Playing Beat Saber in the browser with body movements using PoseNet & Tensorflow.js
I haven’t played many VR games because I don’t own gears but one that I tried and loved was Beat Saber.
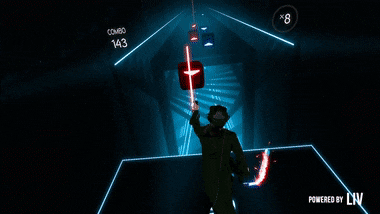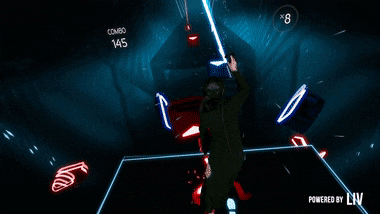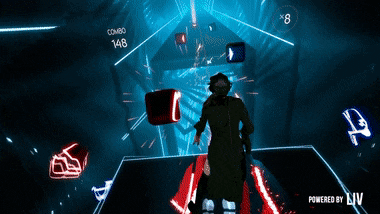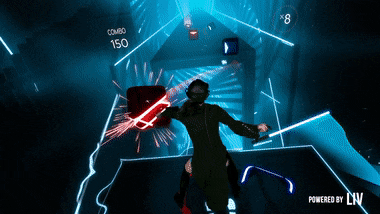
If you’re not familiar with it, it is this Tron-looking game where you use your controllers to hit “beats” to the rhythm of a song. It’s really a lot of fun but it requires you to have either an HTC Vive, an Oculus Rift or a Playstation VR.
These consoles can be expensive, hence, not accessible to everyone.
A few months ago, I came across this repo by Supermedium. It’s a clone of Beat Saber made with web technologies, using A-Frame and I found it really impressed!
You can start playing a song, see the beats being generated, look around the scene but it didn’t look like you could play, or at least, again, not if you don’t have any VR device.
I really wanted to see if I could do something about it, so I decided to add PoseNet, a pose detection model with Tensorflow.js, to be able to play this game in the browser with my hands… and IT WORKS!! 🤩🎉
Ok, it’s not as performant because the tracking of the camera is not as accurate as using joysticks, but to be honest, my main goal was to see if it was possible.
I’m super happy it works and the “only” thing people need is a (modern) laptop!
The end result looks like this:

If you’re not interested in the details of how it was built, you can just check out the live demo or you can find all the code in the Github repo.
Otherwise, now that you’re hopefully as excited about this as I am, let’s talk about how it works!
Step1. Reverse engineering
Most of the codebase relies on the BeatSaver Viewer open-source project.
Usually, in my side projects, I start everything from scratch. I know exactly where things are and it makes it easy for me to make changes fast. However, in this case, the idea came from finding the existing repo of BeatSaver so I started from their codebase. It would have been useless to spend time recreating the game when other people have already done such an awesome job.
I quickly ran into some issues though. I didn’t really know where to start. If you inspect a 3D scene in the browser with the normal dev tools, to try and figure out which component you should be changing, the only thing you’re going to get is… the canvas; you’re not gonna be able to inspect the different 3D elements inside the scene.
With A-Frame, you can use CTRL + Option + i to toggle the inspector, but it still didn’t help me find the element I was looking for.
What I had to do instead is dive deep into the codebase and try to figure out what was going on. I didn’t have that much experience with A-Frame so I was a bit confused about the name of some mixins, where some components were coming from, how they were rendered in the scene, etc…
In the end, I found the beat component I was looking for that had a destroyBeat method, so that looked promising!
Just to test that I found what I needed, I made a quick change in the beat component to trigger the destroyBeat function every time I click on the body of the page, so something that looks like this:
document.body.onclick = () => this.destroyBeat();
After reloading the page, I started the game, waited for a beat to be displayed, clicked anywhere on the body and saw the beat explode. That was a good first step!
Now that I had a better idea of where to make changes in the code, I started looking into playing with PoseNet to see what kind of data I would be able to use.
Step 2. Body tracking with the PoseNet model
The PoseNet model with Tensorflow.js allows you to do pose estimation in the browser and get back information about a few “keypoints” like the position of shoulders, arms, wrists, etc…
Before implementing it into the game, I tested it separately to see how it worked.
A basic implementation would look like this:
In an HTML file, start by importing Tensorflow.js and the PoseNet model:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/posenet"></script>
We can also display the webcam feed and markers on the body parts we are tracking, in my case, the wrists.
To do so, we start by adding a video tag and a canvas that will be placed above the video:
<video id="video" playsinline style=" -moz-transform: scaleX(-1);
-o-transform: scaleX(-1);
-webkit-transform: scaleX(-1);
transform: scaleX(-1);
">
</video>
<canvas id="output" style="position: absolute; top: 0; left: 0; z-index: 1;"></canvas>
The JavaScript part of the pose detection involves a few steps.
First, we need to set up PoseNet.
// We create an object with the parameters that we want for the model.
const poseNetState = {
algorithm: 'single-pose',
input: {
architecture: 'MobileNetV1',
outputStride: 16,
inputResolution: 513,
multiplier: 0.75,
quantBytes: 2
},
singlePoseDetection: {
minPoseConfidence: 0.1,
minPartConfidence: 0.5,
},
output: {
showVideo: true,
showPoints: true,
},
};
// We load the model.
let poseNetModel = await posenet.load({
architecture: poseNetState.input.architecture,
outputStride: poseNetState.input.outputStride,
inputResolution: poseNetState.input.inputResolution,
multiplier: poseNetState.input.multiplier,
quantBytes: poseNetState.input.quantBytes
});
When the model is loaded, we instantiate a video stream:
let video;
try {
video = await setupCamera();
video.play();
} catch (e) {
throw e;
}
async function setupCamera() {
const video = document.getElementById('video');
video.width = videoWidth;
video.height = videoHeight;
const stream = await navigator.mediaDevices.getUserMedia({
'audio': false,
'video': {
width: videoWidth,
height: videoHeight,
},
});
video.srcObject = stream;
return new Promise((resolve) => {
video.onloadedmetadata = () => resolve(video);
});
}
Once the video stream is ready, we start detecting poses:
function detectPoseInRealTime(video) {
const canvas = document.getElementById('output');
const ctx = canvas.getContext('2d');
const flipPoseHorizontal = true;
canvas.width = videoWidth;
canvas.height = videoHeight;
async function poseDetectionFrame() {
let poses = [];
let minPoseConfidence;
let minPartConfidence;
switch (poseNetState.algorithm) {
case 'single-pose':
const pose = await poseNetModel.estimatePoses(video, {
flipHorizontal: flipPoseHorizontal,
decodingMethod: 'single-person'
});
poses = poses.concat(pose);
minPoseConfidence = +poseNetState.singlePoseDetection.minPoseConfidence;
minPartConfidence = +poseNetState.singlePoseDetection.minPartConfidence;
break;
}
ctx.clearRect(0, 0, videoWidth, videoHeight);
if (poseNetState.output.showVideo) {
ctx.save();
ctx.scale(-1, 1);
ctx.translate(-videoWidth, 0);
ctx.restore();
}
poses.forEach(({score, keypoints}) => {
if (score >= minPoseConfidence) {
if (poseNetState.output.showPoints) {
drawKeypoints(keypoints, minPartConfidence, ctx);
}
}
});
requestAnimationFrame(poseDetectionFrame);
}
poseDetectionFrame();
}
In the sample above, we call the drawKeypoints function to draw the dots over the hands on the canvas. The code for this is:
function drawKeypoints(keypoints, minConfidence, ctx, scale = 1) {
let leftWrist = keypoints.find(point => point.part === 'leftWrist');
let rightWrist = keypoints.find(point => point.part === 'rightWrist');
if (leftWrist.score > minConfidence) {
const {y, x} = leftWrist.position;
drawPoint(ctx, y * scale, x * scale, 10, colorLeft);
}
if (rightWrist.score > minConfidence) {
const {y, x} = rightWrist.position;
drawPoint(ctx, y * scale, x * scale, 10, colorRight);
}
}
function drawPoint(ctx, y, x, r, color) {
ctx.beginPath();
ctx.arc(x, y, r, 0, 2 * Math.PI);
ctx.fillStyle = color;
ctx.fill();
}
And here’s the result:

Now that the tracking works on its own, let’s move on to adding this in the BeatSaver codebase.
Step 3. Adding the pose tracking to BeatSaver
To start adding our pose detection to the 3D game, we need to take the code we wrote above and implement it inside the BeatSaver code.
All we have to do is add our video tag to the main HTML file and create a new JS file that we import at the top of it, that contains our JS code above.
At this stage, we should get something like this:

That’s a good first step, but we’re not quite there yet. Now, we’re starting to enter the parts of this project that become more tricky. The tracking of the position with PoseNet is in 2D whereas the A-Frame game is in 3D, so our blue and red dots from the hand tracking are not actually added to the scene. However, to be able to destroy beats, we need everything to be part of the game.
To do this, we need to switch from displaying the hands as circles on a canvas, to creating actual 3D objects that we need to place at the correct coordinates, but it’s not that simple…
The way coordinates work in these environments is different.The (x,y) coordinate of your left hand on the canvas does not translate to the same (x,y) coordinate of an object in 3D.
Therefore, the next step is to find a way to map positions between our 2D and 3D world.
Mapping 2D & 3D coordinates
As said above, coordinates in a 2D and 3D world work differently.
Before being able to map them, we need to create a new 3D object that is going to represent our hand in the game.
In A-frame, we can create what is called an entity component, a custom placeholder object that we can add to our scene.
1. Creating a custom 3D object
In our case, we want to create a simple cube and we can do it like this:
let el, self;
AFRAME.registerComponent('right-hand-controller', {
schema: {
width: {type: 'number', default: 1},
height: {type: 'number', default: 1},
depth: {type: 'number', default: 1},
color: {type: 'color', default: '#AAA'},
},
init: function () {
var data = this.data;
el = this.el;
self = this;
this.geometry = new THREE.BoxGeometry(data.width, data.height, data.depth);
this.material = new THREE.MeshStandardMaterial({color: data.color});
this.mesh = new THREE.Mesh(this.geometry, this.material);
el.setObject3D('mesh', this.mesh);
}
});
Then, to be able to see our custom entity on the screen, we need to import this file in our HTML, and use the a-entity tag.
<a-entity id="right-hand" right-hand-controller="width: 0.1; height: 0.1; depth: 0.1; color: #036657" position="1 1 -0.2"></a-entity>
In the code above, we create a new entity of type right-hand-controller and we give it a few properties.
Now we should see a cube on the page.

To change its position, we can use the data we get from PoseNet. In our entity component, we need to add a few functions:
// this function runs when the component is initialised AND when a property updates.
update: function(){
this.checkHands();
},
checkHands: function getHandsPosition() {
// if we get the right hand position from PoseNet and it's different from the previous one, trigger the `onHandMove` function.
if(rightHandPosition && rightHandPosition !== previousRightHandPosition){
self.onHandMove();
previousRightHandPosition = rightHandPosition;
}
window.requestAnimationFrame(getHandsPosition);
},
onHandMove: function(){
//First, we create a 3-dimensional vector to hold the values of our PoseNet hand detection, mapped to the dimension of the screen.
const handVector = new THREE.Vector3();
handVector.x = (rightHandPosition.x / window.innerWidth) * 2 - 1;
handVector.y = - (rightHandPosition.y / window.innerHeight) * 2 + 1;
handVector.z = 0; // that z value can be set to 0 because we don't get depth from the webcam.
// We get the camera element and 'unproject' our hand vector with the camera's projection matrix (some magic I can't explain).
const camera = self.el.sceneEl.camera;
handVector.unproject(camera);
// We get the position of our camera object.
const cameraObjectPosition = camera.el.object3D.position;
// The next 3 lines are what allows us to map between the position of our hand on the screen to a position in the 3D world.
const dir = handVector.sub(cameraObjectPosition).normalize();
const distance = - cameraObjectPosition.z / dir.z;
const pos = cameraObjectPosition.clone().add(dir.multiplyScalar(distance));
// We use this new position to determine the position of our 'right-hand-controller' cube in the 3D scene.
el.object3D.position.copy(pos);
el.object3D.position.z = -0.2;
}
At this stage, we are able to move our hand in front of the camera and see the 3D cube moving.

The final thing we need to do is what is called Raycasting to be able to destroy the beats.
Raycasting
In Three.js, Raycasting is usually used for mouse picking, meaning figuring out what objects in the 3D space the mouse is over. It can be used for collision detection.
In our case, it’s not the mouse that we care about, but our “cube hands”.
To check which objects our hands are over, we need to add the following code in our onMoveHands function:
// Create a raycaster with our hand vector.
const raycaster = new THREE.Raycaster();
raycaster.setFromCamera(handVector, camera);
// Get all the <a-entity beatObject> elements.
const entities = document.querySelectorAll('[beatObject]');
const entitiesObjects = [];
if(Array.from(entities).length){
// If there are beats entities, get the actual beat mesh and push it into an array.
for(var i = 0; i < Array.from(entities).length; i++){
const beatMesh = entities[i].object3D.el.object3D.el.object3D.el.object3D.children[0].children[1];
entitiesObjects.push(beatMesh);
}
// From the raycaster, check if we intersect with any beat mesh.
let intersects = raycaster.intersectObjects(entitiesObjects, true);
if(intersects.length){
// If we collide, get the entity, its color and type.
const beat = intersects[0].object.el.attributes[0].ownerElement.parentEl.components.beat;
const beatColor = beat.attrValue.color;
const beatType = beat.attrValue.type;
// If the beat is blue and not a mine, destroy it!
if(beatColor === "blue"){
if(beatType === "arrow" || beatType === "dot"){
beat.destroyBeat();
}
}
}
}
And we’re done!!
We used PoseNet and Tensorflow.js to detect hands and their position, we drew them on a canvas, we mapped them to 3D coordinates and we used a Raycaster to detect collision with beats and destroy them! 🎉 🎉 🎉
It definitely took me a few more steps to figure all of this out but it was a very interesting challenge!
Limits
Of course, as always, there are limits that need to be mentioned.
Latency & accuracy
If you’ve tried the demo, you would have probably noticed some latency between the moment you move your hand and when it is reflected on the screen.
In my opinion, that’s expected, but I’m actually quite impressed with how fast it can recognise my wrists and calculate where they should be placed on the screen.
Lighting
I think commonly with computer vision, any experience you build will not be very performant or usable if the lighting in the room is not good enough. It’s only using the stream from the webcam to find what’s closest to a body shape so if the amount of light is insufficient, it won’t be able to do that and the game will not work.
User Experience
In the real Beat Saber game, I believe the joysticks react to the collision with a beat? If it doesn’t, it really should, so the user can get some haptic feedback about what happened.
In this particular project however, the feedback is only visual, which in a way, feels a little weird, you’d want to “feel” the explosion of beats when you hit them.
It could be fixed with connecting some Arduino and vibration sensors via Web bluetooth but that’s for another day… 😂
That’s pretty much it!
Hope you like it! ❤️✌️
#tensorflow #machine-learning
