Introduction
As we begin working with data, we (generally always) observe that there are few errors in the data, like missing values, outliers, no proper formatting, etc. In nutshell, we call them inconsistency. This consistency, more or less, skews the data and hamper the Machine learning algorithms to predict correctly.
In this article, we will try to see how outliers affect the accuracy of machine learning algorithm and how scaling would have helped or affected our learning. We have used 2 non-parametric algorithms, k-NN and Decision Trees for the simplicity of the objective.
About Data set
We will be using Hepatitis C Virus (HCV) for Egyptian patients Data Set obtained from UCI Machine Learning Repository. Which can be obtained from :
http://archive.ics.uci.edu/ml/datasets/Hepatitis+C+Virus+%28HCV%29+for+Egyptian+patients
This data consists of Egyptian patients who underwent treatment dosages for HCV about 18 months. There are total of 1385 patients with 29 attributes. These attributes ranges from their age, counts of WBC, RBC, plat etc.
Working with the Data
First and foremost thing is to load the data and required libraries in python.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
pd.set_option('display.max_columns', None) # This will help yoy view all the columns rather than the sample when using dataframe.head()
df = pd.read_csv('HCV-Egy-Data.csv')
df.head()
Once we are through the data set it almost advised to check if there are any inconsistencies which we mentioned earlier. To do so we will use python’s info function.
df.info()
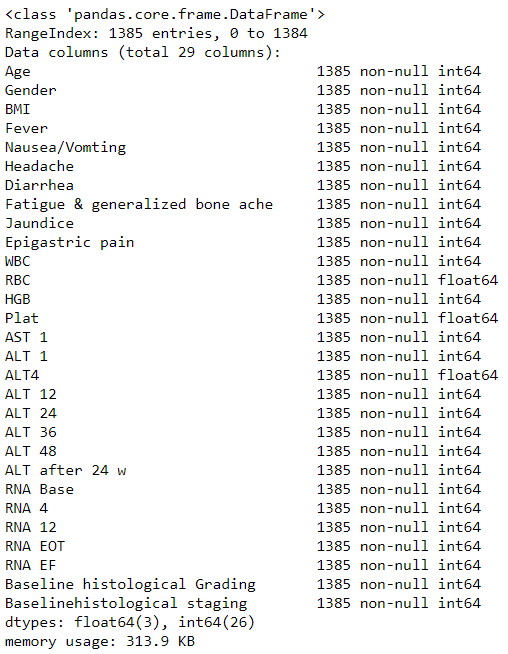
df.info() results
Here we observe that we do not have any missing values, and since the data is a numeric data, we can be certain that all the attribute values are numeric i.e, either int64 or float64 type. Additionally, there are no null values, thus we can use our data to model.
We also want to see if there are any outliers, one quick check in pandas library is using _describe() _function. It provides us with the desired statistics like minimum- maximum values, quantiles, Standard deviation, etc.
#outliers #decision-tree #machine-learning #knn #classification #deep learning