Background
As a data scientist, you take a business problem and formulate it into a data science problem. Next, you build a solution/model to address the problem. You validate the model with test and out of time data to ensure it is not biased. Finally, you deploy the model in production, monitor the performance of model, conduct experimentations and so on. In addition to these tasks, you present your findings to business stakeholders and sometimes work with them to educate and effectively use your model. Is your job done? Not yet.
The end users of your model might ponder and come up with questions like this— “Why did your model predict this customer as so and so?” or “Could you explain why we get this output from your model?”. Even though you have a proper documentation (assuming you did it), it cannot explain your model predictions on a case by case basis. Consider a scenario where you built a model to classify cats/dogs. Your documentation looks like this.
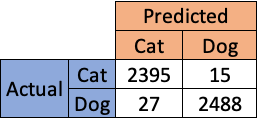
Confusion matrix
Cross entropy
When an end user asks you “Why did your model predict this image as a cat?”

Courtesy: Pixabay
The documentation provided above cannot answer these type of questions. When you have a linear model, you can use the parameter estimates to interpret the results. However, as the model starts getting complex (Black box models like neural network), it gets harder to interpret the results. It becomes an irony in that situation where you need a black box model to get better results but it becomes harder to explain the results. In addition, when you are asked to explain a model that you developed in the past, it takes certain time before you get to the answer. This fundamental drawback is addressed by SHAP (SHapley Additive exPlanations).
#model-interpretability #shap #realtime #docker-compose #streamlit
