In this tutorial, you will learn how to enrich COVID19 tweets data with a positive sentiment score.You will leverage PySpark and Cognitive Services and learn about Augmented Analytics.
What Is Augmented Analytics?
According to Gartner’s report, augmented analytics is the use of technologies such as machine learning and AI to assist with data preparation, insight generation. Its main goal is to help more people to get value out of data and generate insights in an easy, conversational manner. For our example, we extract the positive sentiment score out of a tweet to help in understanding the overall sentiment towards COVID-19.
What Is PySpark?
PySpark is the framework we use to work with Apache Spark and Python. Learn more about it here.
What Is Sentiment Analysis?
Sentiment Analysis is part of NLP - natural language processing usage that combined text analytics, computation linguistics, and more to systematically study affective states and subjective information, such as tweets. In our example, we will see how we can extract positive sentiment score out of COVID-19 tweets text. In this tutorial, you are going to leverage Azure Cognitive Service, which gives us Sentiment Analysis capabilities out of the box. When working with it, we can leverage the TextAnalyticsClient client library or leverage REST API. Today, you will use the REST API as it gives us more flexibility.
Prerequisites
- Apache Spark environment with notebooks, it can be Databricks, or you can start a local environment with docker by running the next command:
docker run -it -p 8888:8888 jupyter/pyspark-notebook - Azure free account
- Download Kaggle COVID-19 Tweet data
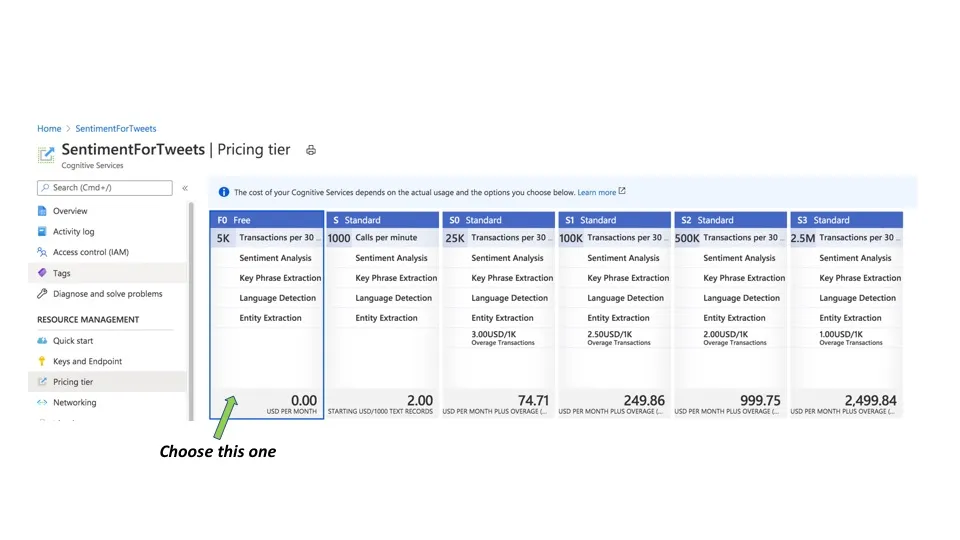
- Cognitive Services free account (check out the picture below )
Step by Step Tutorial — Full Data Pipeline:
In this step by step tutorial, you will learn how to load the data with PySpark, create a user define a function to connect to Sentiment Analytics API, add the sentiment data and save everything to the Parquet format files.
You now need to extract upload the data to your Apache Spark environment, rather it’s Databricks or PySpark jupyter notebook. For Databricks use this, for juypter use this.
For both cases, you will need the file_location = "/FileStore/tables/covid19_tweets.csv" make sure to keep a note of it.
#python #augmented analytics #pyspark #sentiment-analysis