The DataFrame API of Spark SQL is user friendly because it allows expressing even quite complex transformations in high-level terms. It is quite rich and mature especially now in Spark 3.0. There are however some situations in which you might find its behavior unexpected or at least not very intuitive. This might get frustrating especially if you find out that your production pipeline produced results that you didn’t expect.
In this article, we will go over some features of Spark which are not so obvious at first sight, and by knowing them you can avoid silly mistakes. In some examples, we will also see nice optimization tricks that can become handy depending on your transformations. For the code examples, we will use Python API in Spark 3.0.
8 non-obvious features in Spark SQL that are worth knowing.
- What is the difference between array_sort and sort_array?
- concat function is null-intolerant
- collect_list is not a deterministic function
- Sorting the window will change the frame
- Writing to a table invalidates the cache
- Why does calling show() run multiple jobs?
- How to make sure a User Defined Function is executed only once?
- UDF can destroy your data distribution
1. What is the difference between array_sort and sort_array?
Both of these two functions can be used for sorting the arrays, however, there is a difference in usage and null handling. While array_sort can only sort your data in ascending order, the sort_array takes a second argument in which you can specify whether your data should be sorted in descending or ascending order. The array_sort will place null elements at the end of the array which will also sort_array do when sorting in descending order. But when using sort_array in ascending (default) order the null elements will be placed at the beginning.
l = [(1, [2, None, 3, 1])]
df = spark.createDataFrame(l, ['id', 'my_arr'])
(
df
.withColumn('my_arr_v2', array_sort('my_arr'))
.withColumn('my_arr_v3', sort_array('my_arr'))
.withColumn('my_arr_v4', sort_array('my_arr', asc=False))
.withColumn('my_arr_v5', reverse(array_sort('my_arr')))
).show()
+---+----------+----------+-----------+----------+-----------+
| id| my_arr| my_arr_v2| my_arr_v3| my_arr_v4| my_arr_v5|
+---+----------+----------+-----------+----------+-----------+
| 1|[2,, 3, 1]|[1, 2, 3,]|[, 1, 2, 3]|[3, 2, 1,]|[, 3, 2, 1]|
+---+----------+----------+-----------+----------+-----------+
And there is one more option on how to use the function array_sort, namely directly in SQL (or as a SQL expression as argument of the expr() function) where it takes a second argument which is a comparator function (supported since Spark 3.0). With this function, you can define how the elements should be compared to create the order. This actually brings quite powerful flexibility by which you can for example sort an array of structs and define by which struct field it should be sorted. Le’ts see this example where we sort explicitly by the second struct field:
schema = StructType([
StructField('arr', ArrayType(StructType([
StructField('f1', LongType()),
StructField('f2', StringType())
])))
])
l = [(1, [(4, 'b'), (1, 'c'), (2, 'a')])]
df = spark.createDataFrame(l, schema=schema)
(
df
.withColumn('arr_v1', array_sort('arr'))
.withColumn('arr_v2', expr(
"array_sort(arr, (left, right) -> case when left.f2 < right.f2 then -1 when left.f2 > right.f2 then 1 else 0 end)"))
).show(truncate=False)

Here you can see that the comparison function expressed in SQL takes two arguments left and right which are elements of the array and it defines how they should be compared (namely according to the second field f2).
2. concat function is null-intolerant
The concat function can be used for concatenating strings, but also for joining arrays. The less obvious thing is that the function is null-intolerant, which means that if any argument is null, then also the output becomes null. So for example when joining two arrays, we can easily lose the data from one array if the other one is null unless we handle it explicitly, for instance, by using coalesce:
from pyspark.sql.types import *
from pyspark.sql.functions import concat, coalesce, array
schema = StructType([
StructField('id', LongType()),
StructField('arr_1', ArrayType(StringType())),
StructField('arr_2', ArrayType(StringType()))
])
l = [(1, ['a', 'b', 'c'], None)]
df = spark.createDataFrame(l, schema=schema)
(
df
.withColumn('combined_v1', concat('arr_1', 'arr_2'))
.withColumn('combined_v2', concat(coalesce('arr_1'), array(), coalesce('arr_2', array())))
).show()
+---+---------+-----+-----------+-----------+
| id| arr_1|arr_2|combined_v1|combined_v2|
+---+---------+-----+-----------+-----------+
| 1|[a, b, c]| null| null| [a, b, c]|
+---+---------+-----+-----------+-----------+
3. collect_list is not a deterministic function
Aggregation function collect_list which can be used to create an array of elements after grouping by some key is not deterministic because the order of elements in the resulting array depends on the order of rows which may not be deterministic after the shuffle.
It is also good to know that non-deterministic functions are treated with special care by the optimizer, for example, the optimizer will not push filters through it as you can see in the following query:
(
df.groupBy('user_id')
.agg(collect_list('question_id'))
.filter(col('user_id').isNotNull())
).explain()
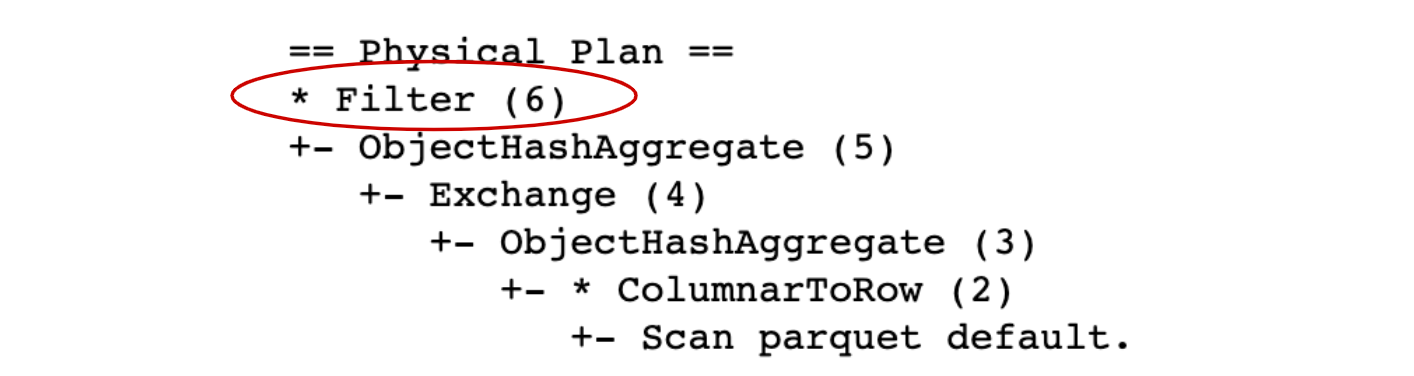
As you can see from the plan, the Filter is the last transformation, so Spark will first compute the aggregation and after that, it will filter out some groups (here we filter out group where user_id is null). It would be however more efficient if the data was first reduced by the filter and then aggregated which will indeed happen with deterministic functions such as count:
(
df.groupBy('user_id')
.agg(count('*'))
.filter(col('user_id').isNotNull())
).explain()

Here the Filter was pushed closer to the source because the aggregation function count is deterministic.
Besides collect_list, there are also other non-deterministic functions, for example, collect_set, first, last, input_file_name, spark_partition_id, or rand to name some.
#data-science #python #sql #spark #developer
