My first education is related to mechanical engineering, and despite my involvement in data science for more than 16 years, many ideas from engineering empower me and drive to make stronger decisions when I work as a data science manager.
I remember my fourth year in university, when our professor ( doctor of science in his 36 ) has been walking slowly over a huge old-fashioned study room with large benches straight from the Harry Potter movie. He was a very concise and good lecturer, that’s why his introduction to the Algorithm of Invention was the brightest course I ever attended and now I’m using it in my everyday data science work. Henceforth I would like to tell you some more about the automation of a data science and how to use it to plan the evolution of ML projects.
As soon as the article is going to be quite long, let me present a short plan:
- First, I will introduce some concepts from general morphological analysis and Zwicky box as most notable concept of this theory
- Then I’m going to present some examples of how Zwicky box can be used in data science, illustrated by winning solutions of well-known Kaggle competitions
- Central part of an article is dedicated to the idea of _ML legacy — _the fact that every model ( especially most popular ) has an enormous layer of rarely revisited concepts, by improving which it’s possible to advance the performance of your models ‘for free’, i.e. without much feature engineering, trial and error, and tuning
- Finally, I will provide specific examples of utilizing legacy as a Zwicky axis and then conclude with thought-provoking things.
Basics of Zwicky box
General Morphological Analysis (GMA) was developed by Fritz Zwicky — the Swiss astrophysicist and aerospace scientist based at the California Institute of Technology (Caltech) — as a method for structuring and investigating the total set of relationships contained in multi-dimensional, non-quantifiable, innovative problem complexes.
Zwicky applied this method to such diverse fields as the classification of astrophysical objects, the development of jet and rocket propulsion systems, and the legal aspects of space travel and colonization. He founded the Society for Morphological Research and enthusiastically advanced the “morphological approach” for some 30 years — between the 1940s until his death in 1974.
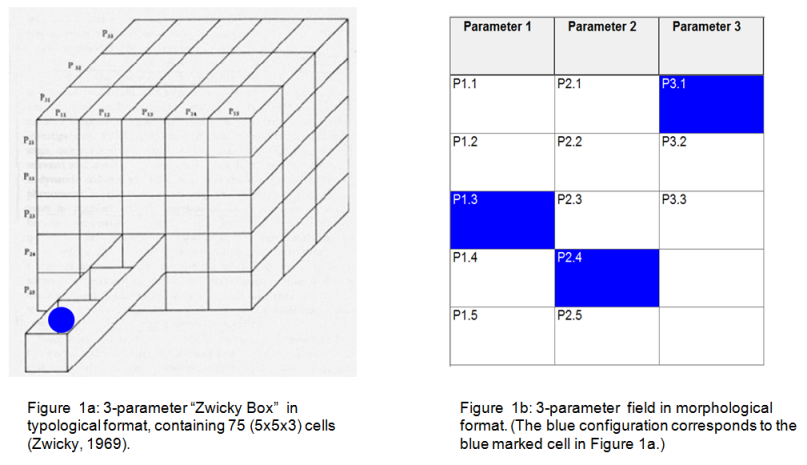
Zwicky box ( shown below on a picture ) is a key concept of general morphology:
Taken from http://www.swemorph.com/pdf/gma.pdf
The approach begins by identifying and defining the parameters (or dimensions) of the problem complex to be investigated, and assigning each parameter a range of relevant “values” or conditions. A morphological box — also fittingly known as a “Zwicky box” — is constructed by setting the parameters against each other in an n-dimensional matrix (see Figure 1a). Each cell of the n-dimensional box contains one particular “value” or condition from each of the parameters, and thus marks out a particular state or configuration of the problem complex.
For example, imagine a simple problem complex, which we define as consisting of three dimensions — let us say “colour”, “texture” and “size”. In order to conform to Figure 1a, let us further define the first two dimensions as consisting of 5 discrete “values” or conditions each (e.g. colour = red, green, blue, yellow, brown) and the third consisting of 3 values (size = large, medium, small). We then have 5x5x3 (= 75) cells in the Zwicky box, each containing 3 conditions — i.e. one from each dimension (e.g. red, rough, large). The entire 3-dimensional matrix is a typological field containing all of the (formally) possible relationships involved.
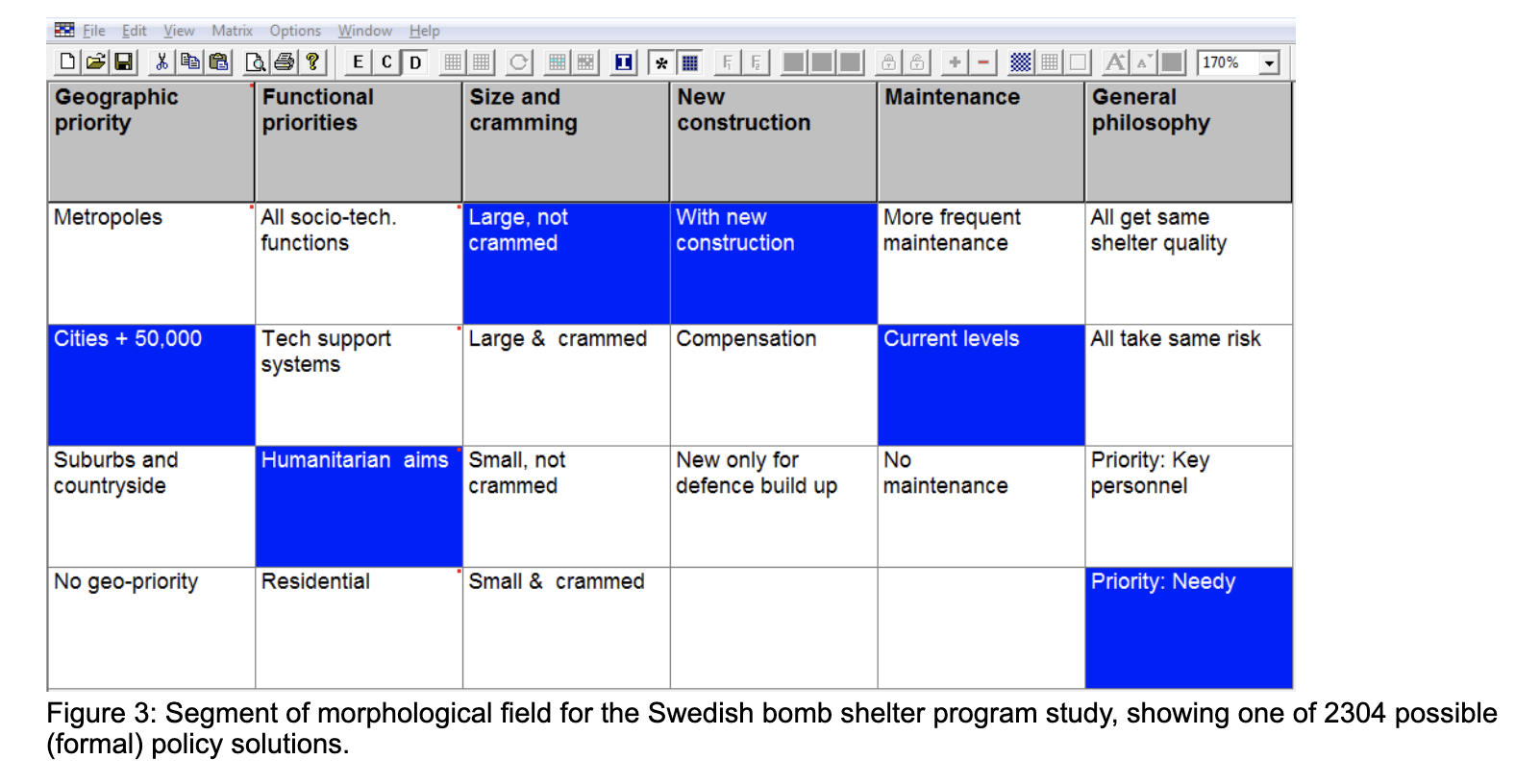
This concrete example utilizes just three dimensions, but in real problems one is free to create as many dimensions and axes as necessary. Have a look at the concrete example from engineering:
Taken from http://www.swemorph.com/ma.html
How to read this table? Grey boxes denote axes, blue boxes indicate one possible choice of requirements for the bomb shelter, in this case, the shelter is supposed to be designed for small cities, with humanitarian aims, large, not crammed, with new construction, no specific requirements for maintenance and priorities for those in need. By selecting different cells we can instantly get some other shelter, very convenient.
Zwicky box in data science
So far so good, but… will it work in data science? For sure yes!
Let’s consider two ML competitions as an illustration. The first one had the objective to identify which E-commerce buyers can be converted to regular loyal buyers to then target them to reduce promotion cost and increase the return on investment (ROI). At International Joint Conferences on Artificial Intelligence (IJCAI) 2015, Alibaba hosted an international competition for recurring buyers prediction based on the sales data of the “Double 11” shopping event in 2014 at Tmall.com. Let’s have a look at the central figure from the paper, outlining the winning solution:
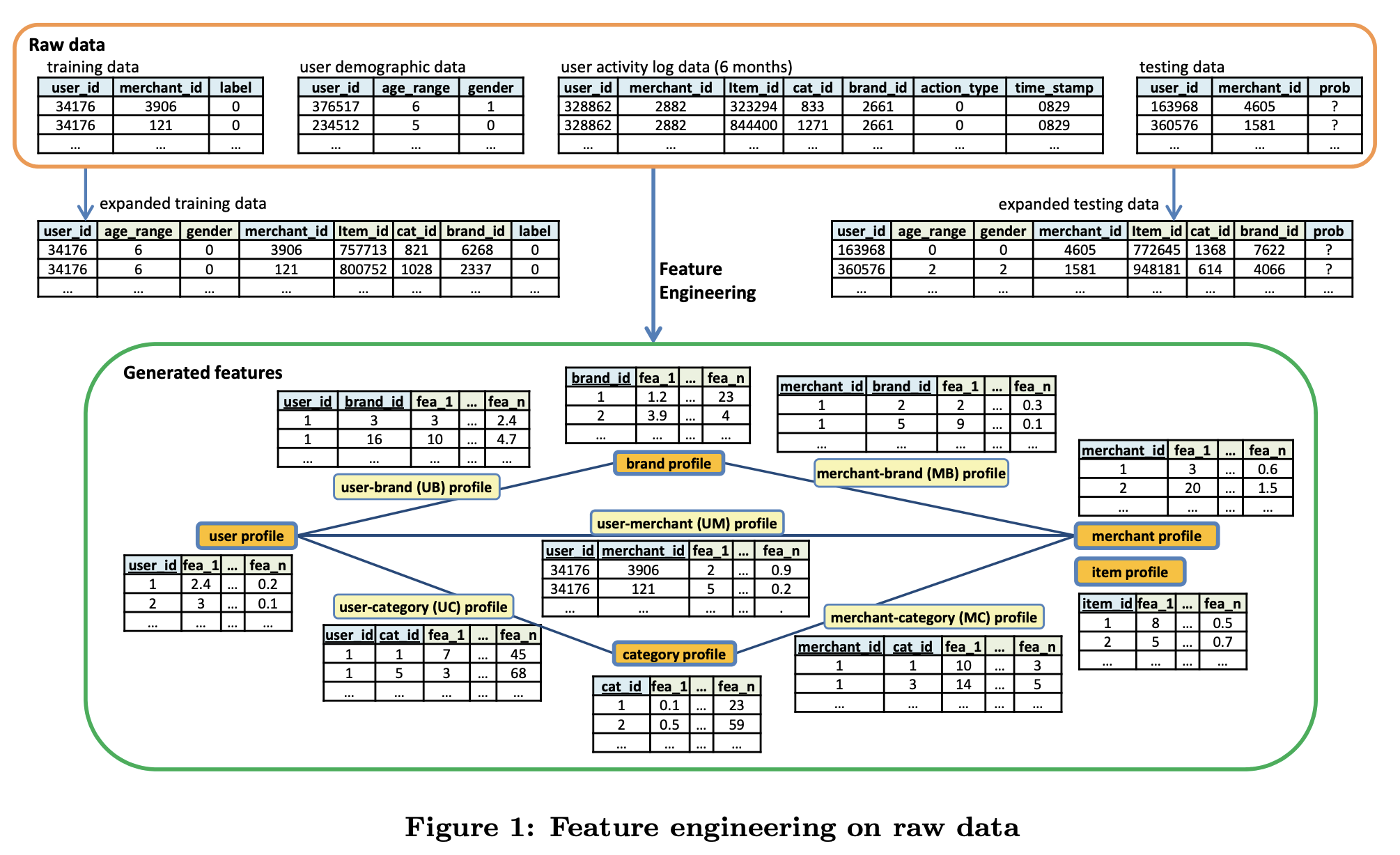
How winners of competition managed to generate lots of features
In their paper authors call Zwicky axes profiles and even apply operators on axes to generate features. Paper proposes _interaction, averaging, diversity, recency, _and many other axes, so to make a clear illustration let‘s consider how Zwicky box can be used to generate features.
Say our axes are _user _and merchant and operator is overall count ( i.e. we count things using whole past data without constraints like past week/day/etc ). Then by applying count operator on user axis we can get these features:

It’s very straightforward to create similar features for merchants ( i.e. merchant and counter are our axes ) :


To implement the _recency _axis we can constrain the count operator by some timeframe ( say, 1 recent week ). Then by combining _user, merchant, _and _recency _axes we can get respective features easily:


By continuing in this way one can get _the idea of _thousands of features in just a few minutes! Obviously not all of them will be equally useful, so feature selection is an important part of ML modelling pipeline, but for beginner data scientists just _generating ideas of features _is something tedious and difficult to manage. Henceforth, it’s very rewarding to automate this process.
And indeed, if these operators above are binary and associative, then by introducing trivial axis ( which simply leaves features as is without generation ) we can even form a Zwicky _monoid _on axes and thus generate features automatically ( see this brilliant post for more details about monoids ). By doing so, authors of a winning solution have created more than 1000 features and overall tested many more.
Another brilliant example of this sort for me is Facebook Missing Link Prediction Challenge. The winning solution used Zwicky box implicitly as well in order to generate features. Here are top features, can you spot Zwicky axes there?
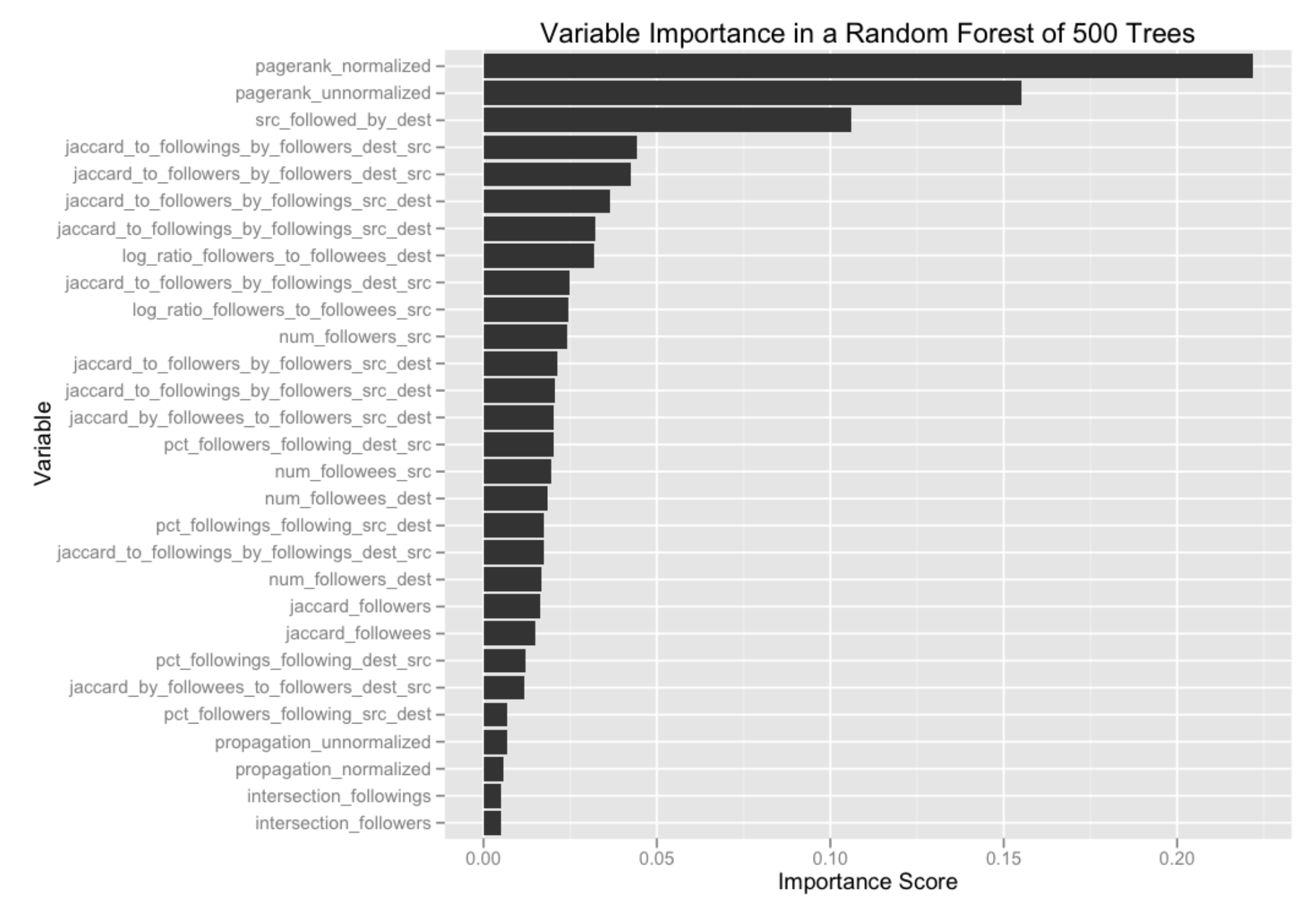
To read a complete story, please read Edwin Chen’s 10 place solution
But is it really just about feature engineering?
For sure no. General morphological analysis is a comprehensive method and “is simply an ordered way of looking at things” ( as Zwicky used to say ), henceforth it can be applied to automate the whole process of creativity and for this reason, it is widespread in engineering, arts and many other areas where creativity is a cornerstone. But let’s define some axes to answer our question constructively. How about legacy as an axis?
Legacy and reusability are the cornerstones of both engineering and data science. Almost all common data scientists call model.fit() without any second thought and with few glitches this behavior won’t deliver any bad scores. But sometimes you simply have to stop and start out of the box thinking, because the pay off can be generous.
A very common managerial decision to pick low hanging fruits is to design the simplest possible model ( linear, kNN or the like ) or even avoid any modeling and try some hand-tuned knobs. But take a careful look: what if you can take way more powerful model currently in production and overhaul it with just one minor modification?
Take a look at this sequence of concepts ( “graph” “random walk”-> “list of visited nodes” -> “word2vec” -> “embeddings” ) and let’s spot small but powerful improvements. Sampling is the first that caught my eye:
#deep-learning #data-science #algorithms
