In this part, we will build different models, validate them, and use the grid search approach to find out the optimum hyperparameters. This post is the second part of part1. You can find the jupyter notebook file of this part here.
The concept of model building in ML projects of scikit-learn libraries is simple. First, you select what type of model you are comfortable with, second, fit the model to the data using target and predictors(features), and finally, predict the unknown labels using available feature data.
In this project, we will use these classifiers to fit the feature data and then predict the facies classes. Here, we will not go into these algorithms’ basic concepts. You may study on the scikit-learn website.
1 — Logistic Regression Classifier
2 — K Neighbors Classifier
3 — Decision Tree Classifier
4 — Random Forest Classifier
5 — Support Vector Classifier
6 — Gaussian Naive Bayes Classifier
7 — Gradient Boosting Classifier
8 — Extra Tree Classifier
2–1 Baseline Model
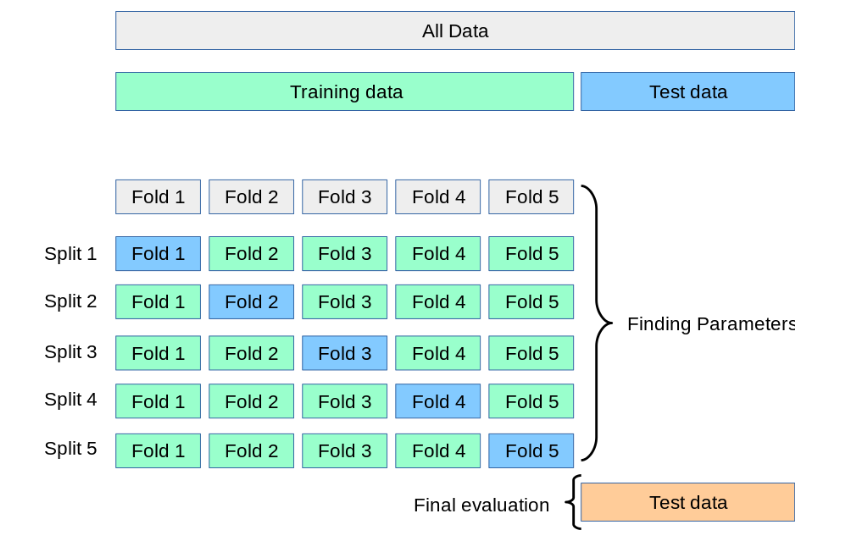
The philosophy of constructing a baseline model is simple: we need a basic and simple model to see how the adjustments on both data and model parameters can cause improvement in model performance. In fact, this is like a scale for comparison.
In this code script, we first defined our favorite model classifiers. Then, established baseline_model function. In this function, we employed the Pipeline function to implement step wised operation of data standard scaling(facilitate model running more efficient) and model object calling for cross-validation. I like Pipeline because it makes the codes more tidy and readable.
#model-validation #multiclass-classification #python #machine-learning #facies