The Problem
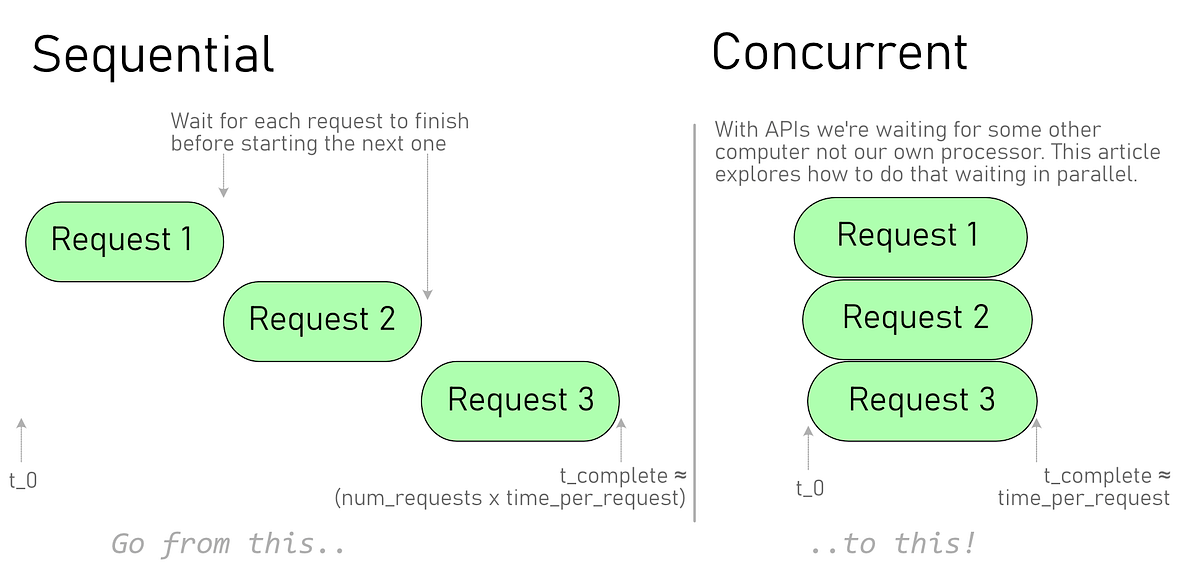
When using APIs most of the time is spent waiting for a response. When collecting information in bulk from an external service this can result in a lot of wasted time. This article explores how to go from sequential requests to concurrent requests using Python’s Multiprocessing, Threading, and **Async **features.
Introduction
In a previous article, we wrote a simple function that worked around the Jira API limit for the number of issues returned by a single query. This solved the problem but even with only a few thousand results the time to retrieve all the issues can creep into being measured in minutes.
_A JQL query returning 1334 issues with 50 issues per request (27 requests) takes __31 seconds. __Using concurrency by changing 7 lines of code, we can reduce this to _2.5 seconds.
**Why?**A quick profile using the built-in %time magic in Jupyter shows why there’s so much room for improvement.
CPU times: user 672 ms, sys: 125 ms, total: 797 ms
Wall time: 31.4 s
Doing the requests sequentially only uses our CPU for 797 milliseconds out of 31.4 seconds of elapsed time. So of the 31 seconds, _more than __97% _of the time is spent waiting for the network call.
#jira #concurrent-programming #api #api-concurrency-python #python