TF-IDF is a simple twist in the bag of words approach. Bag of words just means (## times word w appears in a document d).
TF-IDF stands for term frequency times inverse document frequency.
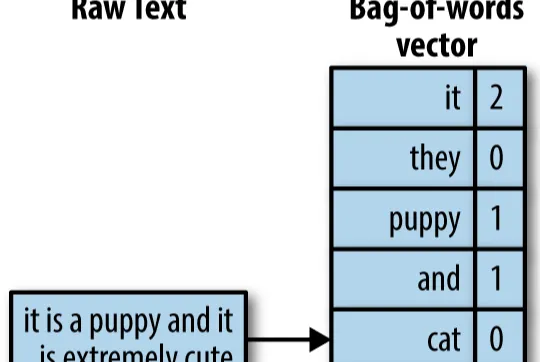
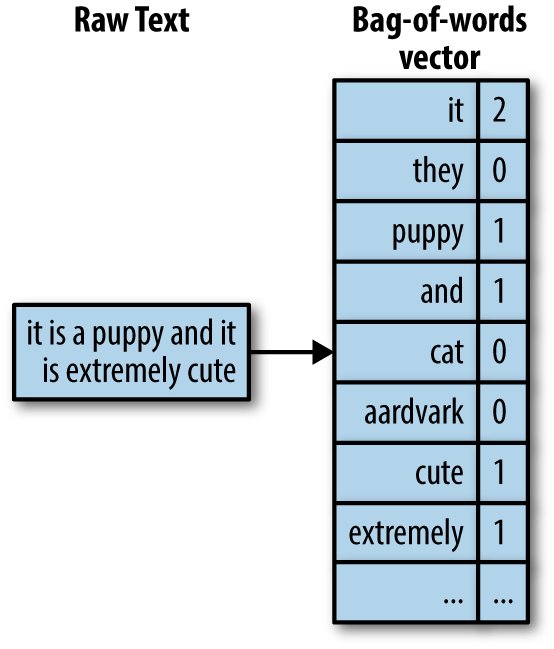
Below image talks about bag of words approach to encode text data numerically to work with text data in machine learning setting.
Here in below example the word “puppy” occurs exactly once in the text so in bag of words vector puppy has value one, it basically says that the word count of puppy in this document is one and there are many documents in real word so this vector would look like a matrix where each row is a document and matrix is a collection of document where columns represent a specific word count.
Why do we need tf-idf when we already have bag of words representation of text?
Bag of words is a simple representation of text data but is far from perfect.
If we count all equally, then some words end up being emphasized more than others.
#tf-idf #bag-of-words #natural-language-process #machine-learning #sklearn #deep learning