')
# Reads entire file
f.read()
# Reads one line at a time
f.readline()
# Writes the string to the file, returning the number of char written
f.write('Add this line.')
f.close()
The second argument in the open() function is the file mode. It allows you to specify whether you want to read (r), write (w), append (a) or both read and write (r+).
To learn more about file handling in Python, be sure to check out this page.
You Did It!
You reached the end of this tutorial! This gets you one topic closer to your dreams of conquering the data science world.
If you’re interested, DataCamp’s two-part Python Data Science Toolbox dives deeper into functions, iterators, lists, etc.
Thank for reading!
#python #datastructures #algorithms
