Right now, Apache Kafka utilizes Apache ZooKeeper to store its metadata. Information such as the partitions, configuration of topics, access control lists, etc. metadata stored in a ZooKeeper cluster. Managing a ZooKeeper cluster creates an additional burden on the infrastructure and the admins. With KIP-500, we are going to see a Kafka cluster without the ZooKeeper cluster where the metadata management will be done with Kafka itself.
Before KIP-500, our Kafka setup looks like depicted below. Here we have a 3 node ZooKeeper cluster and a 4 node Kafka cluster. This setup is a minimum for sustaining 1 Kafka broker failure. The orange Kafka node is a controller node.
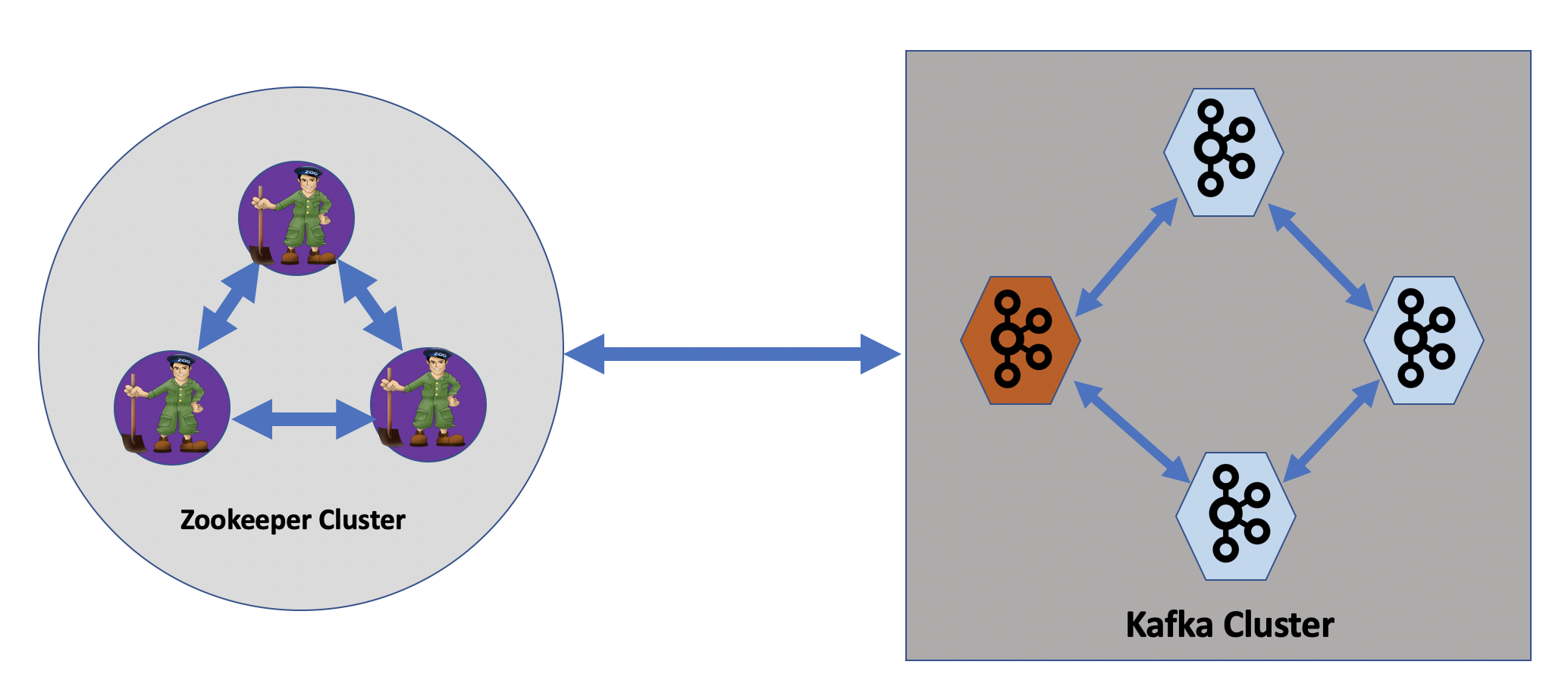
Let’s see what issues we have with the above setup with the involvement of ZooKeeper:
- Making the ZooKeeper cluster highly available is an issue as without the ZooKeeper cluster the Kafka cluster is DEAD.
- Availability of the Kafka cluster if the controller dies. Electing another Kafka broker as a controller requires pulling the metadata from the ZooKeeper which leads to the Kafka cluster unavailability. If the number of topics and the partitions is more per topic, the failover Kafka controller time increases.
- Kafka supports intra-cluster replication to support higher availability and durability. There should be multiple replicas of a partition, each stored in a different broker. One of the replicas is designated as a leader and the rest of the replicas are followers. If a broker fails, partitions on that broker with a leader temporarily become inaccessible. To continue serving the client requests, Kafka will automatically transfer the leader of those inaccessible partitions to some other replicas. This process is done by the Kafka broker who is acting as a controller. The controller broker should get metadata from the ZooKeeper for each of the affected partitions. The communication between the controller broker and the ZooKeeper happens in a serial manner which leads to unavailability of the partition if the leader broker dies.
- When we delete or create a topic, the Kafka cluster needs to talk to ZooKeeper to get the updated list of topics. To see the impact of topic deletion or creation with the Kafka cluster will take time.
- The major issue we see is the SCALABILITY issue.
#kafka
