Some of the new reinforcement learning algorithms are using a discounted sum of rewards somewhere in their reward function. I implemented an approach that dramatically decreased training time for my machine learning models.
These implementations include a tf.scan function that loops through every value of the rewards to calculate its discounted sum.
discount_factor = 0.99
discounted_sum_rewards = tf.scan(lambda agg, x: discount_factor * agg + x, rewards, reverse=True)
Although this approach works for smaller batch sizes, I have found that it does not scale well. This is due to the tf.scan function having to go through every value in the rewards array to calculate the discounted sum. Additionally, there are only a finite number of significant figures that can be represented on a computer. Depending on the range of rewards, there may be an opportunity to limit the depth that the discounted rewards will propagate.
The Idea
A value will have a maximum number of bits that can be stored by the computer. Let’s call that n. This means the maximum decimal value, while keeping the exponent at 0, is represented by:
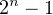
The number of decimal places that this will occupy can be represented by:
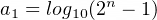
If all our rewards were the same value, then that’s all we would need, but usually this is not the case. For rewards that are different, we will need to make sure the discounted sum propagates further based on the range of rewards. We will apply the same logic as above and look at the differences in magnitude of the maximum and minimum reward. This could be written as:

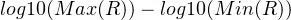
or
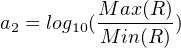
Lastly, we will need to find how many discounts will need to be applied to get that number of decimal places to 1. For example, let’s say we have exactly 8 significant figures, or 10⁸. We would need to reach 10^-8 so that $10⁸ * 10^-8 = 10⁰ = 1. In other words, given a discount of d, we can calculate the number of iterations with:
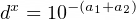
or
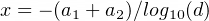
Notice that all the values in the fraction are using log base 10, so the base doesn’t matter.
#python #deep learning